

DETR (Detection Transformer) is a deep studying structure first proposed as a brand new strategy to object detection. It is the primary object detection framework to efficiently combine transformers as a central constructing block within the detection pipeline.
DETR fully modifications the structure in contrast with earlier object detection methods. On this article, we delve into the idea of Detection Transformer (DETR), a groundbreaking strategy to object detection.
What’s Object Detection?
In line with Wikipedia, object detection is a pc expertise associated to pc imaginative and prescient and picture processing that detects cases of semantic objects of a selected class (comparable to people, buildings, or vehicles) in digital photographs and movies.
It is utilized in self-driving vehicles to assist the automobile detect lanes, different autos, and folks strolling. Object detection additionally helps with video surveillance and with picture search. The thing detection algorithms use machine studying and deep studying to detect the objects. These are superior methods for computer systems to study independently primarily based on taking a look at many pattern photographs and movies.
How Does Object Detection Work
Object detection works by figuring out and finding objects inside a picture or video. The method includes the next steps:

- Function Extraction: Extracting options is step one in object detection. This normally includes coaching a convolutional neural community (CNN) to acknowledge picture patterns.
- Object Proposal Era: After getting the options, the following factor is to generate object proposals – areas within the picture that would comprise an object. Selective search is often used to pump out many potential object proposals.
- Object Classification: The subsequent step is to categorise the thing proposals as both containing an object of curiosity or not. That is sometimes carried out utilizing a machine studying algorithm comparable to a assist vector machine (SVM).
- Bounding Field Regression: With the proposals labeled, we have to refine the bounding bins across the objects of curiosity to nail their location and measurement. That bounding field regression adjusts the bins to envelop the goal objects.
DETR: A Transformer-Primarily based Revolution
DETR (Detection Transformer) is a deep studying structure proposed as a brand new strategy to object detection and panoptic segmentation. DETR is a groundbreaking strategy to object detection that has a number of distinctive options.
Finish-to-Finish Deep Studying Answer
DETR is an end-to-end trainable deep studying structure for object detection that makes use of a transformer block. The mannequin inputs a picture and outputs a set of bounding bins and sophistication labels for every object question. It replaces the messy pipeline of hand-designed items with a single end-to-end neural community. This makes the entire course of extra simple and simpler to know.
Streamlined Detection Pipeline
DETR (Detection Transformer) is particular primarily as a result of it totally depends on transformers with out utilizing some normal elements in conventional detectors, comparable to anchor bins and Non-Most Suppression (NMS).
In conventional object detection fashions like YOLO and Quicker R-CNN, anchor bins play a pivotal position. These fashions must predefine a set of anchor bins, which symbolize quite a lot of shapes and scales that an object might have within the picture. The mannequin then learns to regulate these anchors to match the precise object bounding bins.
The utilization of those anchor bins considerably improves the fashions’ accuracy, particularly in detecting small-scale objects. Nonetheless, the vital caveat right here is that the scale and scale of those bins should be fine-tuned manually, making it a considerably heuristic course of that may very well be higher.
Equally, NMS is one other hand-engineered element utilized in YOLO and Quicker R-CNN. It is a post-processing step to make sure that every object will get detected solely as soon as by eliminating weaker overlapping detections. Whereas it is necessary for these fashions because of the follow of predicting a number of bounding bins round a single object, it may additionally trigger some points. Choosing thresholds for NMS isn’t simple and will affect the ultimate detection efficiency. The standard object detection course of might be visualized within the picture under:

However, DETR eliminates the necessity for anchor bins, managing to detect objects instantly with a set-based world loss. All objects are detected in parallel, simplifying the educational and inference course of. This strategy reduces the necessity for task-specific engineering, thereby lowering the detection pipeline’s complexity.
As a substitute of counting on NMS to prune a number of detections, it makes use of a transformer to foretell a set variety of detections in parallel. It applies a set prediction loss to make sure every object will get detected solely as soon as. This strategy successfully suppresses the necessity for NMS. We are able to visualize the method within the picture under:

The shortage of anchor bins simplifies the mannequin however may additionally scale back its capability to detect small objects as a result of it can not deal with particular scales or ratios. Nonetheless, eradicating NMS prevents the potential mishaps that would happen by way of improper thresholding. It additionally makes DETR extra simply end-to-end trainable, thus enhancing its effectivity.
Novel Structure and Potential Purposes
One factor about DETR is that its construction with consideration mechanisms makes the fashions extra comprehensible. We are able to simply see what elements of a picture deal with, when it makes a prediction. It not solely enhances accuracy but additionally aids in understanding the underlying mechanisms of those pc imaginative and prescient fashions.
This understanding is essential for bettering the fashions and figuring out potential biases. DETR broke new floor in taking transformers from NLP into the imaginative and prescient world, and its interpretable predictions are a pleasant bonus from the eye strategy. The distinctive construction of DETR has a number of real-world purposes the place it has proved to be useful:
- Autonomous Autos: DETR’s end-to-end design means it may be educated with a lot much less handbook engineering, which is a superb boon for the autonomous autos business. It makes use of the transformer encoder-decoder structure that inherently fashions object relations within the picture. This may end up in higher real-time detection and identification of objects like pedestrians, different autos, indicators, and many others., which is essential within the autonomous autos scene.
- Retail Trade: DETR might be successfully utilized in real-time stock administration and surveillance. Its set-based loss prediction can present a fixed-size, unordered set of forecasts, making it appropriate for a retail surroundings the place the variety of objects may fluctuate.
- Medical Imaging: DETR’s capability to establish variable cases in photographs makes it helpful in medical imaging for detecting anomalies or illnesses. As a consequence of their anchoring and bounding field strategy, Conventional fashions usually wrestle to detect a number of cases of the identical anomaly or barely completely different anomalies in the identical picture. DETR, however, can successfully deal with these situations.
- Home Robots: It may be used successfully in home robots to know and work together with the surroundings. Given the unpredictable nature of home environments, the power of DETR to establish arbitrary numbers of objects makes these robots extra environment friendly.
Set-Primarily based Loss in DETR for Correct and Dependable Object Detection
DETR makes use of a set-based general loss operate that compels distinctive predictions by way of bipartite matching, a particular facet of DETR. This distinctive function of DETR helps be sure that the mannequin produces correct and dependable predictions. The set-based whole loss matches the expected bounding bins with the bottom reality bins. This loss operate ensures that every predicted bounding field is matched with just one floor reality bounding field and vice versa.
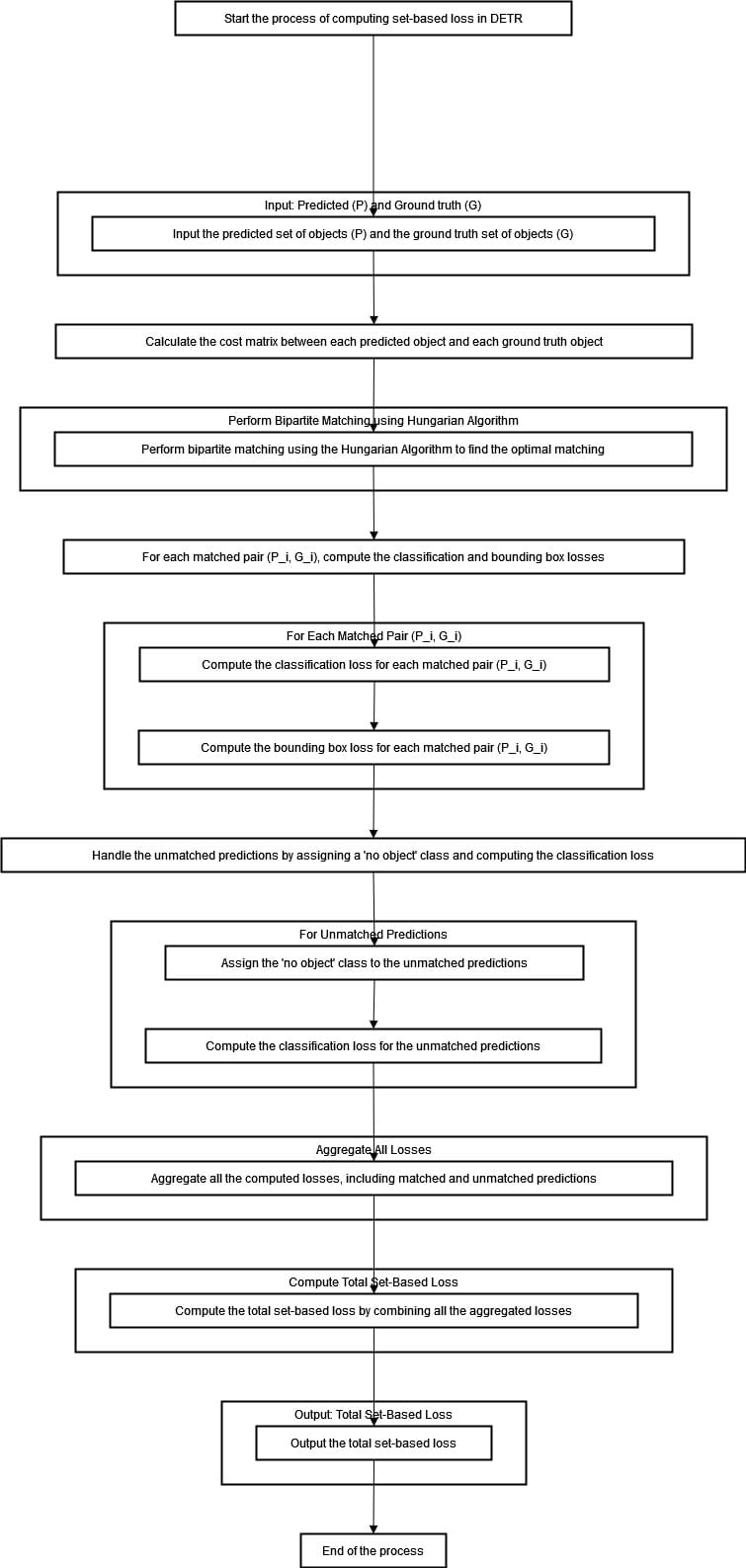
Embarking by way of the diagram above, we first bump into an interesting enter stage the place predicted and floor reality objects are fed into the system. As we progress deeper into its mechanics, our consideration is drawn in direction of a computational course of that entails computing a value matrix.
The Hungarian algorithm comes forth in time to orchestrate optimum matching between predicted and ground-truth objects—the algorithm elements in classification and bounding field losses for every match paired.
Predictions that fail to discover a counterpart are handed off the “no object” label with their respective classification loss evaluated. All these losses are aggregated to compute the overall set-based loss, which is then outputted, marking the top of the method.
This distinctive matching forces the mannequin to make distinct predictions for every object. The worldwide nature of evaluating the whole set of forecasts collectively in comparison with the bottom truths drives the community to make coherent detections throughout all the picture. So, the particular pairing loss offers supervision on the degree of the entire prediction set, guaranteeing strong and constant object localization.
Overview of DETR Structure for Object Detection
We are able to have a look at the diagram of the DETR structure under. We encode the picture on one aspect after which go it to the Transformer decoder on the opposite aspect. No loopy function engineering or something handbook anymore. It is all discovered routinely from knowledge by the neural community.
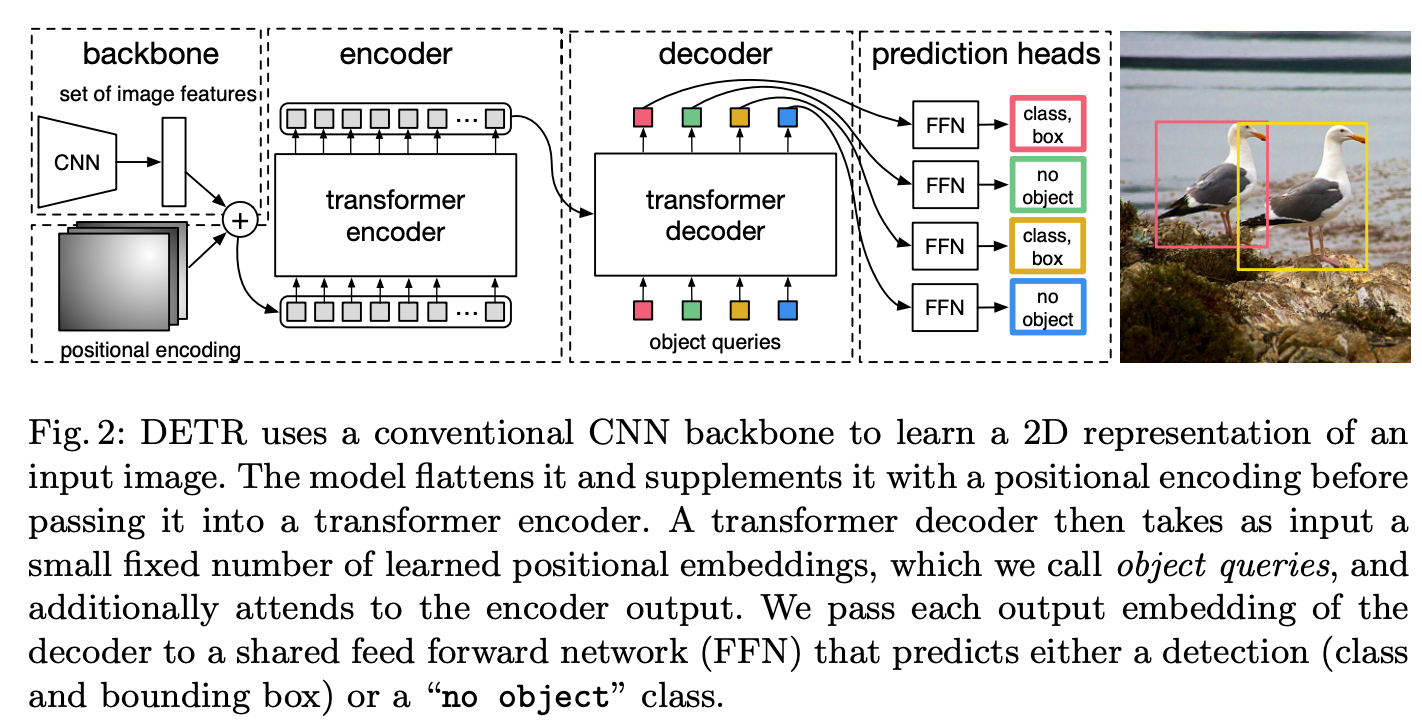
As proven within the picture, DETR’s structure consists of the next elements:
- Convolutional Spine: The convolutional spine is a regular CNN used to extract options from the enter picture. The options are then handed to the transformer encoder.
- Transformer Encoder: The transformer encoder processes the options extracted by the convolutional spine and generates a set of function maps. The transformer encoder makes use of self-attention to seize the relationships between the objects within the picture.
- Transformer Decoder: The transformer decoder will get a couple of set discovered place embeddings as enter, which we name object queries. It additionally pays consideration to the encoder output. We give every output embedding from the decoder to a shared feed-forward community (FFN) that predicts both a detection (class and bounding field) or a “no object” class.
- Object Queries: The thing queries are discovered positional embeddings utilized by the transformer decoder to take care of the encoder output. The thing queries are discovered throughout coaching and used to foretell the ultimate detections.
- Detection Head: The detection head is a feed-forward neural community that takes the output of the transformer decoder and produces the ultimate set of detections. The detection head predicts the category and bounding field for every object question.
The Transformers structure adopted by DETR is proven within the image under:
DETR brings some new ideas to the desk for object detection. It makes use of object queries, keys, and values as a part of the Transformer’s self-attention mechanism.
Often, the variety of object queries is about beforehand and would not change primarily based on what number of objects are literally within the picture. The keys and values come from encoding the picture with a CNN. The keys present the place completely different spots are within the picture, whereas the values maintain details about options. These keys and values are used for self-attention so the mannequin can decide which elements of the picture are most vital.
The true innovation in DETR lies in its use of multi-head self-attention. This lets DETR perceive complicated relationships and connections between completely different objects within the picture. Every consideration head can deal with numerous items of the picture concurrently.
Utilizing the DETR Mannequin for Object Detection with Hugging Face Transformers
Deliver this mission to life
The fb/detr-resnet-50 mannequin is an implementation of the DETR mannequin. At its core, it is powered by a transformer structure.
Particularly, this mannequin makes use of an encoder-decoder transformer and a spine ResNet-50 convolutional neural community. This implies it may analyze a picture, detect numerous objects inside it, and establish what these objects are.
The researchers educated this mannequin on an unlimited dataset known as COCO that has tons of labeled on a regular basis photographs with folks, animals, and vehicles. This fashion, the mannequin discovered to detect on a regular basis real-world objects like a professional. The offered code demonstrates the utilization of the DETR mannequin for object detection.
Deliver this mission to life
from transformers import DetrImageProcessor, DetrForObjectDetection
import torch
from PIL import Picture
import requests
url = "http://photographs.cocodataset.org/val2017/000000039769.jpg"
picture = Picture.open(requests.get(url, stream=True).uncooked)
# you'll be able to specify the revision tag if you do not need the timm dependency
processor = DetrImageProcessor.from_pretrained("fb/detr-resnet-50", revision="no_timm")
mannequin = DetrForObjectDetection.from_pretrained("fb/detr-resnet-50", revision="no_timm")
inputs = processor(photographs=picture, return_tensors="pt")
outputs = mannequin(**inputs)
# convert outputs (bounding bins and sophistication logits) to COCO API
# let's solely hold detections with rating > 0.9
target_sizes = torch.tensor([image.size[::-1]])
outcomes = processor.post_process_object_detection(outputs, target_sizes=target_sizes, threshold=0.9)[0]
for rating, label, field in zip(outcomes["scores"], outcomes["labels"], outcomes["boxes"]):
field = [round(i, 2) for i in box.tolist()]
print(
f"Detected {mannequin.config.id2label[label.item()]} with confidence "
f"{spherical(rating.merchandise(), 3)} at location {field}"
)
Output:
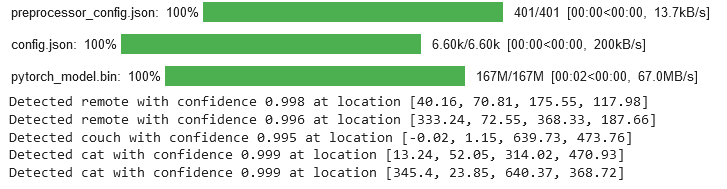
- The code above is performing some object detection stuff. First, it is grabbing the libraries it wants, just like the Hugging Face transformers and another normal ones like torch, PIL and requests.
- Then, it masses a picture from a URL utilizing requests. It sends the picture by way of some processing utilizing the
DetrImageProcessorto arrange it for the mannequin. - It instantiates the
DetrForObjectDetectionmannequin from the “fb/detr-resnet-50” utilizing thefrom_pretrainedtechnique. Therevision="no_timm"parameter specifies the revision tag if the time dependency isn’t desired. - With the picture and mannequin ready, the picture is fed into the mannequin, leading to seamless object detection. The
processorprepares the picture for enter, and themannequinperforms the thing detection activity. - The outputs from the mannequin, which embody bounding bins, class logits, and different related details about the detected objects within the picture, are then post-processed utilizing the
processor.post_process_object_detectiontechnique to acquire the ultimate detection outcomes. - The code then iterates by way of the outcomes to print the detected objects, their confidence scores, and their areas within the picture.
Conclusion
DETR is a deep studying mannequin for object detection that leverages the Transformer structure. It was initially designed for pure language processing (NLP) duties as its most important element to handle the thing detection drawback uniquely and extremely successfully.
DETR treats the thing detection drawback otherwise from conventional object detection methods like Quicker R-CNN or YOLO. It simplifies the detection pipeline by dropping a number of hand-designed elements that encode prior data, like spatial anchors or non-maximal suppression.
It makes use of a set world loss operate that compels the mannequin to generate distinctive predictions for every object by matching them in pairs. This trick helps DETR make good predictions that we will belief.
References
Actual-Time Object Detection: A Complete Information to Implementing Baidu’s RT-DETR with Paperspace
On this tutorial, we have a look at Baidu’s RT-DETR object detection framework, and present find out how to implement it in a Paperspace Pocket book.

Papers with Code – Detr Defined
Detr, or Detection Transformer, is a set-based object detector utilizing a Transformer on prime of a convolutional spine. It makes use of a traditional CNN spine to study a 2D illustration of an enter picture. The mannequin flattens it and dietary supplements it with a positional encoding earlier than passing it right into a tran…

Laptop Imaginative and prescient – Paperspace Weblog

“Petru Potrimba.” Roboflow Weblog, Sep 25, 2023. https://weblog.roboflow.com/what-is-detr/
A. R. Gosthipaty and R. Raha. “DETR Breakdown Half 1: Introduction to DEtection TRansformers,” PyImageSearch, P. Chugh, S. Huot, Ok. Kidriavsteva, and A. Thanki, eds., 2023, https://pyimg.co/fhm45
DETR
We’re on a journey to advance and democratize synthetic intelligence by way of open supply and open science.