
Though AutoML rose to recognition a couple of years in the past, the ealy work on AutoML dates back to the early 90’s when scientists revealed the primary papers on hyperparameter optimization. It was in 2014 when ICML organized the primary AutoML workshop that AutoML gained the eye of ML builders. One of many main focuses through the years of AutoML is the hyperparameter search downside, the place the mannequin implements an array of optimization strategies to find out the most effective performing hyperparameters in a big hyperparameter house for a selected machine studying mannequin. One other methodology generally applied by AutoML fashions is to estimate the chance of a selected hyperparameter being the optimum hyperparameter for a given machine studying mannequin. The mannequin achieves this by implementing Bayesian strategies that historically use historic information from beforehand estimated fashions, and different datasets. Along with hyperparameter optimization, different strategies attempt to choose the most effective fashions from an area of modeling alternate options.
On this article, we are going to cowl LightAutoML, an AutoML system developed primarily for a European firm working within the finance sector together with its ecosystem. The LightAutoML framework is deployed throughout varied purposes, and the outcomes demonstrated superior efficiency, similar to the extent of information scientists, even whereas constructing high-quality machine studying fashions. The LightAutoML framework makes an attempt to make the next contributions. First, the LightAutoML framework was developed primarily for the ecosystem of a giant European monetary and banking establishment. Owing to its framework and structure, the LightAutoML framework is ready to outperform state-of-the-art AutoML frameworks throughout a number of open benchmarks in addition to ecosystem purposes. The efficiency of the LightAutoML framework can also be in contrast towards fashions which can be tuned manually by information scientists, and the outcomes indicated stronger efficiency by the LightAutoML framework.
This text goals to cowl the LightAutoML framework in depth, and we discover the mechanism, the methodology, the structure of the framework together with its comparability with state-of-the-art frameworks. So let’s get began.
Though researchers first began engaged on AutoML within the mid and early 90’s, AutoML attracted a significant chunk of the eye over the previous couple of years, with a few of the outstanding industrial options implementing robotically construct Machine Studying fashions are Amazon’s AutoGluon, DarwinAI, H20.ai, IBM Watson AI, Microsoft AzureML, and much more. A majority of those frameworks implement a basic goal AutoML resolution that develops ML-based fashions robotically throughout totally different lessons of purposes throughout monetary companies, healthcare, schooling, and extra. The important thing assumption behind this horizontal generic method is that the method of growing automated fashions stays equivalent throughout all purposes. Nonetheless, the LightAutoML framework implements a vertical method to develop an AutoML resolution that isn’t generic, however moderately caters to the wants of particular person purposes, on this case a big monetary establishment. The LightAutoML framework is a vertical AutoML resolution that focuses on the necessities of the advanced ecosystem together with its traits. First, the LightAutoML framework offers quick and close to optimum hyperparameter search. Though the mannequin doesn’t optimize these hyperparameters straight, it does handle to ship passable outcomes. Moreover, the mannequin retains the stability between pace and hyperparameter optimization dynamic, to make sure the mannequin is perfect on small issues, and quick sufficient on bigger ones. Second, the LightAutoML framework limits the vary of machine studying fashions purposefully to solely two varieties: linear fashions, and GBMs or gradient boosted choice bushes, as a substitute of implementing massive ensembles of various algorithms. The first cause behind limiting the vary of machine studying fashions is to hurry up the execution time of the LightAutoML framework with out affecting the efficiency negatively for the given kind of downside and information. Third, the LightAutoML framework presents a novel methodology of selecting preprocessing schemes for various options used within the fashions on the idea of sure choice guidelines and meta-statistics. The LightAutoML framework is evaluated on a variety of open information sources throughout a variety of purposes.
LightAutoML : Methodology and Structure
The LightAutoML framework consists of modules referred to as Presets which can be devoted for finish to finish mannequin improvement for typical machine studying duties. At current, the LightAutoML framework helps Preset modules. First, the TabularAutoML Preset focuses on fixing classical machine studying issues outlined on tabular datasets. Second, the White-Field Preset implements easy interpretable algorithms resembling Logistic Regression as a substitute of WoE or Weight of Proof encoding and discretized options to unravel binary classification duties on tabular information. Implementing easy interpretable algorithms is a standard follow to mannequin the chance of an software owing to the interpretability constraints posed by various factors. Third, the NLP Preset is able to combining tabular information with NLP or Pure Language Processing instruments together with pre-trained deep studying fashions and particular function extractors. Lastly, the CV Preset works with picture information with the assistance of some primary instruments. You will need to be aware that though the LightAutoML mannequin helps all 4 Presets, the framework solely makes use of the TabularAutoML within the production-level system.
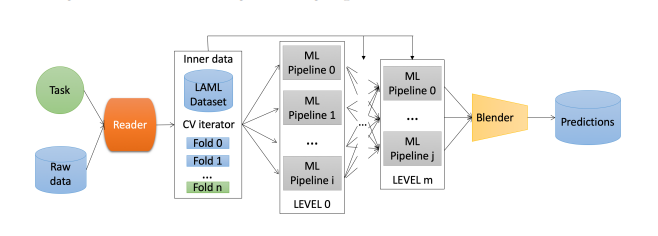
The everyday pipeline of the LightAutoML framework is included within the following picture.

Every pipeline accommodates three parts. First, Reader, an object that receives job kind and uncooked information as enter, performs essential metadata calculations, cleans the preliminary information, and figures out the info manipulations to be carried out earlier than becoming totally different fashions. Subsequent, the LightAutoML inside datasets comprise CV iterators and metadata that implement validation schemes for the datasets. The third element are the a number of machine studying pipelines stacked and/or blended to get a single prediction. A machine studying pipeline throughout the structure of the LightAutoML framework is one in all a number of machine studying fashions that share a single information validation and preprocessing scheme. The preprocessing step could have as much as two function choice steps, a function engineering step or could also be empty if no preprocessing is required. The ML pipelines might be computed independently on the identical datasets after which blended collectively utilizing averaging (or weighted averaging). Alternatively, a stacking ensemble scheme can be utilized to construct multi degree ensemble architectures.
LightAutoML Tabular Preset
Throughout the LightAutoML framework, TabularAutoML is the default pipeline, and it’s applied within the mannequin to unravel three kinds of duties on tabular information: binary classification, regression, and multi-class classification for a wide selection of efficiency metrics and loss capabilities. A desk with the next 4 columns: categorical options, numerical options, timestamps, and a single goal column with class labels or steady worth is feeded to the TabularAutoML element as enter. One of many main targets behind the design of the LightAutoML framework was to design a device for quick speculation testing, a significant cause why the framework avoids utilizing brute-force strategies for pipeline optimization, and focuses solely on effectivity strategies and fashions that work throughout a variety of datasets.
Auto-Typing and Information Preprocessing
To deal with various kinds of options in numerous methods, the mannequin must know every function kind. Within the state of affairs the place there’s a single job with a small dataset, the person can manually specify every function kind. Nonetheless, specifying every function kind manually is not a viable choice in conditions that embrace a whole bunch of duties with datasets containing hundreds of options. For the TabularAutoML Preset, the LightAutoML framework must map options into three lessons: numeric, class, and datetime. One easy and apparent resolution is to make use of column array information varieties as precise function varieties, that’s, to map float/int columns to numeric options, timestamp or string, that might be parsed as a timestamp — to datetime, and others to class. Nonetheless, this mapping just isn’t the most effective due to the frequent incidence of numeric information varieties in class columns.
Validation Schemes
Validation schemes are a significant element of AutoML frameworks since information within the business is topic to vary over time, and this factor of change makes IID or Unbiased Identically Distributed assumptions irrelevant when growing the mannequin. AutoML fashions make use of validation schemes to estimate their efficiency, seek for hyperparameters, and out-of-fold prediction technology. The TabularAutoML pipeline implements three validation schemes:
- KFold Cross Validation: KFold Cross Validation is the default validation scheme for the TabularAutoML pipeline together with GroupKFold for behavioral fashions, and stratified KFold for classification duties.
- Holdout Validation : The Holdout validation scheme is applied if the holdout set is specified.
- Customized Validation Schemes: Customized validation schemes might be created by customers relying on their particular person necessities. Customized Validation Schemes embrace cross-validation, and time-series break up schemes.
Function Choice
Though function choice is an important facet of growing fashions as per business requirements because it facilitates discount in inference and mannequin implementation prices, a majority of AutoML options don’t focus a lot on this downside. Quite the opposite, the TabularAutoML pipeline implements three function choice methods: No choice, Significance reduce off choice, and Significance-based ahead choice. Out of the three, Significance reduce off choice function choice technique is default. Moreover, there are two main methods to estimate function significance: split-based tree significance, and permutation significance of GBM mannequin or gradient boosted choice bushes. The first intention of significance cutoff choice is to reject options that aren’t useful to the mannequin, permitting the mannequin to scale back the variety of options with out impacting the efficiency negatively, an method which may pace up mannequin inference and coaching.

The above picture compares totally different choice methods on binary financial institution datasets.
Hyperparameter Tuning
The TabularAutoML pipeline implements totally different approaches to tune hyperparameters on the idea of what’s tuned.
- Early Stopping Hyperparameter Tuning selects the variety of iterations for all fashions in the course of the coaching section.
- Skilled System Hyperparameter Tuning is a straightforward technique to set hyperparameters for fashions in a passable style. It prevents the ultimate mannequin from a excessive lower in rating in comparison with hard-tuned fashions.
- Tree Structured Parzen Estimation or TPE for GBM or gradient boosted choice tree fashions. TPE is a blended tuning technique that’s the default alternative within the LightAutoML pipeline. For every GMB framework, the LightAutoML framework trains two fashions: the primary will get professional hyperparameters, the second is fine-tuned to suit into the time funds.
- Grid Search Hyperparameter Tuning is applied within the TabularAutoML pipeline to fine-tune the regularization parameters of a linear mannequin alongside early stopping, and heat begin.
The mannequin tunes all of the parameters by maximizing the metric perform, both outlined by the person or is default for the solved job.

LightAutoML : Experiment and Efficiency
To judge the efficiency, the TabularAutoML Preset throughout the LightAutoML framework is in contrast towards already current open supply options throughout varied duties, and cements the superior efficiency of the LightAutoML framework. First, the comparability is carried out on the OpenML benchmark that’s evaluated on 35 binary and multiclass classification job datasets. The next desk summarizes the comparability of the LightAutoML framework towards current AutoML techniques.

As it may be seen, the LightAutoML framework outperforms all different AutoML techniques on 20 datasets throughout the benchmark. The next desk accommodates the detailed comparability within the dataset context indicating that the LightAutoML delivers totally different efficiency on totally different lessons of duties. For binary classification duties, the LightAutoML falls quick in efficiency, whereas for duties with a excessive quantity of information, the LightAutoML framework delivers superior efficiency.

The next desk compares the efficiency of LightAutoML framework towards AutoML techniques on 15 financial institution datasets containing a set of assorted binary classification duties. As it may be noticed, the LightAutoML outperforms all AutoML options on 12 out of 15 datasets, a win proportion of 80.

Closing Ideas
On this article we’ve got talked about LightAutoML, an AutoML system developed primarily for a European firm working within the finance sector together with its ecosystem. The LightAutoML framework is deployed throughout varied purposes, and the outcomes demonstrated superior efficiency, similar to the extent of information scientists, even whereas constructing high-quality machine studying fashions. The LightAutoML framework makes an attempt to make the next contributions. First, the LightAutoML framework was developed primarily for the ecosystem of a giant European monetary and banking establishment. Owing to its framework and structure, the LightAutoML framework is ready to outperform state-of-the-art AutoML frameworks throughout a number of open benchmarks in addition to ecosystem purposes. The efficiency of the LightAutoML framework can also be in contrast towards fashions which can be tuned manually by information scientists, and the outcomes indicated stronger efficiency by the LightAutoML framework.

