
The latest progress and development of Giant Language Fashions has skilled a major improve in vision-language reasoning, understanding, and interplay capabilities. Trendy frameworks obtain this by projecting visible alerts into LLMs or Giant Language Fashions to allow their capability to understand the world visually, an array of situations the place visible encoding methods play an important position. Nevertheless, real-world photos not solely comprise a variety of situations, additionally they fluctuate considerably when it comes to resolutions and facet ratios, posing important challenges for LLMs throughout completely different domains and duties. To sort out the numerous variance posed by real-world photos, fashionable massive language fashions understand photos in a low decision i.e. 224×224, and a hard and fast facet ratio i.e. 1:1. Though making the compromise to stay with low decision and stuck facet ratio will increase the generalizability of the LLM in real-world purposes, it typically blurs the contents of the picture considerably whereas additionally leading to extreme form distortion. The compromise considerably impacts the skills of the massive multi-modality fashions or LMMs particularly those optimized for fine-grained duties together with optical character recognition, and small object understanding. Moreover, because the decision and the facet ratio are pre-determined, the fashions can solely make one of the best guesses to the blurred photos, leading to mannequin hallucinations, a state of affairs beneath which the mannequin produces textual responses that aren’t grounded factually within the photos.
On this article, we might be speaking about LLaVA-UHD, a novel strategy that first takes the LLaVA-1.5 and the GPT-4V frameworks as consultant examples, and makes an attempt to show the systematic flaws rooted of their visible encoding technique. The LLaVA-UHD framework, a multimodal modal, is an try to deal with the challenges. The LLaVA-UHD framework can understand photos in excessive decision in addition to in any facet ratio. The LLaVA-UHD framework is constructed round three key elements. First, a picture modularization technique that divides native-resolution photos into smaller variable-sized slices in an try to boost effectivity and lengthen encoding. Subsequent, a compression module that condenses picture tokens produced by visible encoders additional. Lastly, a spatial schema that organizes slice tokens for the massive language fashions. Complete experiments point out that the LLaVA-UHD framework is ready to outperform state-of-the-art massive language fashions on 9 benchmarks. Moreover, through the use of solely 94% inference computation, the LLaVA-UHD framework is ready to help photos with 6 occasions bigger decision i.e 672×1088.
Imaginative and prescient-Language reasoning, understanding, and interplay have made important progress of late, largely as a result of latest push for Giant Language Fashions. In fashionable frameworks, the identical is completed by feeding visible alerts into LLMs (Giant Language Fashions) to make them able to deciphering the true world visually, a various vary of situations that depend on visible encoding methods. The distinction in situation displays a slim protection of LLMs throughout completely different domains and duties, while the distinction in resolutions and facet ratios reveals the massive intraclass variations within the real-world photos that are arduous to deal with. Not like the small scale that lowers the variance, fashions after BERT sort out the importance from the low decision (e.g., for the LLaVA-UHD it is 224×224) of photos with a hard and fast facet ratio, 1:1 to present real-world photos. Whereas this compromise is beneficial for making certain the generalizability of the LLM to real-world purposes, it typically results in very blurry photos whereas selling extreme form distortion. This reduces the capabilities of the large multi-modality fashions or LMMs (e.g., fine-grained duties), equivalent to optical character recognition and small object understanding. Because the decision and the facet ratio are pre-defined, the fashions can solely guess the blurred photos, resulting in mannequin hallucination, making the ultimate generated textual responses not factually grounded within the photos. So why don’t benchmark LMMs fashions understand photos in excessive resolutions and diverse facet ratios?
There are two main the explanation why benchmark LMMs are unable to understand photos with excessive decision and diverse decision. First, since visible encoders are pre-trained in fastened resolutions, it makes it troublesome for the mannequin and encoder to cope with photos with various facet ratios and resolutions, thus considerably impacting the adaptability of the mannequin. Second, encoding high-resolution photos instantly utilizing imaginative and prescient transformers is related to important computing value with respect to the scale of the pictures. Moreover, the computation prices could be considerably increased for the massive language mannequin to course of numerous visible tokens for high-resolution photos, thus considerably impacting the general effectivity of the mannequin. To counter these challenges, the LLaVA-UHD, a big multimodal mannequin that perceives excessive decision photos and any facet ratio, takes the LLaVA-1.5 and the GPT-4V frameworks as consultant examples, and makes an attempt to show the systematic flaws rooted of their visible encoding technique.

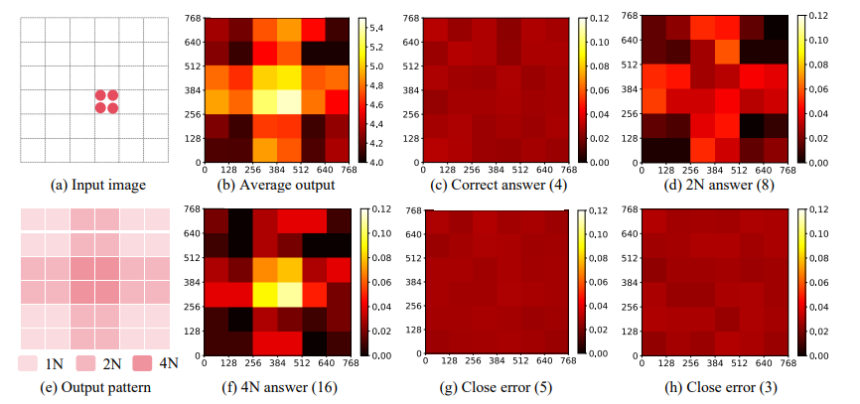
The above picture displays on the experimental outcomes of the GPT-4V in figuring out the variety of objects inside a picture. At its core, the LLaVA-UHD framework has three elements. First, a picture modularization technique that divides native-resolution photos into smaller variable-sized slices for extensible and environment friendly coding. Opposite to the latest LLMs that match photos into a number of fastened resolutions and facet ratios, the variable-sized slices generated by the LLaVA-UHD framework allows full adaptivity to the native-resolution photos with out distorting shapes, resizing, or padding. Second, the mannequin condenses the visible tokens by a compression layer to modest size, leading to lowering the computation for LLMs considerably. Lastly, the mannequin organizes the compressed slice tokens in a spatial schema to tell the slice positions within the photos to the massive language mannequin.
LLaVA-UHD : Methodology and Structure
On the idea of the learnings from some pilot experiments to review current frameworks together with GPT-4V and LLaVA-1.5, the LLaVA-UHD framework implements a 3 element structure as demonstrated within the following picture.

First, a picture modularization technique that divides native-resolution photos into smaller variable-sized slices in an try to boost effectivity and lengthen encoding. Subsequent, a compression module that condenses picture tokens produced by visible encoders additional. Lastly, a spatial schema that organizes slice tokens for the massive language fashions. Let’s have an in depth look into these elements.
Modularized Visible Encoding
A typical strategy to cope with high-resolution photos with completely different facet ratio is to interpolate the place embeddings of the Imaginative and prescient Transformer or ViT to the goal form for direct encoding as a complete. Nevertheless, the implementation of this strategy is usually accompanied with excessive computation prices, and out of distribution points lead to additional efficiency degradation. To sort out this problem, the LLaVA-UHD framework presents a modularized visible encoding technique that principally goals to divide native decision photos into smaller variable-sized slices the place the form of every slice is kind of near the usual pre-training setting of the imaginative and prescient transformer. Owing to the usage of variable-sized slice slices, the LLaVA-UHD framework is ready to obtain full adaptability to native decision photos with out implementing any shape-distorting reshaping or padding. Moreover, the first objective of the picture slicing technique is to find out a cut up of excessive decision photos with minimal adjustments to the resolutions of every slice. For a given picture with a sure decision (w,h), and a imaginative and prescient transformer pre-trained in one other decision, the LLaVA-UHD framework first determines the best computation i.e. the variety of slices required to course of the picture. The framework then factorizes the variety of slices into m columns and n rows. The framework then defines a rating operate to measure the deviation from the usual pre-training setting of the imaginative and prescient transformer. Theoretically, the LLaVA-UHD framework is ready to reveal the partition technique carried out in its structure ensures minor anticipated adjustments and modest worst-case adjustments with respect to plain pretraining decision for every slice.
Moreover, a majority of current LLMs implement a static decision for picture slice encoding, an strategy that stops the complete adaptability of the mannequin to native resolutions since they’ve entry solely to a number of predefined fastened form slices. Moreover, static slice decision hurts the efficiency, effectivity, and the correctness of the mannequin because it incurs shape-distorting resizing or padding inevitably. To sort out this concern, the LLaVA-UHD framework proposes to encode picture slices in facet ratio as outlined by the partition technique. To be extra particular, the LLaVA-UHD framework first resizes the unique picture proportionally in accordance with the facet ratio in a means that the variety of patches suits throughout the pre-training funds i.e. the variety of place embedding sequence within the imaginative and prescient transformer, maximally. The LLaVA-UHD mannequin then reshapes the pre-trained 1D place embedding sequence of the imaginative and prescient transformer right into a 2D format in accordance with its pre-training settings.
Compression Layer
A typical concern LLMs face when processing high-resolution photos is that the quantity of visible tokens they should course of is considerably increased(for reference, the LLaVA-1.5 framework produces round 3500 visible tokens when processing a single picture with decision: 672×1008), accounting for a serious a part of the computational sources and price. To account for this problem, the LLaVA-UHD mannequin implements a shared perceiver resampler layer to compress the visible tokens of every picture slice. The mannequin then implements a set of question vectors by way of cross-attention to resample the output of picture tokens by the visible encoders to a decrease quantity. Compared in opposition to prevalent Multilayer Perceptron-based visible projection methods, the perceiver pattern strategy carried out by LLaVA-UHD is ready to keep an inexpensive but fastened variety of visible tokens regardless of its picture decision, making the LLaVA-UHD framework extra appropriate with high-resolution picture processing and understanding duties. To place that into image, the LLaVA-UDH framework generates the identical quantity of tokens when encoding a 672×1008 decision picture because the LLaVA-1.5 framework generates when encoding a 336×336 decision picture, practically 6 occasions simpler than its competitor.
Spatial Schema for Picture Slices
It’s a needed observe to tell the massive language mannequin of the spatial organizations of picture slices because the partitioning of photos is dynamic throughout completely different photos. The LLaVA-UHD framework designs and implements a spatial schema that makes use of two particular tokens to tell the LLM of the relative place of the picture slices. Underneath this spatial schema, the LLaVA-UHD framework makes use of “,” to separate the slice representations in a row, and the completely different rows are separated utilizing a “n”.
LLaVA-UDH : Experiments and Outcomes
The LLaVA-UHD framework is evaluated in opposition to 9 common benchmarks together with basic visible query answering benchmarks, optical character primarily based visible query answering benchmarks, hallucination benchmark, and complete benchmarks. Moreover, the LLaVA-UHD framework is in contrast in opposition to robust baselines together with LLaVA-1.5, MiniGPT-v2, InstructBLIP, BLIP-2, and extra.
The efficiency of the LLaVA-UHD framework on 9 common benchmarks is summarized, and in contrast in opposition to common benchmarks within the desk under.

On the idea of the above efficiency, it may be concluded that the LLaVA-UHD framework is ready to outperform robust baseline fashions on common benchmarks together with robust basic baselines skilled on a considerably bigger quantity of information, together with outperforming LLMs that want considerably extra computation like Fuyu-8B, Monkey, and extra. Second, the outcomes additionally point out that the LLaVA-UHD framework achieves considerably higher outcomes over the LLaVA-1.5 structure, and on one hand the place LLaVA-1.5 helps a hard and fast 336×336 decision, the LLaVA-UHD framework helps 672×1088 decision photos with any facet ratio, and the identical variety of visible tokens.


Ultimate Ideas
On this article we have now talked about LLaVA-UHD, a novel strategy that first takes the LLaVA-1.5 and the GPT-4V frameworks as consultant examples, and makes an attempt to show the systematic flaws rooted of their visible encoding technique. The LLaVA-UHD framework, a multimodal modal, is an try to deal with the challenges. The LLaVA-UHD framework can understand photos in excessive decision in addition to in any facet ratio. The LLaVA-UHD framework is constructed round three key elements. First, a picture modularization technique that divides native-resolution photos into smaller variable-sized slices in an try to boost effectivity and lengthen encoding. Subsequent, a compression module that condenses picture tokens produced by visible encoders additional. Lastly, a spatial schema that organizes slice tokens for the massive language fashions. Complete experiments point out that the LLaVA-UHD framework is ready to outperform state-of-the-art massive language fashions on 9 benchmarks. Moreover, through the use of solely 94% inference computation, the LLaVA-UHD framework is ready to help photos with 6 occasions bigger decision i.e 672×1088.

