
Meta has released the most recent entry in its Llama sequence of open generative AI fashions: Llama 3. Or, extra precisely, the corporate has debuted two fashions in its new Llama 3 household, with the remainder to come back at an unspecified future date.
Meta describes the brand new fashions — Llama 3 8B, which comprises 8 billion parameters, and Llama 3 70B, which comprises 70 billion parameters — as a “main leap” in comparison with the previous-gen Llama fashions, Llama 2 8B and Llama 2 70B, performance-wise. (Parameters primarily outline the talent of an AI mannequin on an issue, like analyzing and producing textual content; higher-parameter-count fashions are, usually talking, extra succesful than lower-parameter-count fashions.) Actually, Meta says that, for his or her respective parameter counts, Llama 3 8B and Llama 3 70B — educated on two custom-built 24,000 GPU clusters — are are among the many best-performing generative AI fashions out there as we speak.
That’s fairly a declare to make. So how is Meta supporting it? Properly, the corporate factors to the Llama 3 fashions’ scores on widespread AI benchmarks like MMLU (which makes an attempt to measure information), ARC (which makes an attempt to measure talent acquisition) and DROP (which assessments a mannequin’s reasoning over chunks of textual content). As we’ve written about earlier than, the usefulness — and validity — of those benchmarks is up for debate. However for higher or worse, they continue to be one of many few standardized methods by which AI gamers like Meta consider their fashions.
Llama 3 8B bests different open fashions comparable to Mistral’s Mistral 7B and Google’s Gemma 7B, each of which comprise 7 billion parameters, on no less than 9 benchmarks: MMLU, ARC, DROP, GPQA (a set of biology-, physics- and chemistry-related questions), HumanEval (a code technology check), GSM-8K (math phrase issues), MATH (one other arithmetic benchmark), AGIEval (a problem-solving check set) and BIG-Bench Onerous (a commonsense reasoning analysis).
Now, Mistral 7B and Gemma 7B aren’t precisely on the bleeding edge (Mistral 7B was launched final September), and in a number of of benchmarks Meta cites, Llama 3 8B scores only some proportion factors greater than both. However Meta additionally makes the declare that the larger-parameter-count Llama 3 mannequin, Llama 3 70B, is aggressive with flagship generative AI fashions together with Gemini 1.5 Professional, the most recent in Google’s Gemini sequence.
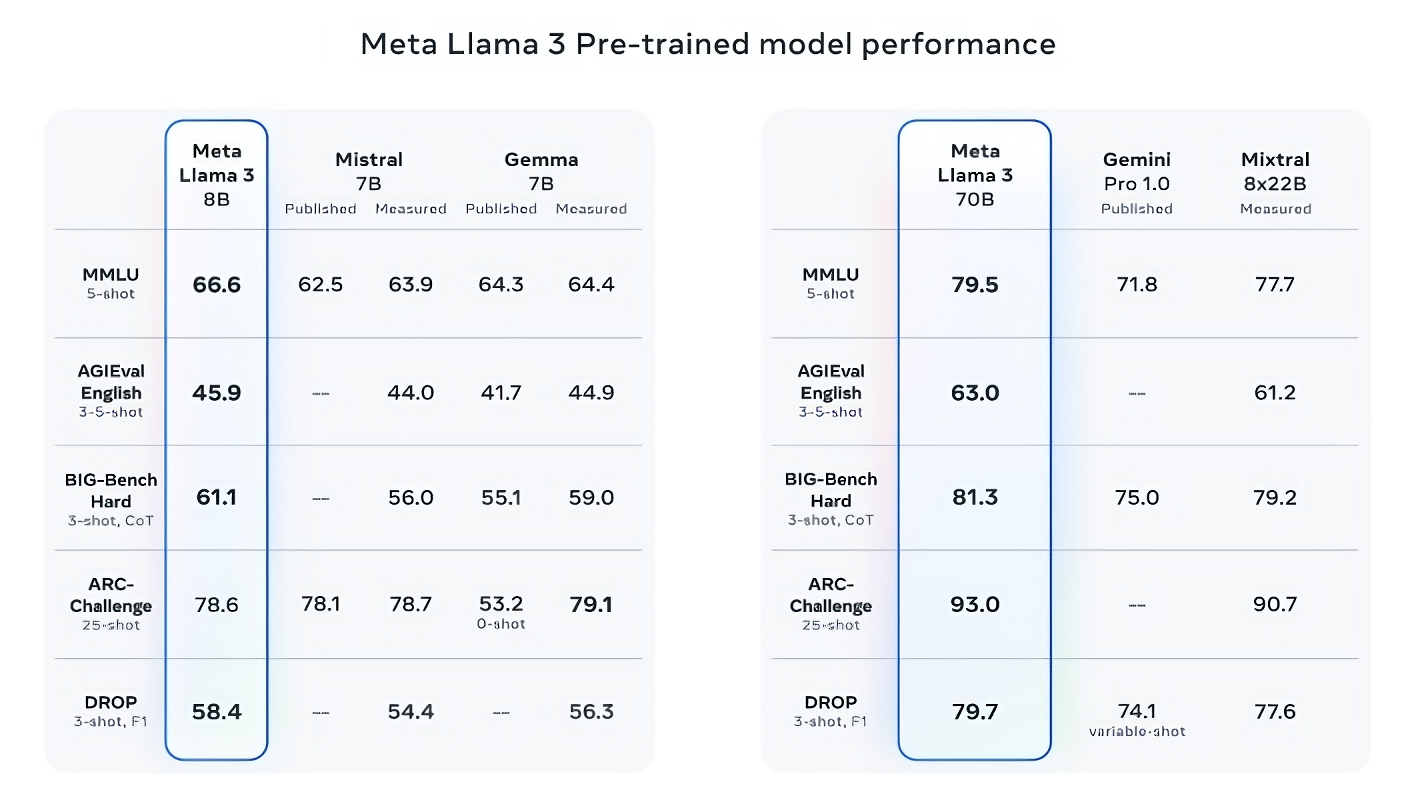
Picture Credit: Meta
Llama 3 70B beats Gemini 1.5 Professional on MMLU, HumanEval and GSM-8K, and — whereas it doesn’t rival Anthropic’s most performant mannequin, Claude 3 Opus — Llama 3 70B scores higher than the second-weakest mannequin within the Claude 3 sequence, Claude 3 Sonnet, on 5 benchmarks (MMLU, GPQA, HumanEval, GSM-8K and MATH).
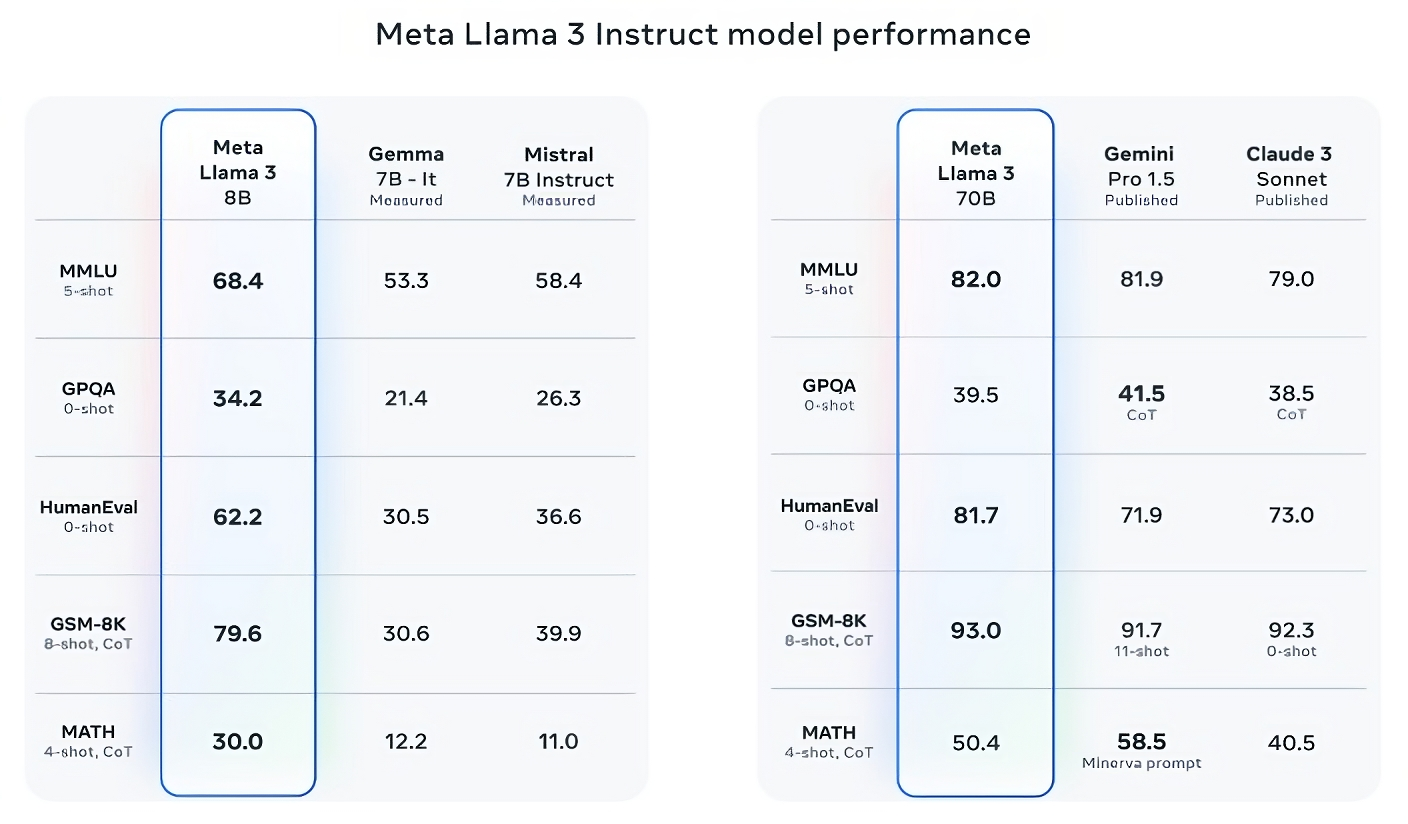
Picture Credit: Meta
For what it’s value, Meta additionally developed its personal check set masking use circumstances starting from coding and creating writing to reasoning to summarization, and — shock! — Llama 3 70B got here out on high in opposition to Mistral’s Mistral Medium mannequin, OpenAI’s GPT-3.5 and Claude Sonnet. Meta says that it gated its modeling groups from accessing the set to take care of objectivity, however clearly — provided that Meta itself devised the check — the outcomes must be taken with a grain of salt.
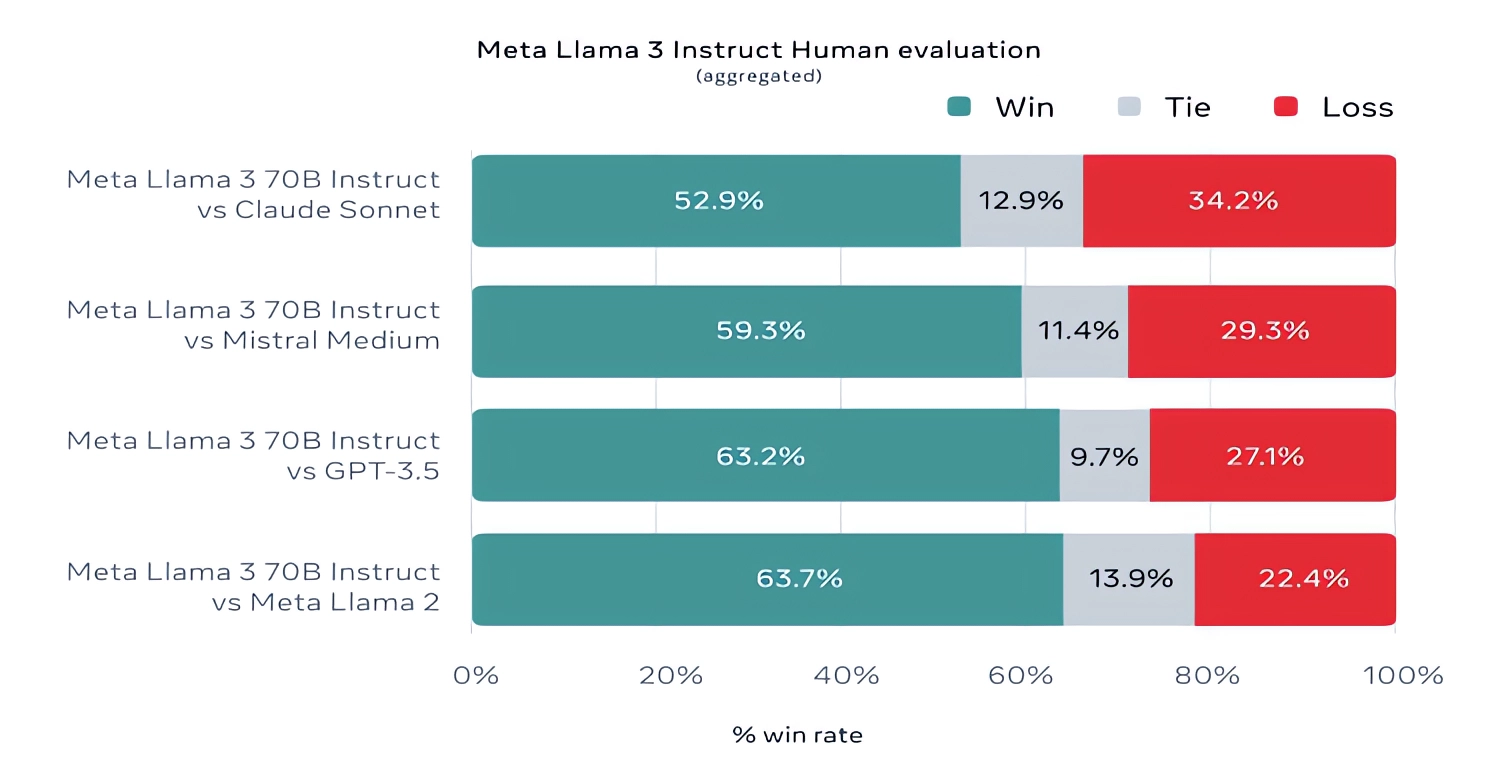
Picture Credit: Meta
Extra qualitatively, Meta says that customers of the brand new Llama fashions ought to anticipate extra “steerability,” a decrease chance to refuse to reply questions, and better accuracy on trivia questions, questions pertaining to historical past and STEM fields comparable to engineering and science and normal coding suggestions. That’s partly because of a a lot bigger knowledge set: a group of 15 trillion tokens, or a mind-boggling ~750,000,000,000 phrases — seven occasions the scale of the Llama 2 coaching set. (Within the AI discipline, “tokens” refers to subdivided bits of uncooked knowledge, just like the syllables “fan,” “tas” and “tic” within the phrase “incredible.”)
The place did this knowledge come from? Good query. Meta wouldn’t say, revealing solely that it drew from “publicly out there sources,” included 4 occasions extra code than within the Llama 2 coaching knowledge set, and that 5% of that set has non-English knowledge (in ~30 languages) to enhance efficiency on languages aside from English. Meta additionally stated it used artificial knowledge — i.e. AI-generated knowledge — to create longer paperwork for the Llama 3 fashions to coach on, a somewhat controversial approach because of the potential efficiency drawbacks.
“Whereas the fashions we’re releasing as we speak are solely nice tuned for English outputs, the elevated knowledge variety helps the fashions higher acknowledge nuances and patterns, and carry out strongly throughout a wide range of duties,” Meta writes in a weblog publish shared with TechCrunch.
Many generative AI distributors see coaching knowledge as a aggressive benefit and thus preserve it and information pertaining to it near the chest. However coaching knowledge particulars are additionally a possible supply of IP-related lawsuits, one other disincentive to disclose a lot. Recent reporting revealed that Meta, in its quest to take care of tempo with AI rivals, at one level used copyrighted ebooks for AI coaching regardless of the corporate’s personal attorneys’ warnings; Meta and OpenAI are the topic of an ongoing lawsuit introduced by authors together with comic Sarah Silverman over the distributors’ alleged unauthorized use of copyrighted knowledge for coaching.
So what about toxicity and bias, two different frequent issues with generative AI fashions (including Llama 2)? Does Llama 3 enhance in these areas? Sure, claims Meta.
Meta says that it developed new data-filtering pipelines to spice up the standard of its mannequin coaching knowledge, and that it’s up to date its pair of generative AI security suites, Llama Guard and CybersecEval, to try to stop the misuse of and undesirable textual content generations from Llama 3 fashions and others. The corporate’s additionally releasing a brand new device, Code Defend, designed to detect code from generative AI fashions which may introduce safety vulnerabilities.
Filtering isn’t foolproof, although — and instruments like Llama Guard, CybersecEval and Code Defend solely go up to now. (See: Llama 2’s tendency to make up answers to questions and leak private health and financial information.) We’ll have to attend and see how the Llama 3 fashions carry out within the wild, inclusive of testing from teachers on various benchmarks.
Meta says that the Llama 3 fashions — which can be found for obtain now, and powering Meta’s Meta AI assistant on Fb, Instagram, WhatsApp, Messenger and the online — will quickly be hosted in managed type throughout a variety of cloud platforms together with AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM’s WatsonX, Microsoft Azure, Nvidia’s NIM and Snowflake. Sooner or later, variations of the fashions optimized for {hardware} from AMD, AWS, Dell, Intel, Nvidia and Qualcomm may even be made out there.
The Llama 3 fashions is likely to be broadly out there. However you’ll discover that we’re utilizing “open” to explain them versus “open supply.” That’s as a result of, regardless of Meta’s claims, its Llama household of fashions aren’t as no-strings-attached because it’d have individuals imagine. Sure, they’re out there for each analysis and business functions. However, Meta forbids builders from utilizing Llama fashions to coaching different generative fashions, whereas app builders with greater than 700 million month-to-month customers should request a particular license from Meta that the corporate will — or gained’t — grant based mostly on its discretion.
Extra succesful Llama fashions are on the horizon.
Meta says that it’s at present coaching Llama 3 fashions over 400 billion parameters in dimension — fashions with the flexibility to “converse in a number of languages,” take extra knowledge in and perceive photographs and different modalities in addition to textual content, which might deliver the Llama 3 sequence in keeping with open releases like Hugging Face’s Idefics2.
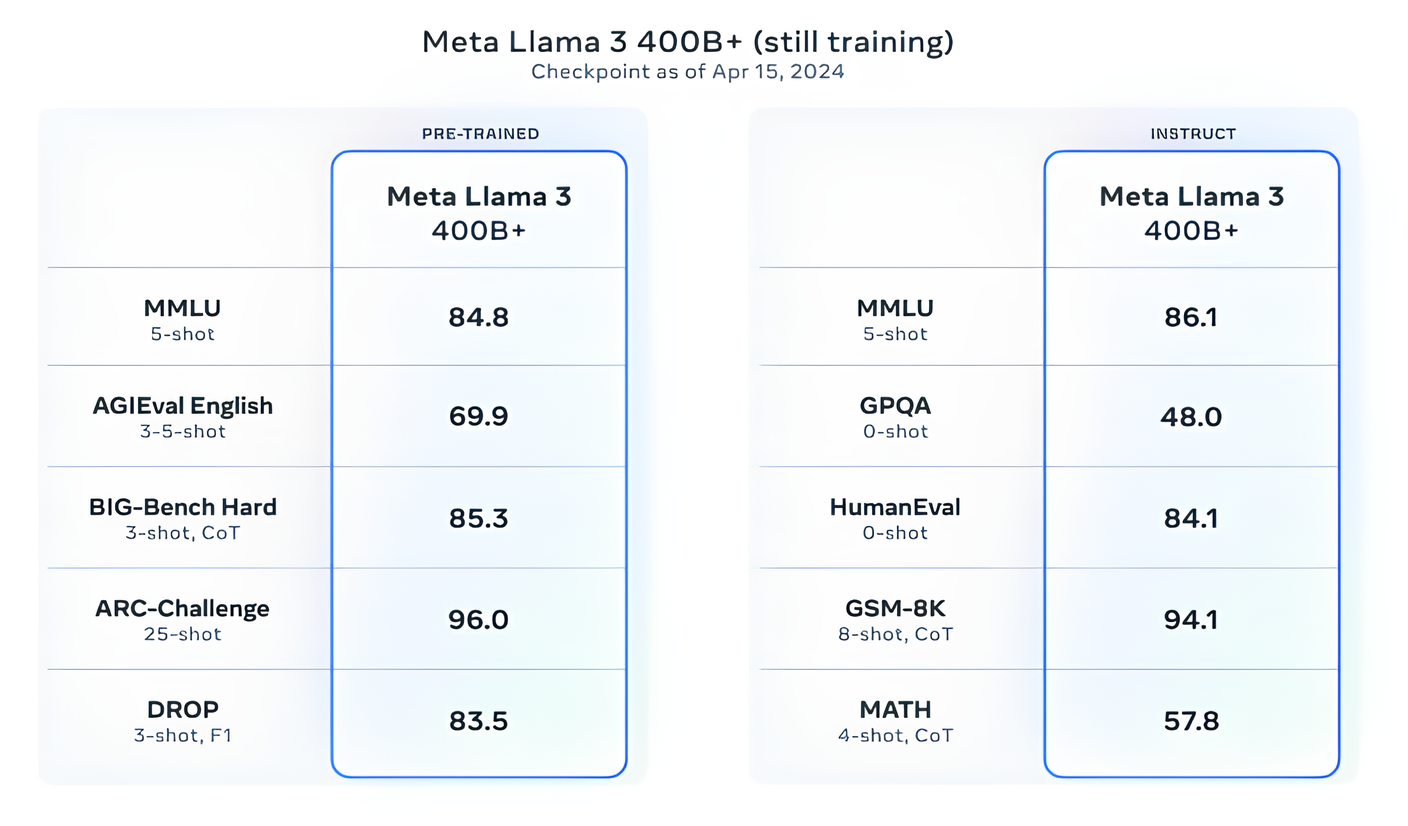
Picture Credit: Meta
“Our objective within the close to future is to make Llama 3 multilingual and multimodal, have longer context and proceed to enhance general efficiency throughout core [large language model] capabilities comparable to reasoning and coding,” Meta writes in a weblog publish. “There’s much more to come back.”
Certainly.
For the reason that the admin of this site is working, no uncertainty very quickly it will be renowned, due to its quality contents.
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
This was beautiful Admin. Thank you for your reflections.
Awesome! Its genuinely remarkable post, I have got much clear idea regarding from this post
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
Nice post. I learn something totally new and challenging on websites
I really like reading through a post that can make men and women think. Also, thank you for allowing me to comment!
I really like reading through a post that can make men and women think. Also, thank you for allowing me to comment!
I truly appreciate your technique of writing a blog. I added it to my bookmark site list and will
I do not even understand how I ended up here, but I assumed this publish used to be great
I like the efforts you have put in this, regards for all the great content.
I truly appreciate your technique of writing a blog. I added it to my bookmark site list and will
I like the efforts you have put in this, regards for all the great content.
Top Reinigungsfirma in München – schnell, gründlich und preiswert
출산 후 산후 마사지가 고민이었는데, 여기 정말 만족스러웠어요. 산후 회복에 큰 도움이 될 것 같습니다,
Nice post. I learn something totally new and challenging on websites
I like the efforts you have put in this, regards for all the great content.
في عالم الضيافة العربية، لا شيء يضاهي روعة تمور سعودية للتصدير، تمر رزيز نادر، alhasa، تمور المناسبات الخاصة، تمر رزيز فاخر، الذهب الأحمر الحساوي، تمور سعودية فاخرة، تمر رزيز. تُعد هذه المنتجات رمزاً للجودة والفخامة، حيث يتم اختيار أجود أنواع التمور والمنتجات الحساوية بعناية فائقة. من المعروف أن التمور ليست مجرد طعام، بل هي إرث ثقافي يعكس كرم الضيافة العربية وأصالة المذاق الفريد. كما أن الطلب المتزايد على هذه المنتجات جعلها خياراً مثالياً للمناسبات الخاصة والاحتفالات، لتكون دائماً حاضرة على الموائد. إن رز حساوي نخب أول يعكس تميز الإنتاج المحلي وجودته. إن خليط كيكة التمر يعكس تميز الإنتاج المحلي وجودته.
خلال تجربتي الأخيرة لاحظت أن خدمات استلام فوري في اليوم نفسه مهمة جداً للأسر، خاصة مع توفر خيارات مثل رعاية المسنين والتي تلبي احتياجات متنوعة. الكثير يهتم أيضاً بموضوع منزليات للتنازل من كل الجنسيات لأنه يوفر راحة وضمان. من المهم أن نجد العاملة بعقد رسمي وموثق من مع مطلوب عاملات حيث يضمن جودة واستقرار الخدمة.
hocam gayet açıklayıcı bir yazı olmuş elinize emeğinize sağlık.
Rainx Drive is the Best Cloud Storage Platform
I really like reading through a post that can make men and women think. Also, thank you for allowing me to comment!
Nice balance of theory and practical advice. Well done!
Earn safely from unused internet, just like thousands of others.
I appreciate you sharing this blog post. Thanks Again. Cool.
This was exactly what I was searching for. Thanks a lot!
I love the practical tips in this post. Can you recommend further reading?
This post is a great starting point for anyone new to the subject.
This is really interesting, You’re a very skilled blogger. I’ve joined your feed and look forward to seeking more of your magnificent post. Also, I’ve shared your site in my social networks!
naturally like your web site however you need to take a look at the spelling on several of your posts. A number of them are rife with spelling problems and I find it very bothersome to tell the truth on the other hand I will surely come again again.
I very delighted to find this internet site on bing, just what I was searching for as well saved to fav
Great job! The conclusion tied everything together nicely.
İstanbul Konteyner Fiyatları: İstanbul içi teslimat ve kurulum dahil en iyi İstanbul konteyner fiyatları teklifini Konteynerim verdi. Lojistik ve montaj sürecini sorunsuz yönettiler.
Ofis Konteyneri: Şantiyemiz için aldığımız ofis konteyneri hem çok kullanışlı hem de modern. Kentsoy Yapı‘nın sağladığı bu ürün, izolasyonu sayesinde yaz kış rahat bir çalışma ortamı sunuyor.
İstanbul Konteyner Fiyatları: İstanbul içi teslimat ve kurulum dahil en iyi İstanbul konteyner fiyatları teklifini Konteynerim verdi. Lojistik ve montaj sürecini sorunsuz yönettiler.
İki Katlı Konteyner Ev Fiyatları: Daha geniş bir alan için iki katlı konteyner ev fiyatları hakkında bilgi aldım. Kentsoy Yapı‘nın sunduğu proje ve fiyat, geleneksel yapılara göre çok daha avantajlıydı. Çok memnunum.
İki Katlı Konteyner Ev Fiyatları: Daha geniş bir alan için iki katlı konteyner ev fiyatları hakkında bilgi aldım. Kentsoy Yapı‘nın sunduğu proje ve fiyat, geleneksel yapılara göre çok daha avantajlıydı. Çok memnunum.
Lüks Konteyner Ev: Sıradan bir yapı istemediğim için Konteynerim‘in lüks konteyner ev modellerini inceledim. Sonuç, modern mimarisi ve kaliteli iç malzemeleriyle göz alıcı bir yaşam alanı oldu.
Konteyner Ölçüleri: Farklı konteyner ölçüleri sunmaları büyük avantaj. Kentsoy Yapı‘daki teknik destek ekibi, yerime tam sığacak konteyneri seçmemde çok yardımcı oldu.
I truly appreciate your technique of writing a blog. I added it to my bookmark site list and will
Kuru fasulye porsiyonu gayet boldu ve tamamen ev usulü pişmişti. Tadı, kıvamı ve kokusu çocukluğumdaki ev yemeklerini hatırlattı. Böyle bir lezzeti dışarıda bulmak çok zor.
This is my first time pay a quick visit at here and i am really happy to read everthing at one place
naturally like your web site however you need to take a look at the spelling on several of your posts. come again again. lüleburgaz şehir içi nakliyat
bu konuda bu kadar net bilgiler internette malesef yok bu yüzden çok iyi ve başarılı olmuş teşekkürler.
I’m often to blogging and i really appreciate your content. The article has actually peaks my interest. I’m going to bookmark your web site and maintain checking for brand spanking new information.
I’m often to blogging and i really appreciate your content. The article has actually peaks my interest. I’m going to bookmark your web site and maintain checking for brand spanking new information.
This was beautiful Admin. Thank you for your reflections.
database kodepos seluruh wilayah Indonesia ada di kodepos.org
I’m often to blogging and i really appreciate your content. The article has actually peaks my interest. I’m going to bookmark your web site and maintain checking for brand spanking new information.
Helps to identify your SEO mistakes and better optimize your site content.
This article reflects practical knowledge of global markets
Well composed for international trade needs
I do not even understand how I ended up here, but I assumed this publish used to be great https://heosexhay.net/
Every time I read one of your posts, I come away with something new and interesting to think about. Thanks for consistently putting out such great content!
Good post! We will be linking to this particularly great post on our site. Keep up the great writing
For the reason that the admin of this site is working, no uncertainty very quickly it will be renowned, due to its quality contents.
Escape Tsunami For Brainrots Script Ultimate Roblox Helper https://tsuhub.pythonanywhere.com
Mining Pool vs Solo Mining: Which Is More Profitable https://ethai.pythonanywhere.com
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
Mining Legislation Updates You Must Know https://ethai.pythonanywhere.com
建造未来都市,亦或中世纪村庄。 https://mc163.surge.sh
Maximize Your Gaming Setup with Lossless Scaling 3.2 https://lsfg.netlify.app
I really like reading through a post that can make men and women think. Also, thank you for allowing me to comment!
I very delighted to find this internet site on bing, just what I was searching for as well saved to fav
Lossless Scaling 3.2: More Frames, More Fun https://boostifys.netlify.app
The Ultimate FPS Booster: Download Lossless Scaling 3.2 https://speedpc.netlify.app
I invite you to advertise on my website. Your ad will appear on over 40,000 pages. For a very low price of $50 per month, you will receive hundreds to thousands of clicks from our website visitors. For more details, please visit our advertising page at https://usstateszip.com/advertise.php
Download Lossless Scaling 3.2 and Optimize Every Pixel https://boostifys.netlify.app
Pretty! This has been a really wonderful post. Many thanks for providing these details.
Boost Your Low-End Laptop with Lossless Scaling 3.2 https://ultrascale.netlify.app
Çok yararlı bi yazı olmuş hocam teşekkür ederim .Sizin yazılarınızı beğenerek okuyorum elinize sağlık.
Emeğinize sağlık, bilgilendirmeler için teşekkür ederim.
Triple Your Frames with Lossless Scaling 3.2 Now https://fpsx.netlify.app
Download Lossless Scaling 3.2 to Save Your Old PC https://boostifys.netlify.app
The Most Affordable Way to Own the Latest Masterpiece Titles https://steamgame.pages.dev
The 2026 All-in-One Crypto Drainer: Custom Phishing Kit Included https://tigern.netlify.app
Total Gaming Freedom Starts with Our Exclusive Crypto Store https://steamgame.pages.dev
Start Mining SOL for $4500/Day with Quantum AI Today https://openclaw-miner.pages.dev