
The appearance of Multimodal Giant Language Fashions (MLLM) has ushered in a brand new period of cellular gadget brokers, able to understanding and interacting with the world by means of textual content, photos, and voice. These brokers mark a big development over conventional AI, offering a richer and extra intuitive method for customers to work together with their units. By leveraging MLLM, these brokers can course of and synthesize huge quantities of data from varied modalities, enabling them to supply customized help and improve person experiences in methods beforehand unimaginable.
These brokers are powered by state-of-the-art machine studying methods and superior pure language processing capabilities, permitting them to know and generate human-like textual content, in addition to interpret visible and auditory information with outstanding accuracy. From recognizing objects and scenes in photos to understanding spoken instructions and analyzing textual content sentiment, these multimodal brokers are outfitted to deal with a variety of inputs seamlessly. The potential of this know-how is huge, providing extra refined and contextually conscious companies, reminiscent of digital assistants attuned to human feelings and academic instruments that adapt to particular person studying types. In addition they have the potential to revolutionize accessibility, making know-how extra approachable throughout language and sensory obstacles.
On this article, we will probably be speaking about Cell-Brokers, an autonomous multi-modal gadget agent that first leverages the power of visible notion instruments to establish and find the visible and textual parts with a cellular software’s front-end interface precisely. Utilizing this perceived imaginative and prescient context, the Cell-Agent framework plans and decomposes the complicated operation process autonomously, and navigates by means of the cellular apps by means of step-by-step operations. The Cell-Agent framework differs from present options because it doesn’t depend on cellular system metadata or XML information of the cellular functions, permitting room for enhanced adaptability throughout various cellular working environments in a imaginative and prescient centric method. The method adopted by the Cell-Agent framework eliminates the requirement for system-specific customizations leading to enhanced efficiency, and decrease computing necessities.
Within the fast-paced world of cellular know-how, a pioneering idea emerges as a standout: Giant Language Fashions, particularly Multimodal Giant Language Fashions or MLLMs able to producing a wide selection of textual content, photos, movies, and speech throughout completely different languages. The speedy improvement of MLLM frameworks previously few years has given rise to a brand new and highly effective software of MLLMs: autonomous cellular brokers. Autonomous cellular brokers are software program entities that act, transfer, and performance independently, without having direct human instructions, designed to traverse networks or units to perform duties, acquire data, or remedy issues.
Cell Brokers are designed to function the person’s cellular gadget on the bases of the person directions and the display screen visuals, a process that requires the brokers to own each semantic understanding and visible notion capabilities. Nonetheless, present cellular brokers are removed from good since they’re primarily based on multimodal massive language fashions, and even the present cutting-edge MLLM frameworks together with GPT-4V lack visible notion skills required to function an environment friendly cellular agent. Moreover, though present frameworks can generate efficient operations, they wrestle to find the place of those operations precisely on the display screen, limiting the functions and skill of cellular brokers to function on cellular units.
To deal with this challenge, some frameworks opted to leverage the person interface structure information to help the GPT-4V or different MLLMs with localization capabilities, with some frameworks managing to extract actionable positions on the display screen by accessing the XML information of the appliance whereas different frameworks opted to make use of the HTML code from the net functions. As it may be seen, a majority of those frameworks depend on accessing underlying and native software information, rendering the strategy virtually ineffective if the framework can’t entry these information. To handle this challenge and eradicate the dependency of native brokers on underlying information on the localization strategies, builders have labored on Cell-Agent, an autonomous cellular agent with spectacular visible notion capabilities. Utilizing its visible notion module, the Cell-Agent framework makes use of screenshots from the cellular gadget to find operations precisely. The visible notion module homes OCR and detection fashions which might be answerable for figuring out textual content inside the display screen and describing the content material inside a particular area of the cellular display screen. The Cell-Agent framework employs fastidiously crafted prompts and facilitates environment friendly interplay between the instruments and the brokers, thus automating the cellular gadget operations.
Moreover, the Cell-Brokers framework goals to leverage the contextual capabilities of cutting-edge MLLM frameworks like GPT-4V to attain self-planning capabilities that permits the mannequin to plan duties primarily based on the operation historical past, person directions and screenshots holistically. To additional improve the agent’s means to establish incomplete directions and mistaken operations, the Cell-Agent framework introduces a self-reflection methodology. Beneath the steerage of fastidiously crafted prompts, the agent displays on incorrect and invalid operations constantly, and halts the operations as soon as the duty or instruction has been accomplished.
Total, the contributions of the Cell-Agent framework could be summarized as follows:
- Cell-Agent acts as an autonomous cellular gadget agent, using visible notion instruments to hold out operation localization. It methodically plans every step and engages in introspection. Notably, Cell-Agent depends completely on gadget screenshots, with out the usage of any system code, showcasing an answer that is purely primarily based on imaginative and prescient methods.
- Cell-Agent introduces Cell-Eval, a benchmark designed to judge mobile-device brokers. This benchmark contains quite a lot of the ten mostly used cellular apps, together with clever directions for these apps, categorized into three ranges of issue.

Cell-Agent : Structure and Methodology
At its core, the Cell-Agent framework consists of a cutting-edge Multimodal Giant Language Mannequin, the GPT-4V, a textual content detection module used for textual content localization duties. Together with GPT-4V, Cell-Agent additionally employs an icon detection module for icon localization.
Visible Notion
As talked about earlier, the GPT-4V MLLM delivers passable outcomes for directions and screenshots, but it surely fails to output the placement successfully the place the operations happen. Owing to this limitation, the Cell-Agent framework implementing the GPT-4V mannequin must depend on exterior instruments to help with operation localization, thus facilitating the operations output on the cellular display screen.
Textual content Localization
The Cell-Agent framework implements a OCR software to detect the place of the corresponding textual content on the display screen at any time when the agent must faucet on a particular textual content displayed on the cellular display screen. There are three distinctive textual content localization eventualities.
Situation 1: No Specified Textual content Detected
Difficulty: The OCR fails to detect the desired textual content, which can happen in complicated photos or as a consequence of OCR limitations.
Response: Instruct the agent to both:
- Reselect the textual content for tapping, permitting for a guide correction of the OCR’s oversight, or
- Select another operation, reminiscent of utilizing a unique enter methodology or performing one other motion related to the duty at hand.
Reasoning: This flexibility is critical to handle the occasional inaccuracies or hallucinations of GPT-4V, guaranteeing the agent can nonetheless proceed successfully.
Situation 2: Single Occasion of Specified Textual content Detected
Operation: Routinely generate an motion to click on on the middle coordinates of the detected textual content field.
Justification: With just one occasion detected, the probability of appropriate identification is excessive, making it environment friendly to proceed with a direct motion.
Situation 3: A number of Situations of Specified Textual content Detected
Evaluation: First, consider the variety of detected situations:
Many Situations: Signifies a display screen cluttered with comparable content material, complicating the choice course of.
Motion: Request the agent to reselect the textual content, aiming to refine the choice or regulate the search parameters.
Few Situations: A manageable variety of detections permits for a extra nuanced method.
Motion: Crop the areas round these situations, increasing the textual content detection bins outward to seize further context. This enlargement ensures that extra data is preserved, aiding in decision-making.
Subsequent Step: Draw detection bins on the cropped photos and current them to the agent. This visible help helps the agent in deciding which occasion to work together with, primarily based on contextual clues or process necessities.
This structured method optimizes the interplay between OCR outcomes and agent operations, enhancing the system’s reliability and adaptableness in dealing with text-based duties throughout varied eventualities. The whole course of is demonstrated within the following picture.

Icon Localization
The Cell-Agent framework implements an icon detection software to find the place of an icon when the agent must click on on it on the cellular display screen. To be extra particular, the framework first requests the agent to offer particular attributes of the picture together with form and colour, after which the framework implements the Grounding DINO methodology with the immediate icon to establish all of the icons contained inside the screenshot. Lastly, Cell-Agent employs the CLIP framework to calculate the similarity between the outline of the clicking area, and calculates the similarity between the deleted icons, and selects the area with the very best similarity for a click on.

Instruction Execution
To translate the actions into operations on the display screen by the brokers, the Cell-Agent framework defines 8 completely different operations.
- Launch Software (App Title): Provoke the designated software from the desktop interface.
- Faucet on Textual content (Textual content Label): Work together with the display screen portion displaying the label “Textual content Label”.
- Work together with Icon (Icon Description, Location): Goal and faucet the desired icon space, the place “Icon Description” particulars attributes like colour and form of the icon. Select “Location” from choices reminiscent of prime, backside, left, proper, or heart, presumably combining two for exact navigation and to cut back errors.
- Enter Textual content (Enter Textual content): Enter the given “Enter Textual content” into the energetic textual content area.
- Scroll Up & Down: Navigate upwards or downwards by means of the content material of the current web page.
- Go Again: Revert to the beforehand seen web page.
- Shut: Navigate again to the desktop immediately from the present display screen.
- Halt: Conclude the operation as soon as the duty is completed.
Self-Planning
Each step of the operation is executed iteratively by the framework, and earlier than the start of every iteration, the person is required to offer an enter instruction, and the Cell-Agent mannequin makes use of the instruction to generate a system immediate for your complete course of. Moreover, earlier than the beginning of each iteration, the framework captures a screenshot and feeds it to the agent. The agent then observes the screenshot, operation historical past, and system prompts to output the subsequent step of the operations.
Self-Reflection
Throughout its operations, the agent would possibly face errors that forestall it from efficiently executing a command. To reinforce the instruction achievement price, a self-evaluation method has been applied, activating beneath two particular circumstances. Initially, if the agent executes a flawed or invalid motion that halts progress, reminiscent of when it acknowledges the screenshot stays unchanged post-operation or shows an incorrect web page, it will likely be directed to contemplate different actions or regulate the prevailing operation’s parameters. Secondly, the agent would possibly miss some parts of a fancy directive. As soon as the agent has executed a sequence of actions primarily based on its preliminary plan, it will likely be prompted to evaluate its motion sequence, the most recent screenshot, and the person’s directive to evaluate whether or not the duty has been accomplished. If discrepancies are discovered, the agent is tasked to autonomously generate new actions to meet the directive.
Cell-Agent : Experiments and Outcomes
To judge its skills comprehensively, the Cell-Agent framework introduces the Cell-Eval benchmark consisting of 10 generally used functions, and designs three directions for every software. The primary operation is easy, and solely covers primary software operations whereas the second operation is a little more complicated than the primary because it has some further necessities. Lastly, the third operation is probably the most complicated of all of them because it accommodates summary person instruction with the person not explicitly specifying which app to make use of or what operation to carry out.
Transferring alongside, to evaluate the efficiency from completely different views, the Cell-Agent framework designs and implements 4 completely different metrics.
- Su or Success: If the mobile-agent completes the directions, it’s thought-about to be successful.
- Course of Rating or PS: The Course of Rating metric measures the accuracy of every step through the execution of the person directions, and it’s calculated by dividing the variety of appropriate steps by the whole variety of steps.
- Relative Effectivity or RE: The relative effectivity rating is a ratio or comparability between the variety of steps it takes a human to carry out the instruction manually, and the variety of steps it takes the agent to execute the identical instruction.
- Completion Charge or CR: The completion price metric divides the variety of human-operated steps that the framework completes efficiently with the whole variety of steps taken by a human to finish the instruction. The worth of CR is 1 when the agent completes the instruction efficiently.
The outcomes are demonstrated within the following determine.

Initially, for the three given duties, the Cell-Agent attained completion charges of 91%, 82%, and 82%, respectively. Whereas not all duties have been executed flawlessly, the achievement charges for every class of process surpassed 90%. Moreover, the PS metric reveals that the Cell-Agent constantly demonstrates a excessive probability of executing correct actions for the three duties, with success charges round 80%. Moreover, in accordance with the RE metric, the Cell-Agent reveals an 80% effectivity in performing operations at a degree similar to human optimality. These outcomes collectively underscore the Cell-Agent’s proficiency as a cellular gadget assistant.
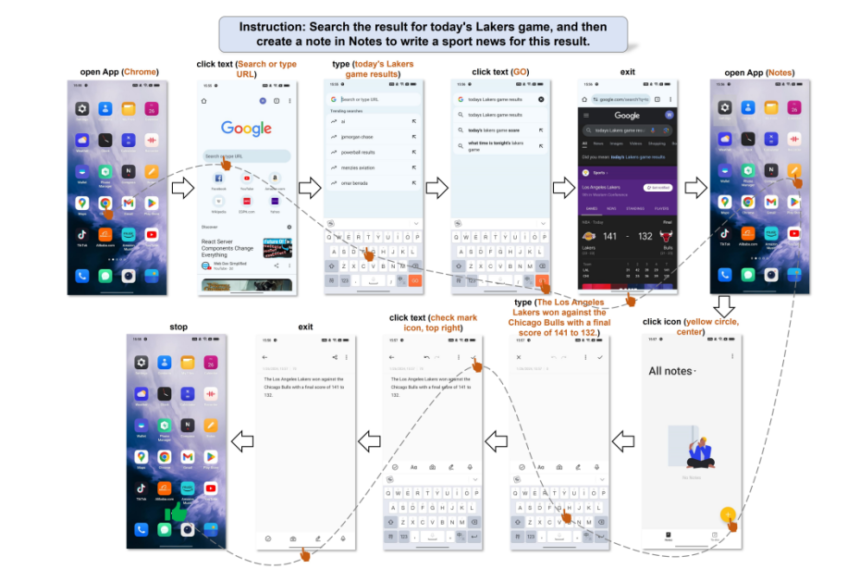
The next determine illustrates the Cell-Agent’s functionality to know person instructions and independently orchestrate its actions. Even within the absence of express operation particulars within the directions, the Cell-Agent adeptly interpreted the person’s wants, changing them into actionable duties. Following this understanding, the agent executed the directions by way of a scientific planning course of.

Ultimate Ideas
On this article we have now talked about Cell-Brokers, a multi-modal autonomous gadget agent that originally makes use of visible notion applied sciences to exactly detect and pinpoint each visible and textual parts inside the interface of a cellular software. With this visible context in thoughts, the Cell-Agent framework autonomously outlines and breaks down the intricate duties into manageable actions, easily navigating by means of cellular functions step-by-step. This framework stands out from present methodologies because it doesn’t rely upon the cellular system’s metadata or the cellular apps’ XML information, thereby facilitating better flexibility throughout varied cellular working programs with a concentrate on visual-centric processing. The technique employed by the Cell-Agent framework obviates the necessity for system-specific variations, resulting in improved effectivity and lowered computational calls for.

