
Latest developments in Giant Imaginative and prescient Language Fashions (LVLMs) have proven that scaling these frameworks considerably boosts efficiency throughout a wide range of downstream duties. LVLMs, together with MiniGPT, LLaMA, and others, have achieved exceptional capabilities by incorporating visible projection layers and a picture encoder into their structure. By implementing these parts, LVLMs improve the visible notion capabilities of Giant Language Fashions (LLMs). Efficiency might be additional improved by rising the mannequin’s measurement and variety of parameters, in addition to increasing the dataset scale.
Fashions like InternVL have expanded their picture encoder to over 6 billion parameters, whereas others have prolonged the backend of LVLMs to 13 billion parameters, reaching superior efficiency on a big selection of duties. IDEFICS has skilled an LVLM with over 80 billion parameters. These scaling strategies have matched or exceeded the efficiency of LLMs pretrained on over 34, 70, and even 100 billion parameters. Nonetheless, scaling has a draw back: it considerably will increase coaching and inference prices. It’s because it requires all parameters to be lively for every token in calculation, resulting in excessive computational wants and, consequently, increased prices.
This text discusses MoE-LLaVA, a Combination of Consultants (MoE)-based sparse LVLM structure that employs an efficient coaching technique, MoE-Tuning, for LVLMs. MoE-Tuning innovatively addresses efficiency degradation in multi-modal sparsity studying, leading to a mannequin with a lot of parameters however constant coaching and inference prices. The MoE-LLaVA structure is designed to activate solely the top-k consultants throughout deployment, conserving the remaining inactive.
We purpose to completely discover the MoE-LLaVA framework, inspecting its mechanism, methodology, structure, and the way it compares with main picture and video era frameworks. Let’s delve into the small print.
Along with leveraging visible projection layers and picture encoders, Giant Imaginative and prescient Language Fashions additionally scale up the mannequin measurement by rising the variety of parameters to boost the efficiency of the mannequin. Some notable examples of Giant Imaginative and prescient Language Fashions which have adopted this method to boost their efficiency are MiniGPT-4, InternGPT, InternVL, and others. In real-world purposes, scaling a Giant Language Mannequin or a Giant Imaginative and prescient Language Mannequin with high-quality coaching information typically turns into a necessity to enhance the efficiency of the mannequin. Though scaling a mannequin measurement does enhance the efficiency, it additionally will increase the computational prices of coaching and deploying the mannequin, and additional will increase the problems and effectivity of deploying the mannequin on parallel gadgets concurrently. A significant cause behind the elevated coaching and inference prices together with computational necessities is that every token within the framework calls for computation with each single parameter inside the mannequin referred to as the dense mannequin.
Alternatively, sparse MoE or Combination of Knowledgeable Fashions have demonstrated efficient scaling of frameworks by processing information with the assistance of mounted activated parameters, an method that has been broadly adopted within the Pure Language Processing discipline. Nonetheless, utilizing Combination of Knowledgeable to coach sparse Giant Imaginative and prescient Language Fashions straight is difficult since changing LLMs to LVLMs and sparsifying the mannequin concurrently ends in important efficiency degradation. To implement Combination of Fashions to scale LLMs and LVLMs, it’s important to first initialize the LVLM for sparsification. To realize this, the MoE-LLaVA framework introduces MoE-Tuning, a easy but efficient three section coaching technique.

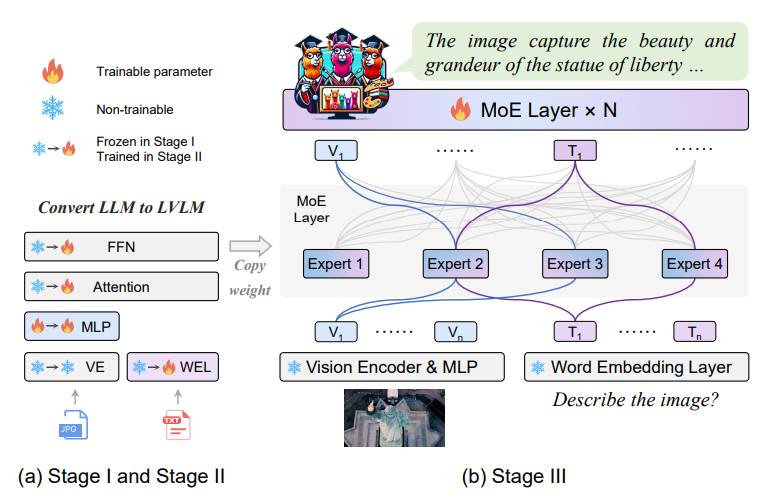
As proven within the above determine, the MoE-Tuning course of first trains a MLP or a Multilayer Perceptron that adapts the visible tokens to a Giant Language Mannequin within the first stage. The framework then trains your entire parameters of the LLM to pre-empower the Giant Imaginative and prescient Language Mannequin with a common multi-modal understanding capabilities. Lastly, within the third stage, the framework replicates the FFN or Feed Ahead Community because the initialization weights for the consultants, and trains solely the Combination of Knowledgeable layers. General, the coaching course of helps within the gradual transition of the sparse mannequin from a LVLM initialization to a sparse combination of professional fashions.
With the coaching course of being lined, allow us to shine some mild on MoE-LLaVA, a baseline for Giant Imaginative and prescient Language Fashions with Combination of Knowledgeable fashions that includes learnable routers and MoE fashions. At its core, the MoE-LLaVA mannequin consists of a number of sparse paths, and the framework makes use of these paths to dispatch every token to completely different consultants via the learnable router. The tokens are then processed collectively by the activated consultants whereas conserving the inactive paths silent. The framework then stacks the Combination of Knowledgeable encoder layers iteratively to offer a sparse path in direction of a bigger and extra highly effective LVLM.

Due to the method carried out by the MoE-LLaVA framework, it is ready to outperform fashions with the same variety of activated parameters, and surpass them by a big distinction on the POPE object hallucination benchmark, regardless of having solely 2.2 billion parameters. Moreover, the MoE-LLaVA framework with 2.2 billion parameters, is ready to obtain efficiency similar to the InternVL-Chat-19B framework with practically 8 instances the variety of activated parameters.
Moreover, highly effective Giant Language Fashions with robust generalization and instruction following capabilities have been carried out to Giant Imaginative and prescient Language Fashions. Early LLMs like BLIP encoded visible indicators right into a sequence of visible tokens permitting them to adapt imaginative and prescient to LLMs efficiently utilizing a number of projection layers. On the identical time, latest works deal with bettering the mannequin efficiency by implementing strategies like increasing the instruction-tuning dataset, rising the decision of the picture, optimizing coaching methods, aligning the enter, enhancing the picture encoders, and way more. These approaches have helped empower LVLMs with highly effective visible understanding capabilities by increasing the visible instruction fine-tuning dataset and mannequin scales. Moreover, some LVLMs additionally possess fine-grained picture understanding capabilities reminiscent of area and multi-region understanding together with pixel-wise grounding capabilities. Nonetheless, the computational value accompanied with scaling up dense visible information and fashions is usually considerably excessive which makes it difficult to put on. Alternatively, the MoE-LLaVA framework goals to make LVLM analysis extra inexpensive by leveraging the capabilities of MoE fashions.
MoE-LLaVA : Technique and Structure
At its core, the MoE-LLaVA framework consists of a visible projection layer (Multilayer Perceptron), a imaginative and prescient encoder, MoE blocks, a number of stacked LLM blocks, and a phrase embedding layer.

Structure
The next desk summarizes the detailed configurations of the MoE-LLaVA framework.

For a given RGB picture, the imaginative and prescient encoder processes the photographs to acquire a sequence of visible tokens with a visible projection layer mapping the visible token sequence to enter photos. The textual content inputs are processed by the phrase embedding layer that then initiatives it to acquire the sequence tokens. On the identical time, the MoE-LLaVA framework concatenates the textual content and visible tokens collectively, and feeds them to the LLM. Nonetheless, the framework solely trains the visible projection layer with the big language mannequin consisting of FFN or Feedforward Neural Networks, and Multi-Head Self Consideration Layers. Lastly, the framework applies residual connections and layer normalization to every block.
Transferring alongside, the MoE-LLaVA framework replicates the FFN or Feedforward Neural Networks from the second stage to type an ensemble of consultants because the initialization step. The router being a linear layer, predicts the likelihood of every token being assigned to every professional. Every token is processed by the top-k consultants with the utmost likelihood, and calculates the weighted sum based mostly on the softmax results of the chances.
MoE-Tuning
MoE-Tuning is a straightforward but efficient three section coaching technique that first trains a MLP or a Multilayer Perceptron that adapts the visible tokens to a Giant Language Mannequin within the first stage. The framework then trains your entire parameters of the LLM to pre-empower the Giant Imaginative and prescient Language Mannequin with a common multi-modal understanding capabilities. Lastly, within the third stage, the framework replicates the FFN or Feed Ahead Community because the initialization weights for the consultants, and trains solely the Combination of Knowledgeable layers.
Stage 1
Within the first stage, the first goal is to adapt the picture tokens to the big language mannequin that enables the LLM to grasp the cases within the picture. The MoE-LLaVA framework employs a multilayer perceptron to undertaking the picture tokens into the enter area of the big language mannequin, and treats picture patches as pseudo-text tokens. On this stage, the MoE-LLaVA framework trains the LLM to explain the photographs, and doesn’t apply the MoE layers to the LLM throughout this stage.
Stage 2
Within the second stage, the MoE-LLaVA makes an attempt to boost the capabilities and controllability of the framework by tuning the mannequin with multi-modal instruction information. The MoE-LLaVA framework achieves this by adjusting the LLM to turn into a LVLM with multi-modal understanding capabilities. The framework employs extra complicated directions together with textual content recognition and logical picture reasoning duties that require the mannequin to own stronger multi-modal capabilities. Historically, the coaching course of for dense fashions is taken into account to be full by this step. Nonetheless, the MoE-LLaVA framework encountered challenges in reworking the LLM right into a LVLM concurrently with sparsifying the LVLM. To counter this problem, the framework makes use of the weights from the stage as initialization for the following stage in an try to alleviate the training problem of the sparse mannequin.
Stage 3
Within the third step, the mannequin replicates the feedforward neural community a number of instances to initialize the consultants as an initialization process. The framework then feeds the textual content and picture tokens into the combination of professional layers following which the router calculates the matching weights between consultants and every tokens. Every token is then processed by the top-k consultants with the aggregated output calculated by weighted summation based mostly on the weights of the router. As soon as the top-k consultants are activated, the mannequin shuts the remaining consultants, an method that equips the MoE-LLaVA framework with infinitely attainable sparse paths, thus equipping the mannequin with a variety of capabilities.
MoE-LLaVA : Outcomes and Experiments
The MoE-LLaVA framework adopts CLIP-Giant because the imaginative and prescient encoder with the Multilayer Perceptron consisting of two layers with a GELU activation layer separating the 2. By default, the framework employs an alternating alternative of the feedforward neural networks with the combination of professional layers, which means the combination of professional layers comprise 50% of the entire variety of layers. The next desk comprises the completely different datasets together with their pattern measurement used to coach and consider the MoE-LLaVA framework.

Zero-Shot Picture Query Answering
The next determine demonstrates that MoE-LLaVA is a sparse mannequin with a delicate router based mostly on LVLM. The framework is evaluated on 5 picture query answering benchmarks, and as it may be noticed, the MoE-LLaVA framework demonstrates exceptional picture understanding capabilities, and delivers comparable efficiency to the state-of-the-art LLaVA 1.5 framework on 5 completely different benchmarks.

Object Hallucination Analysis
To guage object hallucination, the MoE-LLaVA framework adopts the POPE analysis pipeline, a polling-based question methodology, and the outcomes are demonstrated within the following desk. As it may be noticed, out of all of the frameworks, the MoE-LLaVA delivers the strongest outcomes, indicating the power of the framework to generate objects in line with the enter picture. Moreover, it’s value noting that the MoE-LLaVA framework balances the sure ratio effectively, indicating the aptitude of the sparse mannequin to offer correct suggestions for the given query.

The next picture comprises the distribution of professional loadings, the place the discontinuous traces characterize a effectively balanced distribution of tokens among the many modalities or consultants. The primary determine illustrates the workload inside the consultants whereas the remaining photos show the efficiency of consultants in direction of completely different modalities.

Moreover, the next determine demonstrates the distribution of modalities throughout completely different consultants.

Ultimate Ideas
On this article we now have talked about MoE-LLaVA, a baseline for Giant Imaginative and prescient Language Fashions with Combination of Knowledgeable fashions that includes learnable routers and MoE fashions. At its core, the MoE-LLaVA mannequin consists of a number of sparse paths, and the framework makes use of these paths to dispatch every token to completely different consultants via the learnable router. The tokens are then processed collectively by the activated consultants whereas conserving the inactive paths silent. The framework then stacks the Combination of Knowledgeable encoder layers iteratively to offer a sparse path in direction of a bigger and extra highly effective LVLM. The MoE-Tuning technique addresses the frequent problem of efficiency degradation in multi-modal sparsity studying innovatively, consequently establishing a mannequin with a considerably giant variety of parameters however constant coaching and inference prices. The structure of the MoE-LLaVA framework has been designed in a method that it solely prompts the top-k consultants throughout deployment whereas conserving the remaining consultants inactive.

