
The event and progress of language fashions up to now few years have marked their presence nearly all over the place, not solely in NLP analysis but additionally in business choices and real-world functions. Nonetheless, the surge in business demand for language fashions has, to a sure extent, hindered the expansion of the neighborhood. It’s because a majority of state-of-the-art and succesful fashions are gated behind proprietary interfaces, making it unattainable for the event neighborhood to entry very important particulars of their coaching structure, information, and growth processes. It’s now plain that these coaching and structural particulars are essential for analysis research, together with entry to their potential dangers and biases, thus making a requirement for the analysis neighborhood to have entry to a really open and highly effective language mannequin.
To fulfill this requirement, builders have created OLMo, a state-of-the-art, actually open language mannequin framework. This framework permits researchers to make use of OLMo to construct and research language fashions. In contrast to most state-of-the-art language fashions, which have solely launched interface code and mannequin weights, the OLMo framework is really open supply, with publicly accessible analysis code, coaching strategies, and coaching information. OLMo’s major purpose is to empower and increase the open analysis neighborhood and the continual growth of language fashions.
On this article, we’ll talk about the OLMo framework intimately, analyzing its structure, methodology, and efficiency in comparison with present state-of-the-art frameworks. So, let’s get began.
OLMo: Enhancing the Science of Language Fashions
The language mannequin has arguably been the most well liked pattern for the previous few years, not solely throughout the AI and ML neighborhood but additionally throughout the tech trade, because of its exceptional capabilities in performing real-world duties with human-like efficiency. ChatGPT is a first-rate instance of the potential language fashions maintain, with main gamers within the tech trade exploring language mannequin integration with their merchandise.
NLP, or Pure Language Processing, is likely one of the industries that has extensively employed language fashions over the previous few years. Nonetheless, ever for the reason that trade began using human annotation for alignment and large-scale pre-training, language fashions have witnessed a speedy enhancement of their business viability, leading to a majority of state-of-the-art language and NLP frameworks having restricted proprietary interfaces, with the event neighborhood having no entry to very important particulars.
To make sure the progress of language fashions, OLMo, a state-of-the-art, actually open language mannequin, provides builders a framework to construct, research, and advance the event of language fashions. It additionally gives researchers with entry to its coaching and analysis code, coaching methodology, coaching information, coaching logs, and intermediate mannequin checkpoints. Present state-of-the-art fashions have various levels of openness, whereas the OLMo mannequin has launched the whole framework, from coaching to information to analysis instruments, thus narrowing the efficiency hole when in comparison with state-of-the-art fashions just like the LLaMA2 mannequin.
For modeling and coaching, the OLMo framework contains the coaching code, full mannequin weights, ablations, coaching logs, and coaching metrics within the type of interface code, in addition to Weights & Biases logs. For evaluation and dataset constructing, the OLMo framework contains the complete coaching information used for AI2’s Dolma and WIMBD fashions, together with the code that produces the coaching information. For analysis functions, the OLMo framework contains AI2’s Catwalk mannequin for downstream analysis, and the Paloma mannequin for perplexity-based analysis.
OLMo : Mannequin and Structure
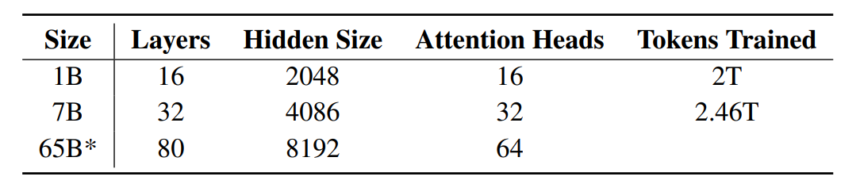
The OLMo mannequin adopts a decoder-only transformer structure primarily based on the Neural Data Processing Methods, and delivers two fashions with 1 billion and seven billion parameters respectively, with a 65 billion parameter mannequin at present underneath growth.

The structure of the OLMo framework delivers a number of enhancements over frameworks together with the vanilla transformer part of their structure together with latest cutting-edge giant language fashions like OpenLM, Falcon, LLaMA, and PaLM. The next determine compares the OLMo mannequin with 7B billion parameters in opposition to latest LLMs working on nearly equal numbers of parameters.

The OLMo framework selects the hyperparameters by optimizing the mannequin for coaching throughput on the {hardware} whereas on the identical time minimizing the danger of gradual divergence and loss spikes. With that being stated, the first modifications applied by the OLMo framework that distinguishes itself from the vanilla transformer structure are as follows:
No Biases
In contrast to Falcon, PaLM, LLaMA and different language fashions, the OLMo framework doesn’t embody any bias in its structure to boost the coaching stability.
Non-Parametric Layer Norm
The OLMo framework implements the non-parametric formulation of the layer norm in its structure. The Non-Parametric Layer Norm provides no affine transformation throughout the norm i.e it doesn’t provide any adaptive acquire or bias. Non-Parametric Layer Norm not solely provides extra safety that Parametric Layer Norms, however they’re additionally sooner.
SwiGLU Activation Perform
Like a majority of language fashions like PaLM and LLaMA, the OLMo framework contains the SwiGLU activation operate in its structure as an alternative of the ReLU activation operate, and will increase the hidden activation dimension to the closest a number of of 128 to enhance throughput.
RoPE or Rotary Positional Embeddings
The OLMo fashions observe the LLaMA and PaLM fashions and swap absolutely the positional embeddings for RoPE or Rotary Positional Embeddings.
Pre Coaching with Dolma
Though the event neighborhood now has enhanced entry to mannequin parameters, the doorways to entry pre-training datasets nonetheless stay shut because the pre-training information is just not launched alongside the closed fashions nor alongside the open fashions. Moreover, technical documentations protecting such information usually lack very important particulars required to totally perceive and replicate the mannequin. The roadblock makes it tough to hold ahead the analysis in sure threads of language mannequin analysis together with the understanding of how the coaching information impacts the capabilities and limitations of the mannequin. The OLMo framework constructed and launched its pre-training dataset, Dolma, to facilitate open analysis on language mannequin pre-training. The Dolma dataset is a multi-source and numerous assortment of over 3 trillion tokens throughout 5 billion paperwork collected from 7 completely different sources which might be generally utilized by highly effective large-scale LLMs for pre-training and are accessible to the final viewers. The composition of the Dolma dataset is summarized within the following desk.
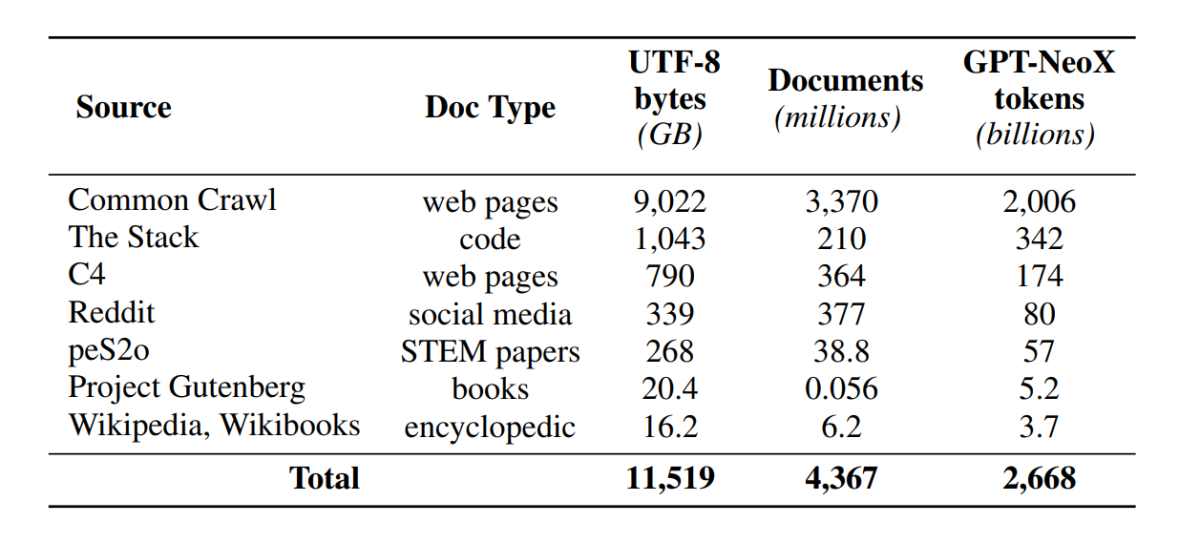
The Dolma dataset is constructed utilizing a pipeline of 5 parts: language filtering, high quality filtering, content material filtering, multi-source mixing, deduplication, and tokenization. OLMo has additionally launched the Dolma report that gives extra insights into the design rules and development particulars together with a extra detailed content material abstract. The mannequin additionally open sources its excessive efficiency information curation instruments to allow simple and fast curation of pre-training information corpora. Analysis of the mannequin follows a two-staged technique, beginning with on-line analysis for decision-making throughout mannequin coaching and a closing offline analysis for an aggregated analysis from mannequin checkpoints. For offline analysis, OLMo makes use of the Catwalk framework, our publicly obtainable analysis instrument that has entry to a broad range of datasets and process codecs. The framework makes use of Catwalk for downstream analysis in addition to intrinsic language modeling analysis on our new perplexity benchmark, Paloma. OLMo then compares it in opposition to a number of public fashions utilizing its fastened analysis pipeline, for each downstream and perplexity analysis.
OLMo runs a number of analysis metrics concerning the mannequin structure, initialization, optimizers, studying price schedule, and mixtures of information in the course of the coaching of the mannequin. Builders name it OLMo’s “on-line analysis” in that it’s an in-loop iteration at each 1000 coaching steps (or ∼4B coaching tokens) to offer an early and steady sign on the standard of the mannequin being educated. The setup of those evaluations is determined by a majority of core duties and experiment settings used for our offline analysis. OLMo goals for not simply comparisons of OLMo-7B in opposition to different fashions for finest efficiency but additionally to point out the way it permits fuller and extra managed scientific analysis. OLMo-7B is the largest Language Mannequin with specific decontamination for perplexity analysis.
OLMo Coaching
It is essential to notice that the OLMo framework fashions are educated utilizing the ZeRO optimizer technique, which is offered by the FSDP framework by PyTorch and, on this means, considerably reduces GPU reminiscence consumption by sharding mannequin weights over GPUs. With this, on the 7B scale, coaching might be accomplished with a micro-batch dimension of 4096 tokens per GPU on our {hardware}. The coaching framework for OLMo-1B and -7B fashions makes use of a globally fixed batch dimension of about 4M tokens (2048 situations every with a sequence size of 2048 tokens). For the mannequin OLMo-65B (at present in coaching), builders use a batch dimension warmup that begins at about 2M tokens (1024 situations), doubling each 100B tokens till about 16M tokens (8192 situations).
To enhance throughput, we make use of mixed-precision coaching (Micikevicius et al., 2017) by FSDP’s built-in settings and PyTorch’s amp module. The latter ensures that sure operations just like the softmax all the time run in full precision to enhance stability, whereas all different operations run in half-precision with the bfloat16 format. Beneath our particular settings, the sharded mannequin weights and optimizer state native to every GPU are stored in full precision. The weights inside every transformer block are solely forged to bfloat16 format when the full-sized parameters are materialized on every GPU in the course of the ahead and backward passes. Gradients are lowered throughout GPUs in full precision.
Optimizer
The OLMo framework makes use of the AdamW optimizer with the next hyperparameters.

For all mannequin sizes, the training price warms up linearly over the primary 5000 steps (∼21B tokens) to a most worth, after which decays linearly with the inverse sq. root of the step quantity to the desired minimal studying price. After the warm-up interval, the mannequin clips gradients such that the full l-norm of the parameter gradients doesn’t exceed 1.0. The next desk provides a comparability of our optimizer settings on the 7B scale with these from different latest LMs that additionally used AdamW.

Coaching Information
Coaching entails tokenizing coaching situations by phrase and BPE tokenizer for the sentence piece mannequin after including a particular EOS token on the finish of every doc, after which we group consecutive chunks of 2048 tokens to type coaching situations. Coaching situations are shuffled in the very same means for every coaching run. The information order and actual composition of every coaching batch might be reconstructed from the artifacts we launch. All the launched OLMo fashions have been educated to no less than 2T tokens (a single epoch over its coaching information), and a few had been educated past that by beginning a second epoch over the information with a distinct shuffling order. Given the small quantity of information that this repeats, it ought to have a negligible impact.
Outcomes
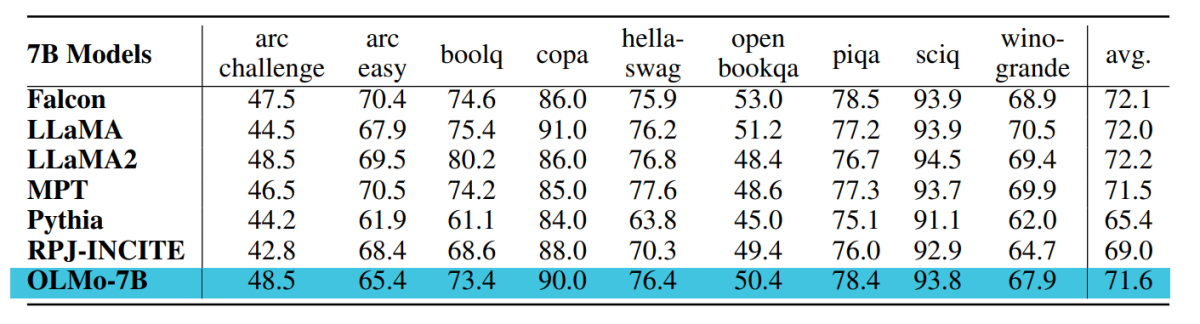
The checkpoint used for analysis of OLMo-7B is educated as much as 2.46T tokens on the Dolma information set with the linear studying price decay schedule talked about earlier than. Additional tuning this checkpoint on the Dolma dataset for 1000 steps with linearly decayed studying price to 0 additional will increase mannequin efficiency on perplexity and end-task analysis suites described earlier than. For the ultimate analysis, builders in contrast OLMo with different publicly obtainable fashions – LLaMA-7B, LLaMA2-7B, Pythia-6.9B, Falcon-7B and RPJ-INCITE-7B.
Downstream analysis
The core downstream analysis suite is summarized within the following desk.
We conduct zero-shot analysis by rank classification strategy in all circumstances. On this strategy, the candidate textual content completions (e.g., completely different multiple-choice choices) are ranked by chance (normally normalized by some normalization issue), and prediction accuracy is reported.
Whereas Catwalk makes use of a number of typical chance normalization strategies, corresponding to per token normalization and per-character normalization, the normalization methods utilized are chosen individually for every dataset and embody the answer is unconditional chance. Extra concretely, this concerned no normalization for the arc and openbookqa duties, per-token normalization for hellaswag, piqa, and winogrande duties, and no normalization for boolq, copa, and sciq duties (i.e., duties in a formulation near a single token prediction process).

The next determine exhibits the progress of accuracy rating for the 9 core end-tasks. It may be deduced that there’s a usually rising pattern within the accuracy quantity for all duties, apart from OBQA, as OLMo-7B is additional educated on extra tokens. A pointy upward tick in accuracy of many duties between the final and second to final step exhibits us the good thing about linearly decreasing the LR to 0 over the ultimate 1000 coaching steps. As an example, within the case of intrinsic evaluations, Paloma argues by a sequence of analyses, from the inspection of efficiency in every area individually as much as extra summarized outcomes over mixtures of domains. We report outcomes at two ranges of granularity: the combination efficiency over 11 of the 18 sources in Paloma, in addition to extra fine-grained outcomes over every of those sources individually.

Last Ideas
On this article, we have now talked about OLMo, a cutting-edge actually open language mannequin provides builders a framework to construct, research, and advance the event of language fashions together with offering researchers entry to its coaching and analysis code, coaching methodology, coaching information, coaching logs, and intermediate mannequin checkpoints. Present cutting-edge fashions have various levels of openness whereas the OLMo mannequin has launched the whole framework from coaching to information to analysis instruments, thus narrowing the hole in efficiency when put next in opposition to cutting-edge fashions like LLaMA2 mannequin.


Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me. https://www.binance.com/join?ref=JW3W4Y3A