
Giant language fashions (LLMs) like GPT-4, Bloom, and LLaMA have achieved exceptional capabilities by scaling as much as billions of parameters. Nonetheless, deploying these large fashions for inference or fine-tuning is difficult as a consequence of their immense reminiscence necessities. On this technical weblog, we’ll discover strategies for estimating and optimizing reminiscence consumption throughout LLM inference and fine-tuning throughout numerous {hardware} setups.
Understanding Reminiscence Necessities
The reminiscence required to load an LLM is primarily decided by the variety of parameters and the numerical precision used to retailer the parameters. A easy rule of thumb is:
- Loading a mannequin with X billion parameters requires roughly 4X GB of VRAM in 32-bit float precision
- Loading a mannequin with X billion parameters requires roughly 2X GB of VRAM in 16-bit bfloat16/float16 precision
For instance, loading the 175B parameter GPT-3 mannequin would require roughly 350GB of VRAM in bfloat16 precision. As of at this time, the most important commercially accessible GPUs just like the NVIDIA A100 and H100 provide solely 80GB of VRAM, necessitating tensor parallelism and mannequin parallelism strategies.
Throughout inference, the reminiscence footprint is dominated by the mannequin parameters and the short-term activation tensors produced. A high-level estimate for the height reminiscence utilization throughout inference is the sum of the reminiscence required to load the mannequin parameters and the reminiscence for activations.
Quantifying Inference Reminiscence
Let’s quantify the reminiscence necessities for inference utilizing the OctoCode mannequin, which has round 15 billion parameters in bfloat16 format (~ 31GB). We’ll use the Transformers library to load the mannequin and generate textual content:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
mannequin = AutoModelForCausalLM.from_pretrained("bigcode/octocoder",
torch_dtype=torch.bfloat16,
device_map="auto",
pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", mannequin=mannequin, tokenizer=tokenizer)
immediate = "Query: Please write a Python operate to transform bytes to gigabytes.nnAnswer:"
consequence = pipe(immediate, max_new_tokens=60)[0]["generated_text"][len(prompt):]
def bytes_to_gigabytes(bytes):
return bytes / 1024 / 1024 / 1024
bytes_to_gigabytes(torch.cuda.max_memory_allocated())
Output:
The height GPU reminiscence utilization is round 29GB, which aligns with our estimate of 31GB for loading the mannequin parameters in bfloat16 format.
Optimizing Inference Reminiscence with Quantization
Whereas bfloat16 is the widespread precision used for coaching LLMs, researchers have discovered that quantizing the mannequin weights to decrease precision information varieties like 8-bit integers (int8) or 4-bit integers can considerably cut back reminiscence utilization with minimal accuracy loss for inference duties like textual content technology.
Let’s examine the reminiscence financial savings from 8-bit and 4-bit quantization of the OctoCode mannequin:
</div>
# 8-bit quantization
mannequin = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True,
pad_token_id=0)
pipe = pipeline("text-generation", mannequin=mannequin, tokenizer=tokenizer)
consequence = pipe(immediate, max_new_tokens=60)[0]["generated_text"][len(prompt):]
bytes_to_gigabytes(torch.cuda.max_memory_allocated())</pre>
Output:
# 4-bit quantization
mannequin = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True,
low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", mannequin=mannequin, tokenizer=tokenizer)
consequence = pipe(immediate, max_new_tokens=60)[0]["generated_text"][len(prompt):]
bytes_to_gigabytes(torch.cuda.max_memory_allocated())
Output:
With 8-bit quantization, the reminiscence requirement drops from 31GB to 15GB, whereas 4-bit quantization additional reduces it to simply 9.5GB! This permits operating the 15B parameter OctoCode mannequin on client GPUs just like the RTX 3090 (24GB VRAM).
Nonetheless, observe that extra aggressive quantization like 4-bit can generally result in accuracy degradation in comparison with 8-bit or bfloat16 precision. There is a trade-off between reminiscence financial savings and accuracy that customers ought to consider for his or her use case.
Quantization is a robust method that may allow LLM deployment on resource-constrained environments like cloud cases, edge units, and even cell phones by drastically decreasing the reminiscence footprint.
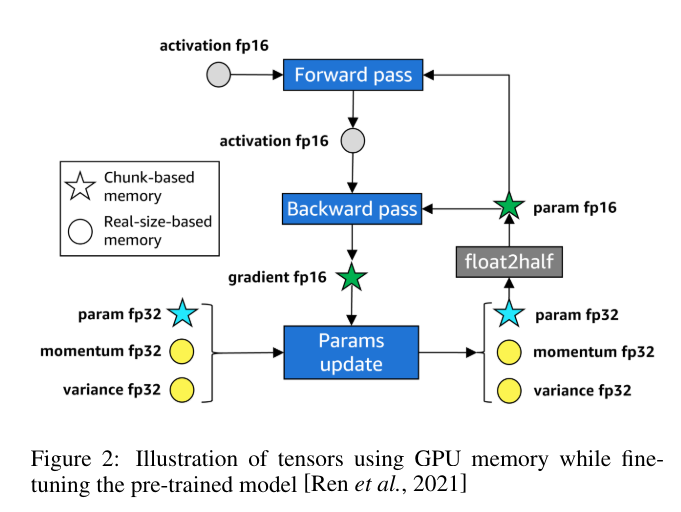
Estimating Reminiscence for Advantageous-Tuning
Whereas quantization is primarily used for environment friendly inference, strategies like tensor parallelism and mannequin parallelism are essential for managing reminiscence necessities in the course of the coaching or fine-tuning of enormous language fashions.
The height reminiscence consumption throughout fine-tuning is often 3-4 instances increased than inference as a consequence of further reminiscence necessities for:
- Gradients
- Optimizer states
- Activations from the ahead go saved for backpropagation
A conservative estimate is that fine-tuning an LLM with X billion parameters requires round 4 * (2X) = 8X GB of VRAM in bfloat16 precision.
For instance, fine-tuning the 7B parameter LLaMA mannequin would require roughly 7 * 8 = 56GB of VRAM per GPU in bfloat16 precision. This exceeds the reminiscence capability of present GPUs, necessitating distributed fine-tuning strategies.
Distributed Advantageous-Tuning Strategies
A number of distributed fine-tuning strategies have been proposed to beat GPU reminiscence constraints for big fashions:
- Information Parallelism: The traditional information parallelism strategy replicates the complete mannequin throughout a number of GPUs whereas splitting and distributing the coaching information batches. This reduces coaching time linearly with the variety of GPUs however doesn’t cut back the height reminiscence requirement on every GPU.
- ZeRO Stage 3: A complicated type of information parallelism that partitions the mannequin parameters, gradients, and optimizer states throughout GPUs. It reduces reminiscence in comparison with traditional information parallelism by protecting solely the required partitioned information on every GPU throughout completely different phases of coaching.
- Tensor Parallelism: As an alternative of replicating the mannequin, tensor parallelism divides the mannequin parameters into rows or columns and distributes them throughout GPUs. Every GPU operates on a partitioned set of parameters, gradients, and optimizer states, resulting in substantial reminiscence financial savings.
- Pipeline Parallelism: This method partitions the mannequin layers throughout completely different GPUs/employees, with every gadget executing a subset of the layers. Activations are handed between employees, decreasing peak reminiscence however rising communication overhead.
Estimating reminiscence utilization for these distributed strategies is non-trivial because the distribution of parameters, gradients, activations, and optimizer states varies throughout strategies. Furthermore, completely different elements just like the transformer physique and language modeling head might exhibit completely different reminiscence allocation behaviors.
The LLMem Resolution
Researchers not too long ago proposed LLMem, an answer that precisely estimates GPU reminiscence consumption when making use of distributed fine-tuning strategies to LLMs throughout a number of GPUs.

Estimating GPU Reminiscence Utilization for Advantageous-Tuning Pre-Educated LLM
LLMem considers elements like recombining parameters earlier than computation (ZeRO Stage 3), output gathering within the backward go (tensor parallelism), and the completely different reminiscence allocation methods for the transformer physique and language modeling head.
Experimental outcomes present that LLMem can estimate peak GPU reminiscence utilization for fine-tuning LLMs on a single GPU with error charges of as much as 1.6%, outperforming the state-of-the-art DNNMem’s common error price of 42.6%. When making use of distributed fine-tuning strategies to LLMs with over a billion parameters on a number of GPUs, LLMem achieves a powerful common error price of 3.0%.

