
Massive Language Fashions and Generative AI have demonstrated unprecedented success on a big selection of Pure Language Processing duties. After conquering the NLP subject, the subsequent problem for GenAI and LLM researchers is to discover how massive language fashions can act autonomously in the actual world with an prolonged era hole from textual content to motion, thus representing a major paradigm within the pursuit of Synthetic Normal Intelligence. On-line video games are thought of to be an acceptable check basis to develop massive language mannequin embodied brokers that work together with the visible atmosphere in a approach {that a} human would do.
For instance, in a preferred on-line simulation recreation Minecraft, determination making brokers could be employed to help the gamers in exploring the world together with creating expertise for making instruments and fixing duties. One other instance of LLM brokers interacting with the visible atmosphere could be skilled in one other on-line recreation, The Sims the place brokers have demonstrated outstanding success in social interactions and exhibit habits that resembles people. Nevertheless, in comparison with current video games, tactical battle video games may show to be a more sensible choice to benchmark the power of huge language fashions to play digital video games. The first motive why tactical video games make a greater benchmark is as a result of the win charge could be measured instantly, and constant opponents together with human gamers and AI are all the time out there.
Constructing on the identical, POKELLMON, goals to be the world’s first embodied agent that achieves human-level efficiency on tactical video games, much like the one witnessed in Pokemon battles. At its core, the POKELLMON framework incorporates three primary methods.
- In-context reinforcement studying that consumes text-based suggestions derived from battles instantaneously to refine the coverage iteratively.
- Data-augmented era that retrieves exterior information to counter hallucinations, enabling the agent to behave correctly and when it is wanted.
- Constant motion era to reduce the panic switching state of affairs when the agent comes throughout a robust participant, and needs to keep away from dealing with them.
This text goals to cowl the POKELLMON framework in depth, and we discover the mechanism, the methodology, the structure of the framework together with its comparability with state-of-the-art frameworks. We can even speak about how the POKELLMON framework demonstrates outstanding human-like battle methods, and in-time determination making talents, attaining a decent win charge of just about 50%. So let’s get began.
The expansion within the capabilities, and effectivity of Massive Language Fashions, and Generative AI frameworks up to now few years has been nothing however marvelous, particularly on NLP duties. Lately, builders and AI researchers have been engaged on methods to make Generative AI and LLMs extra distinguished in real-world situations with the power to behave autonomously within the bodily world. To attain this autonomous efficiency in bodily and actual world conditions, researchers and builders think about video games to be an acceptable check mattress to develop LLM-embodied brokers with the power to work together with the digital atmosphere in a fashion that resembles human habits.
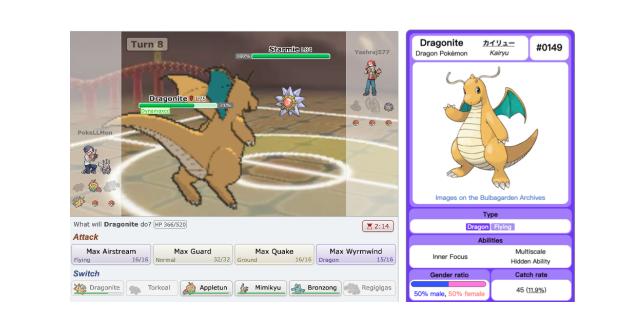
Beforehand, builders have tried to develop LLM-embodied brokers on digital simulation video games like Minecraft and Sims, though it’s believed that tactical video games like Pokemon may be a more sensible choice to develop these brokers. Pokemon battles permits the builders to judge a coach’s skill to battle in well-known Pokemon video games, and provides a number of benefits over different tactical video games. Because the motion and state areas are discrete, it may be translated into textual content with none loss. The next determine illustrates a typical Pokemon battle the place the participant is requested to generate an motion to carry out at every flip given the present state of the Pokemon from both sides. The customers have the choice to select from 5 completely different Pokemons and there are a complete of 4 strikes within the motion house. Moreover, the sport helps in assuaging the stress on the inference time and inference prices for LLMs because the turn-based format eliminates the requirement for an intensive gameplay. Consequently, the efficiency relies totally on the reasoning skill of the big language mannequin. Lastly, though the Pokemon battle video games look like easy, issues are a bit extra advanced in actuality and extremely strategic. An skilled participant doesn’t randomly choose a Pokemon for the battle, however takes varied elements into consideration together with kind, stats, talents, species, gadgets, strikes of the Pokemons, each on and off the battlefield. Moreover, in a random battle, the Pokemons are chosen randomly from a pool of over a thousand characters, every with their very own set of distinct characters with reasoning skill and Pokemon information.

POKELLMON : Methodology and Structure
The general framework and structure of the POKELLMON framework is illustrated within the following picture.

Throughout every flip, the POKELLMON framework makes use of earlier actions, and its corresponding text-based suggestions to refine the coverage iteratively together with augmenting the present state info with exterior information like skill/transfer results or benefit/weak point relationship. For info given as enter, the POKELLMON framework generates a number of actions independently, after which selects essentially the most constant ones as the ultimate output.
In-Context Reinforcement Studying
Human gamers and athletes typically make selections not solely on the idea of the present state, however additionally they mirror on the suggestions from earlier actions as nicely the experiences of different gamers. It will be protected to say that optimistic suggestions is what helps a participant study from their errors, and refrains them from making the identical mistake over and over. With out correct suggestions, the POKELLMON brokers may persist with the identical error motion, as demonstrated within the following determine.

As it may be noticed, the in-game agent makes use of a water-based transfer towards a Pokemon character that has the “Dry Pores and skin” skill, permitting it to nullify the injury towards water-based assaults. The sport tries to alert the person by flashing the message “Immune” on the display which may immediate a human participant to rethink their actions, and alter them, even with out figuring out about “Dry Pores and skin”. Nevertheless, it isn’t included within the state description for the agent, ensuing within the agent making the identical mistake once more.
To make sure that the POKELLMON agent learns from its prior errors, the framework implements the In-Context Reinforcement Studying method. Reinforcement studying is a well-liked method in machine studying, and it helps builders with the refining coverage because it requires numeric rewards to judge actions. Since massive language fashions have the power to interpret and perceive language, text-based descriptions have emerged as a brand new type of reward for the LLMs. By together with text-based suggestions from the earlier actions, the POKELLMON agent is ready to iteratively and immediately refine its coverage, particularly the In-Context Reinforcement Studying. The POKELLMON framework develops 4 sorts of suggestions,
- The precise injury attributable to an assault transfer on the idea of the distinction in HP over two consecutive turns.
- The effectiveness of assault strikes. The suggestions signifies the effectiveness of the assault by way of having no impact or immune, ineffective, or super-effective because of skill/transfer results, or kind benefit.
- The precedence order for executing a transfer. Because the exact stats for the opposing Pokemon character shouldn’t be out there, the precedence order suggestions offers a tough estimate of pace.
- The precise impact of the strikes executed on the opponent. Each assault strikes, and standing may lead to outcomes like recuperate HP, stat enhance or debuffs, inflict situations like freezing, burns or poison.

Moreover, the usage of the In-Context Reinforcement Studying method leads to vital enhance in efficiency as demonstrated within the following determine.

When put towards the unique efficiency on GPT-4, the win charge shoots up by almost 10% together with almost 13% enhance within the battle rating. Moreover, as demonstrated within the following determine, the agent begins to investigate and alter its motion if the strikes executed within the earlier strikes weren’t capable of match the expectations.

Data-Augmented Technology or KAG
Though implementing In-Context Reinforcement Studying does assist with hallucinations to an extent, it might nonetheless lead to deadly penalties earlier than the agent receives the suggestions. For instance, if the agent decides to battle towards a fire-type Pokemon with a grass-type Pokemon, the previous is prone to win in in all probability a single flip. To cut back hallucinations additional, and enhance the choice making skill of the agent, the POKELLMON framework implements the Data-Augmented Technology or the KAG method, a way that employs exterior information to enhance era.
Now, when the mannequin generates the 4 sorts of suggestions mentioned above, it annotates the Pokemon strikes and data permitting the agent to deduce the sort benefit relationship by itself. In an try to cut back the hallucination contained in reasoning additional, the POKELLMON framework explicitly annotates the sort benefit, and weak point of the opposing Pokemon, and the agent’s Pokemon with enough descriptions. Moreover, it’s difficult to memorize the strikes and talents with distinct results of Pokemons particularly since there are quite a lot of them. The next desk demonstrates the outcomes of data augmented era. It’s price noting that by implementing the Data Augmented Technology method, the POKELLMON framework is ready to improve the win charge by about 20% from current 36% to 55%.

Moreover, builders noticed that when the agent was supplied with exterior information of Pokemons, it began to make use of particular strikes on the proper time, as demonstrated within the following picture.

Constant Motion Technology
Present fashions exhibit that implementing prompting and reasoning approaches can improve the LLMs skill on fixing advanced duties. As a substitute of producing a one-shot motion, the POKELLMON framework evaluates current prompting methods together with CoT or Chain of Thought, ToT or Tree of Thought, and Self Consistency. For Chain of Thought, the agent initially generates a thought that analyzes the present battle state of affairs, and outputs an motion conditioned on the thought. For Self Consistency, the agent generates thrice the actions, and selects the output that has acquired the utmost variety of votes. Lastly, for the Tree of Thought method, the framework generates three actions identical to within the self consistency method, however picks the one it considers one of the best after evaluating all of them by itself. The next desk summarizes the efficiency of the prompting approaches.

There’s solely a single motion for every flip, which means that even when the agent decides to change, and the opponent decides to assault, the switch-in Pokémon would take the injury. Usually the agent decides to change as a result of it needs to type-advantage swap an off-the-battle Pokémon, and thus the switching-in Pokémon can maintain the injury, because it was type-resistant to the opposing Pokémon’s strikes . Nevertheless, as above, for the agent with CoT reasoning, even when the highly effective opposing Pokémon forces varied rotates, it acts inconsistently with the mission, as a result of it may not wish to switch-in to the Pokemon however a number of Pokémon and again, which we time period panic switching. Panic switching eliminates the possibilities to take strikes, and thus defeats.
POKELLMON : Outcomes and Experiments
Earlier than we talk about the outcomes, it’s important for us to grasp the battle atmosphere. Originally of a flip, the atmosphere receives an action-request message from the server and can reply to this message on the finish, which additionally comprises the execution outcome from the final flip.
- First parses the message and updates native state variables, 2. then interprets the state variables into textual content. The textual content description has primarily 4 components: 1. Personal staff info, which comprises the attributes of Pokémon in-the-field and off-the-field (unused).
- Opponent staff info, which comprises the attributes of opponent Pokémon in-the-field and off-the-field (some info is unknown).
- Battlefield info, which incorporates the climate, entry hazards, and terrain.
- Historic flip log info, which comprises earlier actions of each Pokémon and is saved in a log queue. LLMs take the translated state as enter and output actions for the subsequent step. The motion is then despatched to the server and executed similtaneously the motion performed by the human.
Battle Towards Human Gamers
The next desk illustrates the efficiency of the POKELLMON agent towards human gamers.

As it may be noticed, the POKELLMON agent delivers efficiency akin to ladder gamers who’ve a better win charge when in comparison with an invited participant together with having in depth battle expertise.
Battle Talent Evaluation
The POKELLMON framework hardly ever makes a mistake at selecting the efficient transfer, and switches to a different appropriate Pokemon owing to the Data Augmented Technology technique.

As proven within the above instance, the agent makes use of just one Pokemon to defeat your entire opponent staff since it’s ready to decide on completely different assault strikes, those which can be simplest for the opponent in that state of affairs. Moreover, the POKELLMON framework additionally displays human-like attrition technique. Some Pokemons have a “Poisonous” transfer that may inflict extra injury at every flip, whereas the “Get well” transfer permits it to recuperate its HP. Profiting from the identical, the agent first poisons the opposing Pokemon, and makes use of the Get well transfer to forestall itself from fainting.

Remaining Ideas
On this article, we’ve talked about POKELLMON, an method that allows massive language fashions to play Pokemon battles towards people autonomously. POKELLMON, goals to be the world’s first embodied agent that achieves human-level efficiency on tactical video games, much like the one witnessed in Pokemon battles. The POKELLMON framework introduces three key methods: In-Context Reinforcement Studying which consumes the text-based suggestions as “reward” to iteratively refine the motion era coverage with out coaching, Data-Augmented Technology that retrieves exterior information to fight hallucination and ensures the agent act well timed and correctly, and Constant Motion Technology that forestalls the panic switching difficulty when encountering highly effective opponents.

