
In comparison with robotic programs, people are glorious navigators of the bodily world. Bodily processes apart, this largely comes right down to innate cognitive skills nonetheless missing in most robotics:
- The power to localize landmarks at various ontological ranges, akin to a “e-book” being “on a shelf” or “in the lounge”
- Having the ability to rapidly decide whether or not there’s a navigable path between two factors based mostly on the setting format
Early robotic navigation programs relied on primary line-following programs. These ultimately developed into navigation based mostly on visible notion, supplied by cameras or LiDAR, to assemble geometric maps. In a while, Simultaneous Localization and Mapping (SLAM) programs have been built-in to offer the flexibility to plan routes by environments.
About us: Viso Suite is our end-to-end laptop imaginative and prescient infrastructure for enterprises. By offering a single location to develop, deploy, handle, and safe the appliance improvement course of, Viso Suite omits the necessity for level options. Enterprise groups can increase productiveness and decrease operation prices with full-scale options to speed up the ML pipeline. Ebook a demo with our group of specialists to be taught extra.
Multimodal Robotic Navigation – The place Are We Now?
More moderen makes an attempt to endow robotics with the identical capabilities have centered round constructing geometric maps for path planning and parsing targets from pure language instructions. Nonetheless, this method struggles in terms of generalizing for brand spanking new or beforehand unseen directions. To not point out environments that change dynamically or are ambiguous in a roundabout way.
Moreover, studying strategies instantly optimize navigation insurance policies based mostly on end-to-end language instructions. Whereas this technique will not be inherently dangerous, it does require huge quantities of knowledge to coach fashions.
Present Synthetic Intelligence (AI) and deep studying fashions are adept at matching object pictures to pure language descriptions by leveraging coaching on internet-scale information. Nonetheless, this functionality doesn’t translate nicely to mapping the environments containing the mentioned objects.
New analysis goals to combine multimodal inputs to reinforce robotic navigation in advanced environments. As a substitute of basing route planning on one-dimensional visible enter, these programs mix visible, audio, and language cues. This enables for making a richer context and bettering situational consciousness.
Introducing AVLMaps and VLMaps – A New Paradigm for Robotic Navigation?
One probably groundbreaking space of research on this subject pertains to so-called VLMaps (Visible Language Maps) and AVLMaps (Audio Visible Language Maps). The current papers “Visible Language Maps for Robotic Navigation” and “Audio Visible Language Maps for Robotic Navigation” by Chenguang Huang and co. discover the prospect of utilizing these fashions for robotic navigation in nice element.
VLMaps instantly fuses visual-language options from pre-trained fashions with 3D reconstructions of the bodily setting. This permits exact spatial localization of navigation targets anchored in pure language instructions. It could additionally localize landmarks and spatial references for landmarks.
The principle benefit is that this enables for zero-shot spatial aim navigation with out further information assortment or finetuning.
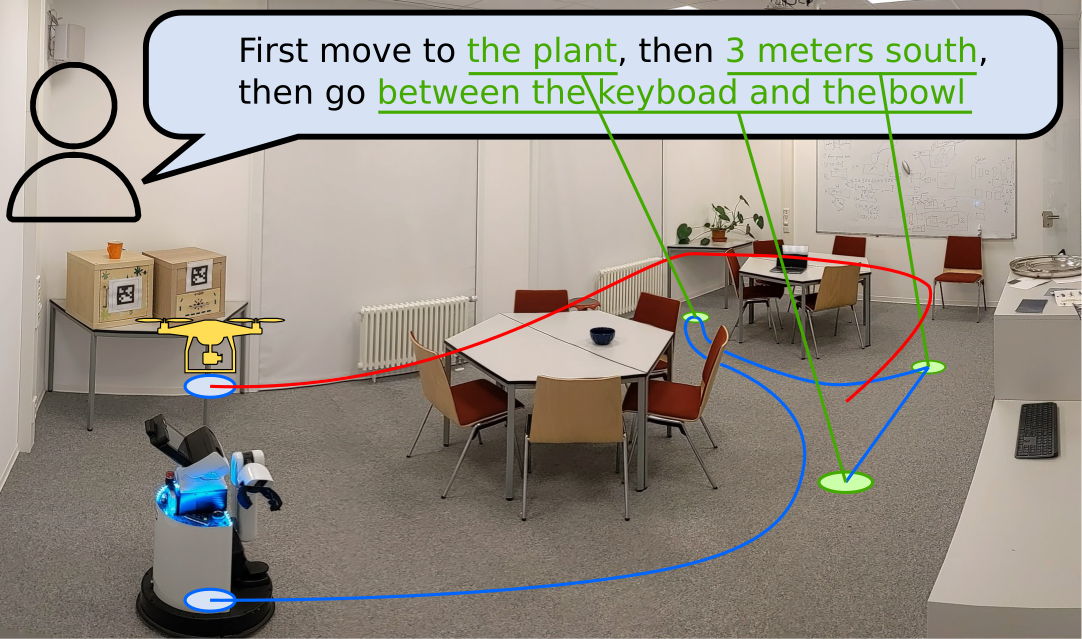
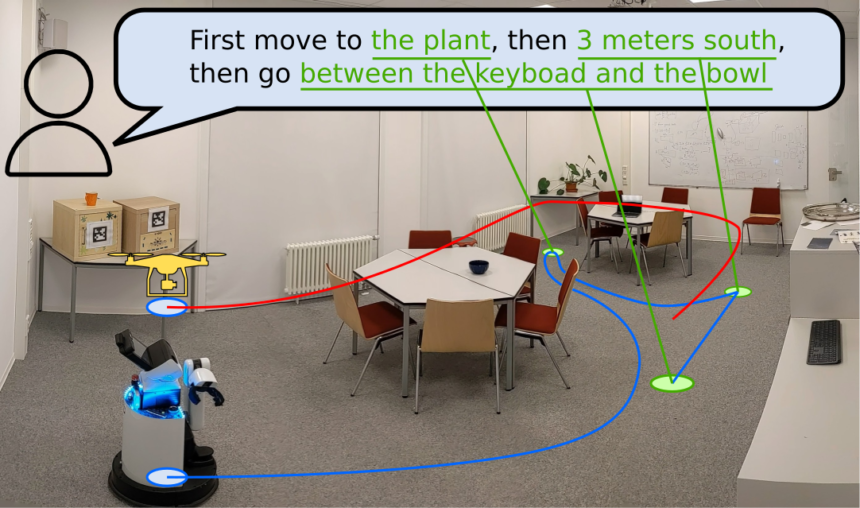
This method permits for extra correct execution of advanced navigational duties and the sharing of those maps with totally different robotic programs.
AVLMaps are based mostly on the identical method but additionally incorporate audio cues to assemble a 3D voxel grid utilizing pre-trained multimodal fashions. This makes zero-shot multimodal aim navigation attainable by indexing landmarks utilizing textual, picture, and audio inputs. For instance, this is able to permit a robotic to hold out a navigation aim akin to “go to the desk the place the beeping sound is coming from.”
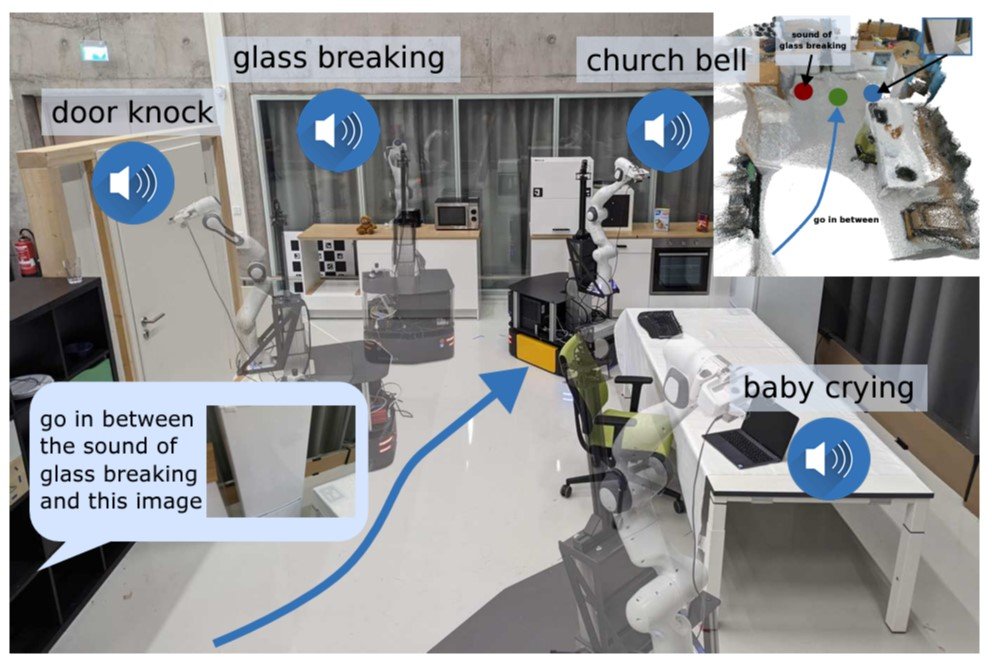
Audio enter can enrich the system’s world notion and assist disambiguate targets in environments with a number of potential targets.
VLMaps: Integrating Visible-Language Options with Spatial Mapping
Associated work in AI and laptop imaginative and prescient has performed a pivotal position in creating VLMaps. As an example, the maturation of SLAM strategies has enormously superior the flexibility to translate semantic data into 3D maps. Conventional approaches both relied on densely annotated 3D volumetric maps with 2D semantic segmentation Convolutional Neural Networks (CNNs) or object-oriented strategies to construct 3D Maps.
Whereas progress has been made in generalizing these fashions, it’s closely constrained by working on a predefined set of semantic courses. VLMaps overcomes this limitation by creating open-vocabulary semantic maps that permit pure language indexing.
Enhancements in Imaginative and prescient and Language Navigation (VLN) have additionally led to the flexibility to be taught end-to-end insurance policies that observe route-based directions on topological graphs of simulated environments. Nonetheless, till now, their real-world applicability has been restricted by a reliance on topological graphs and a scarcity of low-level planning capabilities. One other draw back is the necessity for enormous information units for coaching.
For VLMaps, the researchers have been influenced by pre-trained language and imaginative and prescient fashions, akin to LM-Nav and CoW (CLIP on Wheels). The latter performs zero-shot language-based object navigation by leveraging CLIP-based saliency maps. Whereas these fashions can navigate to things, they battle with spatial queries, akin to “to the left of the chair” and “in between the TV and the couch.”
VLMaps prolong these capabilities by supporting open-vocabulary impediment maps and sophisticated spatial language indexing. This enables navigation programs to construct queryable scene representations for LLM-based robotic planning.

Key Parts of VLMaps
A number of key elements within the improvement of VLMaps permit for constructing a spatial map illustration that localizes landmarks and spatial references based mostly on pure language.
Constructing a Visible-Language Map
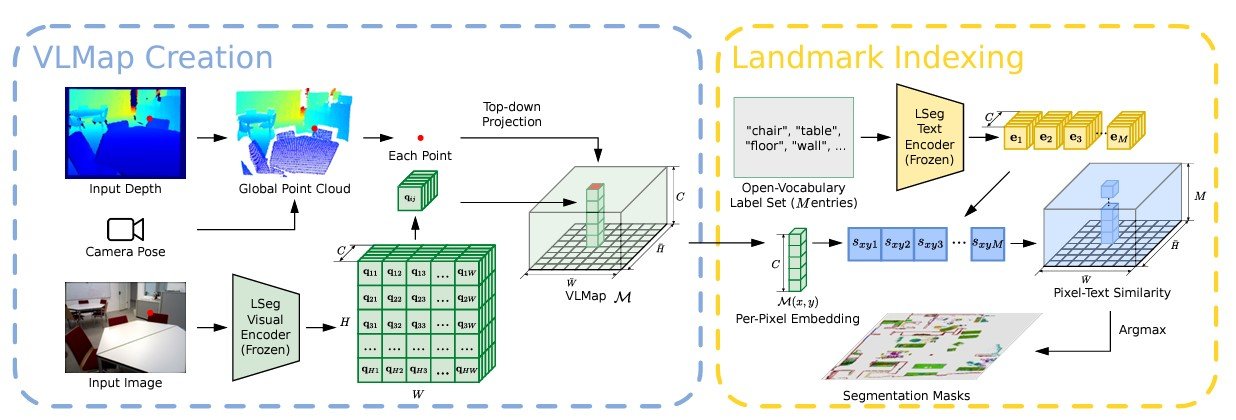
VLMaps makes use of a video feed from robots mixed with normal exploration algorithms to construct a visual-language map. The method includes:
- Visible Function Extraction: Utilizing fashions like CLIP to extract visual-language options from picture observations.
- 3D Reconstruction: Combining these options with 3D spatial information to create a complete map.
- Indexing: Enabling the map to assist pure language queries, permitting for indexing and localization of landmarks.
Mathematically, suppose VV represents the visible options and LL represents the language options. In that case, their fusion might be represented as M=f(V, L)M = f(V, L), the place MM is the ensuing visual-language map.
Localizing Open-Vocabulary Landmarks
To localize landmarks in VLMaps utilizing pure language, an enter language listing is outlined with representations for every class in textual content type. Examples embrace [“chair”, “sofa”, “table”] or [“furniture”, “floor”]. This listing is transformed into vector embeddings utilizing the pre-trained CLIP textual content encoder.
The map embeddings are then flattened into matrix type. The pixel-to-category similarity matrix is computed, with every component indicating the similarity worth. Making use of the argmax operator and reshaping the consequence provides the ultimate segmentation map, which identifies probably the most associated language-based class for every pixel.
Producing Open-Vocabulary Impediment Maps
Utilizing a Giant Language Mannequin (LLM), VLMap interprets instructions and breaks them into subgoals, permitting for particular directives like “in between the couch and the TV” or “three meters east of the chair.”
The LLM generates executable Python code for robots, translating high-level directions into parameterized navigation duties. For instance, instructions akin to “transfer to the left aspect of the counter” or “transfer between the sink and the oven” are transformed into exact navigation actions utilizing predefined features.

AVLMaps: Enhancing Navigation with Audio, Visible, and Language Cues
AVLMaps largely builds on the identical method utilized in creating VLMaps, however prolonged with multimodal capabilities to course of auditory enter as nicely. In AVLMaps, objects might be instantly localized from pure language directions utilizing each visible and audio cues.
For testing, the robotic was additionally supplied with an RGB-D video stream and odometry data, however this time with an audio observe included.
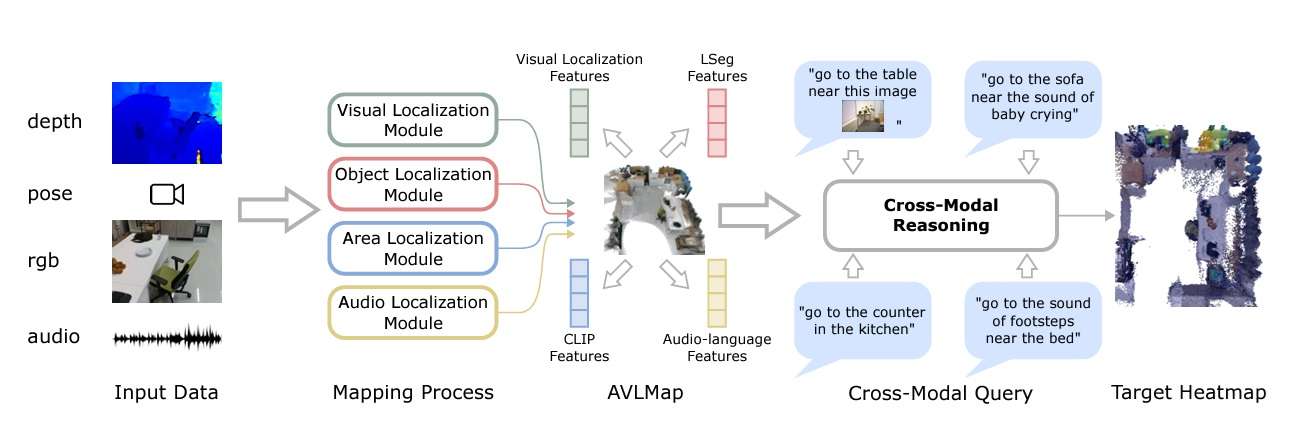
Module Varieties
In AVLMaps, the system makes use of 4 modules to construct a multimodal options database. They’re:
- Visible Localization Module: Localizes a question picture within the map utilizing a hierarchical scheme, computing each native and world descriptors within the RGB stream.
- Object Localization Module: Makes use of open-vocabulary segmentation (OpenSeg) to generate pixel-level options from the RGB picture, associating them with back-projected depth pixels in 3D reconstruction. It computes cosine similarity scores for all level and language options, choosing top-scoring factors within the map for indexing.
- Space Localization Module: The paper proposes a sparse topological CLIP options map to establish coarse visible ideas, like “kitchen space.” Additionally, utilizing cosine similarity scores, the mannequin calculates confidence scores for predicting areas.
- Audio Localization Module: Partitions an audio clip from the stream into segments utilizing silence detection. Then, it computes audio-lingual options for every utilizing AudioCLIP to provide you with matching scores for predicting areas based mostly on odometry data.
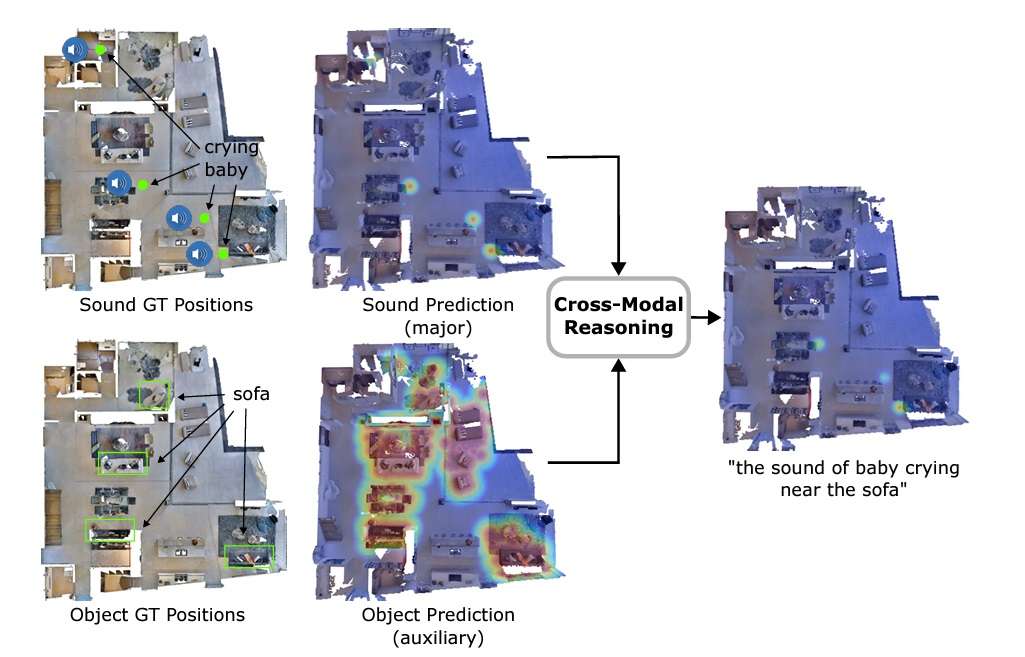
The important thing differentiator of AVLMaps is its capacity to disambiguate targets by cross-referencing visible and audio options. Within the paper, that is achieved by creating heatmaps with possibilities for every voxel place based mostly on the gap to the goal. The mannequin multiplies the outcomes from heatmaps for various modalities to foretell the goal with the very best possibilities.
VLMaps and AVLMaps vs. Different Strategies for Robotic Navigation
Experimental outcomes present the promise of using strategies like VLMaps for robotic navigation. Wanting on the object, varied fashions have been generated for the thing sort “chair,” for instance, it’s clear that VLMaps is extra discerning in its predictions.

In multi-object navigation, VLMaps considerably outperformed typical fashions. That is largely as a result of VLMaps don’t undergo from producing as many false positives as the opposite strategies.
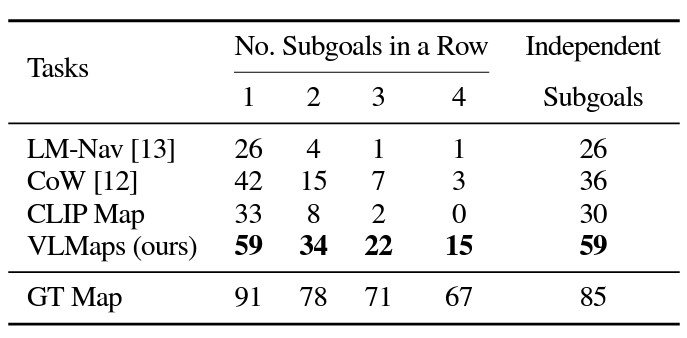
VLMaps additionally achieves a lot increased zero-shot spatial aim navigation success charges than the opposite open-vocabulary zero-shot navigation baseline options.
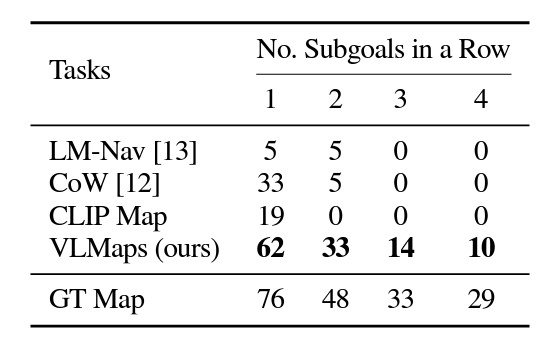
One other space the place VLMaps reveals promising outcomes is in cross-embodiment navigation to optimize route planning. On this case, VLMaps generated totally different impediment maps for robotic embodiments, a ground-based LoCoBot, and a flying drone. When supplied with a drone map, the drone considerably improved its efficiency by creating navigation maps to fly over obstacles. This reveals VLMap’s effectivity at each 2D and 3D spatial navigation.

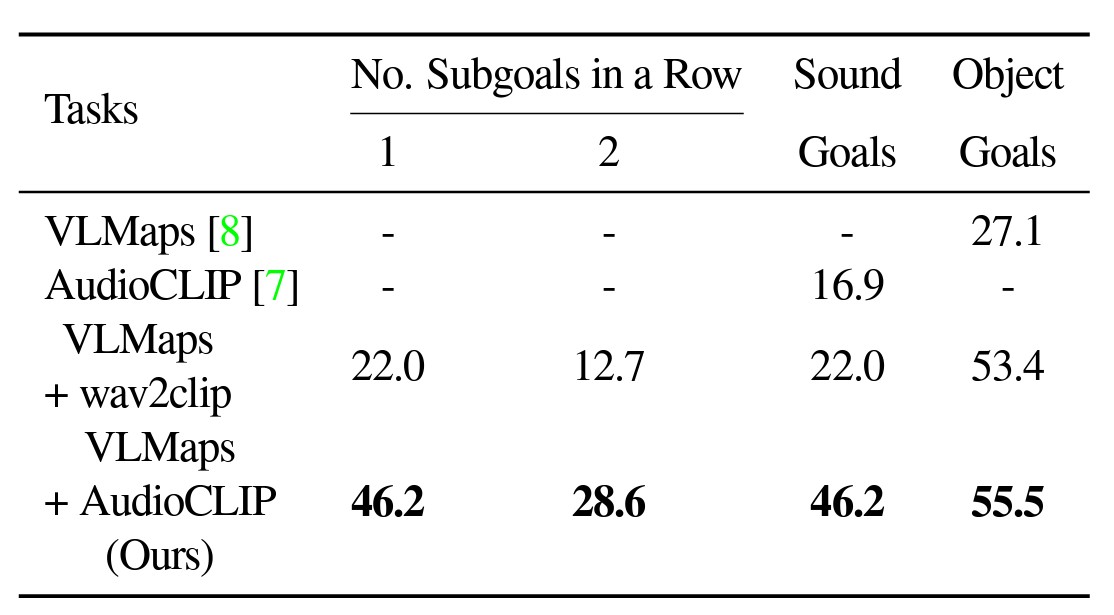
Equally, throughout testing, AVLMaps outperformed VLMaps with each normal AudioCLIP and wav2clip in fixing ambiguous aim navigation duties. For the experiment, robots have been made to navigate to at least one sound aim and one object aim in a sequence.
What’s Subsequent for Robotic Navigation?
Whereas fashions like VLMaps and AVLMaps present potential, there’s nonetheless a protracted technique to go. To imitate the navigational capabilities of people and be helpful in additional real-life conditions, we want programs with even increased success charges in finishing up advanced, multi-goal navigational duties.
Moreover, these experiments used primary, drone-like robotics. We have now but to see how these superior navigational fashions might be mixed with extra human-like programs.
One other energetic space of analysis is Event-based SLAM. As a substitute of relying purely on sensory data, these programs can use occasions to disambiguate targets or open up new navigational alternatives. As a substitute of utilizing single frames, these programs seize adjustments in lighting and different traits to establish environmental occasions.
As these strategies evolve, we will count on elevated adoption in fields like autonomous automobiles, nanorobotics, agriculture, and even robotic surgical procedure.
To be taught extra concerning the world of AI and laptop imaginative and prescient, take a look at the viso.ai weblog: