
VentureBeat presents: AI Unleashed – An unique govt occasion for enterprise knowledge leaders. Hear from prime trade leaders on Nov 15. Reserve your free pass
Nice-tuning massive language fashions (LLM) has develop into an vital software for companies in search of to tailor AI capabilities to area of interest duties and personalised consumer experiences. However fine-tuning often comes with steep computational and monetary overhead, protecting its use restricted for enterprises with restricted assets.
To resolve these challenges, researchers have created algorithms and strategies that minimize the price of fine-tuning LLMs and operating fine-tuned fashions. The most recent of those strategies is S-LoRA, a collaborative effort between researchers at Stanford College and College of California-Berkeley (UC Berkeley).
S-LoRA dramatically reduces the prices related to deploying fine-tuned LLMs, which permits firms to run tons of and even hundreds of fashions on a single graphics processing unit (GPU). This might help unlock many new LLM purposes that will beforehand be too expensive or require large investments in compute assets.
Low-rank adaptation
The traditional strategy to fine-tuning LLMs includes retraining a pre-trained mannequin with new examples tailor-made to a particular downstream activity and adjusting all the mannequin’s parameters. On condition that LLMs sometimes have billions of parameters, this technique calls for substantial computational assets.
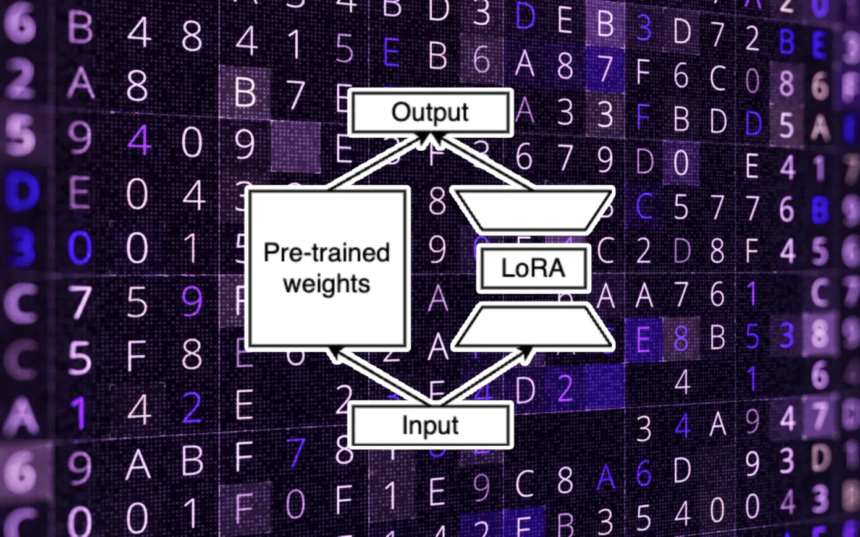
Parameter-efficient fine-tuning (PEFT) strategies circumvent these prices by avoiding adjusting all the weights throughout fine-tuning. A notable PEFT technique is low-rank adaptation (LoRA), a method developed by Microsoft, which identifies a minimal subset of parameters inside the foundational LLM which might be satisfactory for fine-tuning to the brand new activity.
Remarkably, LoRA can cut back the variety of trainable parameters by a number of orders of magnitude whereas sustaining accuracy ranges on par with these achieved via full-parameter fine-tuning. This significantly diminishes the reminiscence and computation required to customise the mannequin.

The effectivity and effectiveness of LoRA have led to its widespread adoption inside the AI neighborhood. Quite a few LoRA adapters have been crafted for pre-trained LLMs and diffusion fashions.
You possibly can merge the LoRA weights with the bottom LLM after fine-tuning. Nevertheless, another apply includes sustaining the LoRA weights as separate parts which might be plugged into the principle mannequin throughout inference. This modular strategy permits for firms to keep up a number of LoRA adapters, every representing a fine-tuned mannequin variant, whereas collectively occupying solely a fraction of the principle mannequin’s reminiscence footprint.
The potential purposes of this technique are huge, starting from content material creation to customer support, making it attainable for companies to supply bespoke LLM-driven providers with out incurring prohibitive prices. As an example, a running a blog platform might leverage this system to supply fine-tuned LLMs that may create content material with every creator’s writing model at minimal expense.
What S-LoRA presents
Whereas deploying a number of LoRA fashions atop a single full-parameter LLM is an attractive idea, it introduces a number of technical challenges in apply. A major concern is reminiscence administration; GPUs have finite reminiscence, and solely a choose variety of adapters may be loaded alongside the bottom mannequin at any given time. This necessitates a extremely environment friendly reminiscence administration system to make sure easy operation.
One other hurdle is the batching course of utilized by LLM servers to boost throughput by dealing with a number of requests concurrently. The various sizes of LoRA adapters and their separate computation from the bottom mannequin introduce complexity, doubtlessly resulting in reminiscence and computational bottlenecks that impede the inference pace.
Furthermore, the intricacies multiply with bigger LLMs that require multi-GPU parallel processing. The mixing of extra weights and computations from LoRA adapters complicates the parallel processing framework, demanding progressive options to keep up effectivity.
S-LoRA makes use of dynamic reminiscence administration to swap LoRA adapters between predominant reminiscence and GPU
The brand new S-LoRA method solves these challenges via a framework designed to serve a number of LoRA fashions. S-LoRA has a dynamic reminiscence administration system that hundreds LoRA weights into the principle reminiscence and routinely transfers them between GPU and RAM reminiscence because it receives and batches requests.
The system additionally introduces a “Unified Paging” mechanism that seamlessly handles question mannequin caches and adapter weights. This innovation permits the server to course of tons of and even hundreds of batched queries with out inflicting reminiscence fragmentation points that may improve response instances.
S-LoRA incorporates a cutting-edge “tensor parallelism” system tailor-made to maintain LoRA adapters suitable with massive transformer fashions that run on a number of GPUs.
Collectively, these developments allow S-LoRA to serve many LoRA adapters on a single GPU or throughout a number of GPUs.
Serving hundreds of LLMs
The researchers evaluated S-LoRA by serving a number of variants of the open-source Llama mannequin from Meta throughout totally different GPU setups. The outcomes confirmed that S-LoRA might preserve throughput and reminiscence effectivity at scale.
Benchmarking towards the main parameter-efficient fine-tuning library, Hugging Face PEFT, S-LoRA showcased a outstanding efficiency enhance, enhancing throughput by as much as 30-fold. In comparison with vLLM, a high-throughput serving system with fundamental LoRA assist, S-LoRA not solely quadrupled throughput but in addition expanded the variety of adapters that may very well be served in parallel by a number of orders of magnitude.
Probably the most notable achievements of S-LoRA is its capacity to concurrently serve 2,000 adapters whereas incurring a negligible improve in computational overhead for extra LoRA processing.
“The S-LoRA is usually motivated by personalised LLMs,” Ying Sheng, a PhD scholar at Stanford and co-author of the paper, instructed VentureBeat. “A service supplier might wish to serve customers with the identical base mannequin however totally different adapters for every. The adapters may very well be tuned with the customers’ historical past knowledge for instance.”
S-LoRA’s versatility extends to its compatibility with in-context studying. It permits a consumer to be served with a personalised adapter whereas enhancing the LLM’s response by including latest knowledge as context.
“This may be simpler and extra environment friendly than pure in-context prompting,” Sheng added. “LoRA has rising adaptation in industries as a result of it’s low-cost. And even for one consumer, they will maintain many variants however with the price of similar to holding one mannequin.”
The S-LoRA code is now accessible on GitHub. The researchers plan to combine it into well-liked LLM-serving frameworks to allow firms to readily incorporate S-LoRA into their purposes.