

Patrick Levermore, 1 March 2023
Abstract
This doc seems on the predictions made by AI specialists in The 2016 Professional Survey on Progress in AI, analyses the predictions on ‘Slim duties’, and offers a Brier rating to the median of the specialists’ predictions.
My evaluation means that the specialists did a reasonably good job of forecasting (Brier rating = 0.21), and would have been much less correct if they’d predicted every improvement in AI to typically come, by an element of 1.5, later (Brier rating = 0.26) or sooner (Brier rating = 0.29) than they really predicted.
I choose that the specialists anticipated 9 milestones to have occurred by now – and that 10 milestones have now occurred.
However there are necessary caveats to this, corresponding to:
- I’ve solely analysed whether or not milestones have been publicly met. AI labs might have achieved extra milestones in personal this 12 months with out disclosing them. This implies my evaluation of what number of milestones have been met might be conservative.
- I’ve taken the purpose possibilities given, fairly than estimating likelihood distributions for every milestone, that means I usually spherical down, which skews the knowledgeable forecasts in the direction of being extra conservative and unfairly penalises their forecasts for low precision.
- It’s not obvious that forecasting accuracy on these nearer-term questions may be very predictive of forecasting accuracy on the longer-term questions.
- My judgements concerning which forecasting questions have resolved positively vs negatively had been considerably subjective (justifications for every query within the separate appendix).
Introduction
In 2016, AI Impacts revealed The Professional Survey on Progress in AI: a survey of machine studying researchers, asking for his or her predictions about when varied AI developments will happen. The outcomes have been used to tell normal and knowledgeable opinions on AI timelines.
The survey largely targeted on timelines for normal/human-level synthetic intelligence (median forecast of 2056). Nevertheless, included on this survey had been a set of questions on shorter-term milestones in AI. A few of these forecasts at the moment are resolvable. Measuring how correct these shorter-term forecasts have been might be considerably informative of how correct the longer-term forecasts are. Extra broadly, the accuracy of those shorter-term forecasts appears considerably informative of how correct ML researchers’ views are basically. So, how have the specialists executed to date?
Findings
I analysed the 32 ‘Slim duties’ to which the next query was requested:
What number of years till you suppose the next AI duties might be possible with:
- a small probability (10%)?
- an excellent probability (50%)?
- a excessive probability (90%)?
Let a activity be ‘possible’ if among the finest resourced labs may implement it in lower than a 12 months in the event that they selected to. Ignore the query of whether or not they would select to.1
I interpret ‘possible’ as whether or not, in ‘lower than a 12 months’ prior to now, any AI fashions had handed these milestones, and this was disclosed publicly. Since it’s now (February 2023) 6.5 years since this survey, I’m subsequently taking a look at any forecasts for occasions occurring inside 5.5 years of the survey.
Throughout these milestones, I choose that 10 have now occurred and 22 haven’t occurred. My 90% confidence interval is that 7-15 of them have now occurred. A full description of milestones, and justification of my judgments, are in the appendix (separate doc).
The specialists forecast that:
- 4 milestones had a <10% probability of occurring by now,
- 20 had a 10-49% probability,
- 7 had a 50-89% probability,
- 1 had a >90% probability.
In order that they anticipated 6-17 of those milestones to have occurred by now. By eyeballing the forecasts for every milestone, my estimate is that they anticipated ~9 to have occurred.2 I didn’t estimate the implied likelihood distributions for every milestone, which might make this extra correct.
Utilizing the ten, 50, and 90% level possibilities, we get the next calibration curve:
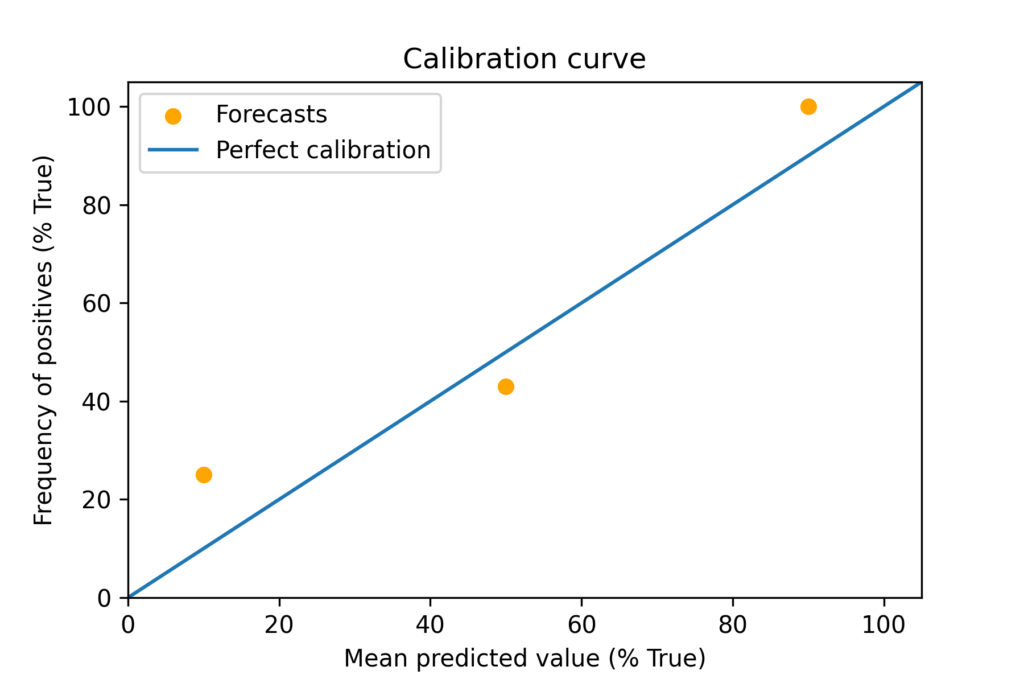
However, firstly, the info right here is small (there are 7 knowledge factors on the 50% mark and 1 on the 90% mark). Secondly, my methodology for this graph, and within the under Brier calculations, relies on rounding all the way down to the closest given forecast. For instance, if a ten% probability was given at 3 years, and a 50% probability at 10 years, the forecast was taken to be 10%, fairly than estimating a full likelihood distribution and discovering the 5.5 years level. This skews the knowledgeable forecasts in the direction of being extra conservative and unfairly penalises an absence of precision.
Brier scores
General, throughout each forecast made, the specialists come out with a Brier rating of 0.21.3 The rating breakdown and clarification of the tactic is right here.4
For reference, a decrease Brier rating is healthier. 0 would imply absolute confidence in all the things that finally occurred, 0.25 would imply a sequence of fifty% hedged guesses on something occurring, and randomly guessing from 0% to 100% for each query would yield a Brier rating of 0.33.5
Additionally fascinating is the Brier rating relative to others who forecast the identical occasions. We don’t have that when trying on the median of our specialists – however we may simulate a couple of different variations:
Bearish6 – if the specialists all thought every milestone would take 1.5 instances longer than they really thought, they’d’ve gotten a Brier rating of 0.27.
Barely Bearish – if the specialists all thought every milestone would take 1.2 instances longer than they really thought, they’d’ve gotten a Brier rating of 0.25.
Precise forecasts – a Brier rating of 0.21.
Barely Bullish – if the specialists all thought every milestone would take 1.2 instances lower than they really thought, they’d’ve gotten a Brier rating of 0.24.
Bullish – if the specialists all thought every milestone would take 1.5 instances lower than they really thought, they’d’ve gotten a Brier rating of 0.29.
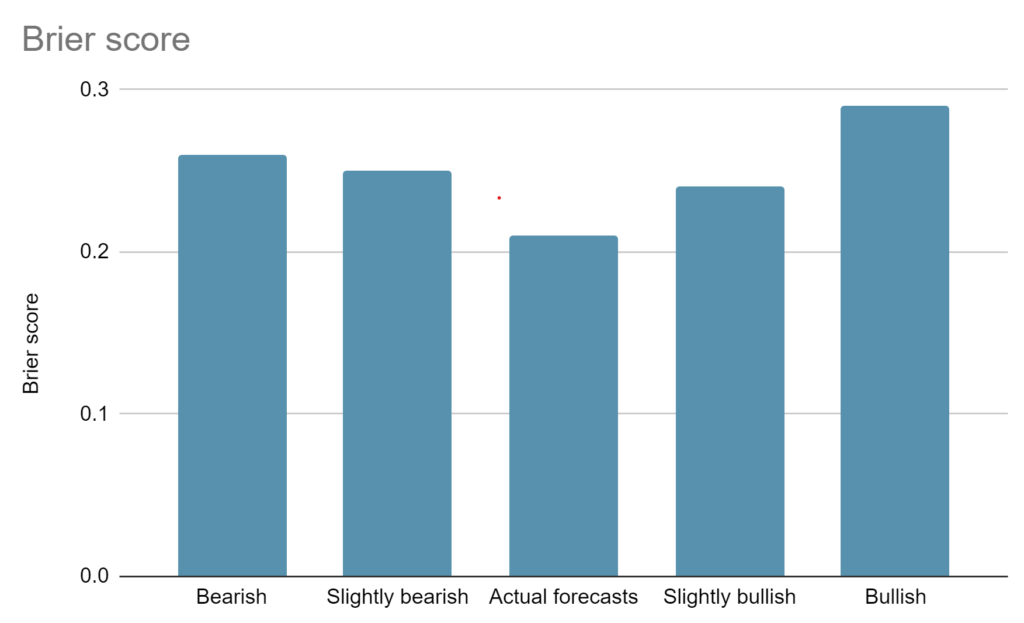
So, the specialists had been basically fairly correct and would have been much less so if they’d been kind of bullish on the velocity of AI improvement (with the identical relative expectations between every milestone).
Taken collectively, I feel this could barely replace us in the direction of the knowledgeable forecasts being helpful in as but unresolved circumstances, and away from the usefulness of estimates which fall outdoors of 1.5 instances additional or nearer than the knowledgeable forecasts.
Randomised – if the specialists’ forecast for every particular milestone had been randomly assigned to any forecasted date for a unique milestone within the assortment, they’d’ve gotten a Bier rating of 0.31 (within the random task I acquired from a random quantity generator).
I feel this could replace us barely in the direction of the surveyed specialists typically being correct on which areas of AI would progress quickest. My evaluation is that, in comparison with the specialists’ predictions, AI has progressed extra shortly in textual content era and coding and extra slowly in recreation enjoying and robotics. It isn’t clear now whether or not this development will proceed, or whether or not different areas in AI will unexpectedly progress extra shortly within the subsequent 5 12 months interval.
Abstract of milestones and forecasts
Within the under desk, the numbers within the cells are the median knowledgeable response to “Years after the (2016) survey for which there’s a ten, 50 and 90% likelihood of the milestone being possible”. The ultimate column is my judgement of whether or not the milestone was in actual fact possible after 5.5 years. Orange shading exhibits forecasts falling inside the 5.5 years between the survey and in the present day. A full description of milestones, and justification of my judgments, are within the appendix.
| Milestone / Confidence of AI reaching the milestone inside X years | 10 p.c | 50 p.c | 90 p.c | True by Feb 2023? (5.5 + 1 years) |
| Translate a new-to-humanity language | 10 | 20 | 50 | FALSE |
| Translate a new-to-it language | 5 | 10 | 15 | FALSE |
| Translate in addition to bilingual people | 3 | 7 | 15 | FALSE |
| Telephone financial institution in addition to people | 3 | 6 | 10 | FALSE |
| Accurately group unseen objects | 2 | 4.5 | 6.5 | TRUE |
| One-shot picture labeling | 4.5 | 8 | 20 | FALSE |
| Generate video from {a photograph} | 5 | 10 | 20 | TRUE |
| Transcribe in addition to people | 5 | 10 | 20 | TRUE |
| Learn aloud higher than people | 5 | 10 | 15 | FALSE |
| Show and generate high theorems | 10 | 50 | 90 | FALSE |
| Win Putnam competitors | 15 | 35 | 55 | FALSE |
| Win Go together with much less gametime | 3.5 | 8.5 | 19.5 | FALSE |
| Win Starcraft | 2 | 5 | 10 | FALSE |
| Win any random pc recreation | 5 | 10 | 15 | FALSE |
| Win indignant birds | 2 | 4 | 6 | FALSE |
| Beat professionals in any respect Atari video games | 5 | 10 | 15 | FALSE |
| Win Atari with 20 minutes coaching | 2 | 5 | 10 | FALSE |
| Fold laundry in addition to people | 2 | 5.5 | 10 | FALSE |
| Beat a human in a 5km race | 5 | 10 | 20 | FALSE |
| Assemble any LEGO | 5 | 10 | 15 | FALSE |
| Effectively kind very giant lists | 3 | 5 | 10 | TRUE |
| Write good Python code | 3 | 10 | 20 | TRUE |
| Solutions factoids higher than specialists | 3 | 5 | 10 | TRUE |
| Reply open-ended questions effectively | 5 | 10 | 15 | TRUE |
| Reply unanswered questions effectively | 4 | 10 | 17.5 | TRUE |
| Excessive marks for a highschool essay | 2 | 7 | 15 | FALSE |
| Create a high forty music | 5 | 10 | 20 | FALSE |
| Produce a Taylor Swift music | 5 | 10 | 20 | FALSE |
| Write a NYT bestseller | 10 | 30 | 50 | FALSE |
| Concisely clarify its recreation play | 5 | 10 | 15 | TRUE |
| Win World Collection of Poker | 1 | 3 | 5.5 | TRUE |
| Output legal guidelines of physics of digital world | 5 | 10 | 20 | FALSE |
Caveats:
My judgements of which forecasts have turned out true or false are just a little subjective. This was made tougher by the survey query asking which duties had been ‘possible’, the place possible meant ‘if among the finest resourced labs may implement it in lower than a 12 months in the event that they selected to. Ignore the query of whether or not they would select to.’ I’ve interpreted this as, one 12 months after the forecasted date, have AI labs achieved these milestones, and disclosed this publicly?
Given (a) ‘has occurred’ implies ‘possible’, however ‘possible’ doesn’t suggest ‘has occurred’ and (b) labs might have achieved a few of these milestones however not disclosed it, I’m most likely being conservative within the general variety of duties which have been accomplished by labs. I’ve not tried to offset this conservatism through the use of my judgement of what labs can most likely obtain in personal. When you disagree or have insider information of capabilities, you could be taken with modifying my working right here. Please attain out in order for you a proof of the tactic, or to privately share updates – patrick at rethinkpriorities dot org.
It’s not apparent that forecasting accuracy on these nearer-term questions may be very predictive of forecasting accuracy on the longer-term questions. Dillon (2021) notes “There’s some proof that forecasting ability generalises throughout matters (see Superforecasting, Tetlock, 2015 and for a short overview see right here) and this would possibly inform a previous that good forecasters within the brief time period will even be good over the long run, however there could also be particular changes that are price emphasising when forecasting in several temporal domains.” I’ve not discovered any proof both manner on whether or not good forecasters within the brief time period will even be good over the long run, however this does appear attainable to analyse from the info that Dillon and niplav gather.8
Lastly, there are caveats within the unique survey price noting right here, too. For instance, how the query is framed makes a distinction to forecasts, even when the that means is similar. As an example this, the authors be aware
“Folks persistently give later forecasts should you ask them for the likelihood in N years as an alternative of the 12 months that the likelihood is M. We noticed this within the easy HLMI (high-level machine intelligence) query and many of the duties and occupations, and in addition in most of this stuff after we examined them on mturk individuals earlier. For HLMI as an example, should you ask when there might be a 50% probability of HLMI you get a median reply of 40 years, but should you ask what the likelihood of HLMI is in 40 years, you get a median reply of 30%.”
That is generally true of the ‘Slim duties’ forecasts (though I disagree with the authors that it’s persistently so).9 For instance, when requested when there’s a 50% probability AI can write a high forty hit, respondents gave a median of 10 years. But when requested in regards to the likelihood of this milestone being reached in 10 years, respondents gave a median of 27.5%.
What does this all imply for us?
Perhaps not an enormous quantity at this level. It’s most likely just a little too early to get image of the specialists’ accuracy, and there are a couple of necessary caveats. However this could replace you barely in the direction of the specialists’ timelines should you had been sceptical of their forecasts. Inside one other 5 years, we could have ~twice the info and sense of how the specialists carried out throughout their 50% estimates.
It’s also limiting to have just one complete survey of AI specialists which incorporates each long-term and shorter-term timelines. What could be glorious for assessing accuracy is detailed forecasts from varied totally different teams, together with political pundits, technical specialists, {and professional} forecasters, with which we will examine accuracy between teams. It might be simpler to analyse the forecasting accuracy of the questions targeted on what developments have occurred, fairly than what developments are possible. We may strive nearer to residence, perhaps the typical EA could be higher at forecasting developments than the typical AI knowledgeable – it appears price testing now to offer us some extra knowledge in ten years!

It is a weblog put up, not a analysis report, that means it was produced shortly and isn’t to our typical requirements of substantiveness and cautious checking for accuracy. I’m grateful to Alex Lintz, Amanda El-Dakhakhni, Ben Cottier, Charlie Harrison, Oliver Visitor, Michael Aird, Rick Korzekwa, and Zach Stein-Perlman for feedback on an earlier draft.
In case you are taken with RP’s work, please go to our analysis database and subscribe to our publication.
Cross-posted to EA Discussion board, Lesswrong, and this google doc.
Footnotes
- I solely analysed this ‘fastened possibilities’ query and never the choice ‘fastened years’ query, which requested:
“How probably do you suppose it’s that the next AI duties might be possible inside the subsequent:
– 10 years?
– 20 years?
– 50 years?”
We aren’t but at any of those dates, so the evaluation could be rather more unclear. - 9 = 4*5% + 14*15% + 6*30% + 5*55% + 2*80% + 1*90%
- A exact quantity as a Brier rating doesn’t suggest an correct evaluation of forecasting skill – ideally, we may work with a bigger dataset (i.e. extra surveys, with extra questions) to get extra accuracy.
- My methodology for the Brier rating calculations relies on rounding all the way down to the closest given forecast, or rounding as much as the ten% mark. For instance, if a ten% probability was given at 3 years, and a 50% probability at 10 years, the forecast was taken to be 10%, fairly than estimating a full likelihood distribution and discovering the 5.5 years level. This skews the knowledgeable forecasts in the direction of being extra conservative and unfairly penalises them. If the specialists gave a ten% probability of X occurring in 3 years, I didn’t test whether or not it had occurred in 3 years, however as an alternative checked if it had occurred by now. I estimate these two elements (the primary skewing the forecasts to be extra begives a roughly stability 5-10% improve to the Brier rating, given most milestones included a likelihood on the 5 12 months mark. A greater evaluation would estimate the likelihood distributions implied by every 10, 50, 90% level likelihood, then assess the likelihood implied at 5.5 years.
- For extra element, see Brier rating – Wikipedia.
- By ‘bearish’ and ‘bullish’ I imply anticipating AI milestones to be met later or sooner, respectively.
- The rating breakdown and methodology for these calculations can also be right here.
- This appears priceless, and I’m undecided why it hasn’t been analysed but.
Considerably related sources:https://discussion board.effectivealtruism.org/posts/hqkyaHLQhzuREcXSX/data-on-forecasting-accuracy-across-different-time-horizonshttps://www.lesswrong.com/posts/MquvZCGWyYinsN49c/range-and-forecasting-accuracyhttps://www.openphilanthropy.org/analysis/how-feasible-is-long-range-forecasting/https://discussion board.effectivealtruism.org/matters/long-range-forecasting - I sampled ten forecasts the place possibilities got on a ten 12 months timescale, and 5 of them (Subtitles, Transcribe, High forty, Random recreation, Clarify) gave later forecasts when requested with a ‘likelihood in N years’ framing fairly than a ‘12 months that the likelihood is M’ framing, three of them (Video scene, Learn aloud, Atari) gave the identical forecasts, and two of them (Rosetta, Taylor) gave an earlier forecast. This is the reason I disagree it results in persistently later forecasts.