
The Phase Something Mannequin (SAM), a current innovation by Meta’s FAIR (Fundamental AI Research) lab, represents a pivotal shift in laptop imaginative and prescient. This state-of-the-art occasion segmentation mannequin showcases a groundbreaking capability to carry out advanced picture segmentation duties with unprecedented precision and flexibility.
Not like conventional fashions that require intensive coaching on particular duties, the segment-anything mission design takes a extra adaptable method. Its creators took inspiration from current developments in pure language processing (NLP) with basis fashions.
SAM’s game-changing affect lies in its zero-shot inference capabilities. Because of this SAM can precisely phase pictures with out prior particular coaching, a process that historically requires tailor-made fashions. This leap ahead is because of the affect of basis fashions in NLP, comparable to GPT and BERT.
These fashions revolutionized how machines perceive and generate human language by studying from huge information, permitting them to generalize throughout numerous duties. SAM applies an analogous philosophy to laptop imaginative and prescient, utilizing a big dataset to grasp and phase all kinds of pictures.
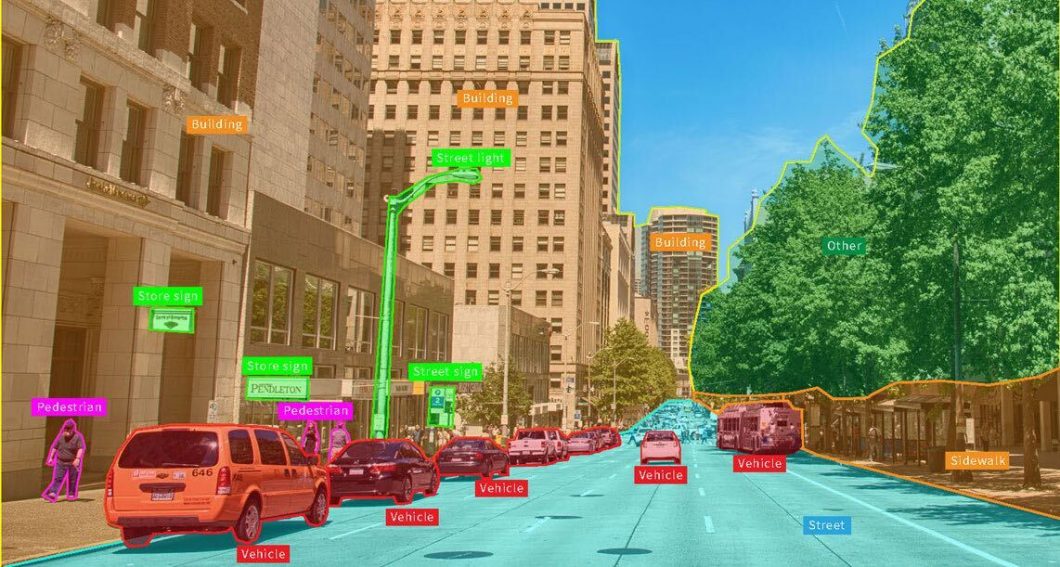
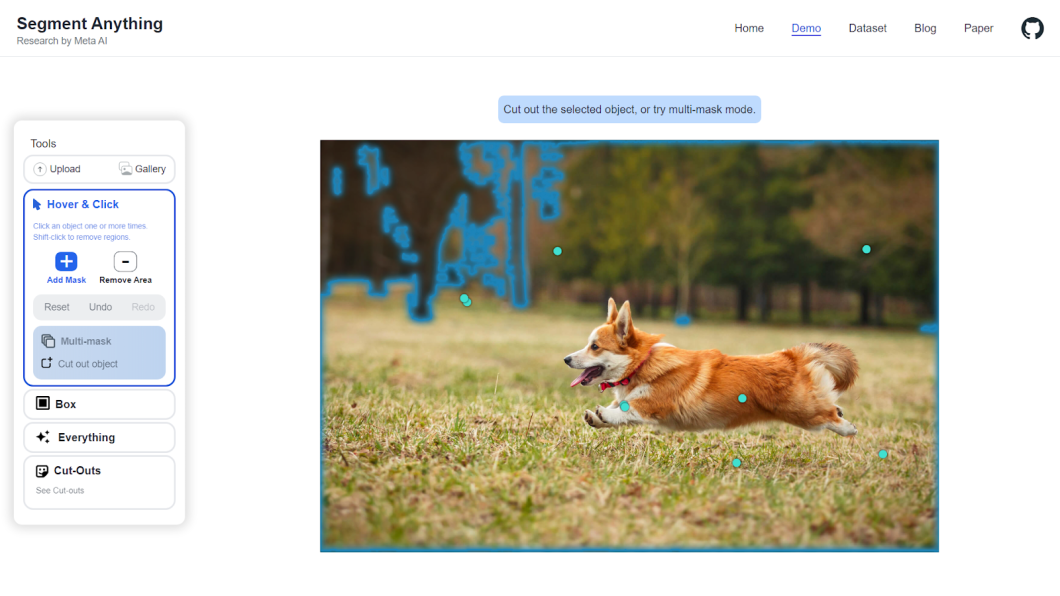
One in every of its standout options is the power to course of a number of prompts. You may hover or click on on parts, drag bins round them, robotically phase the whole lot, and create customized masks or cut-outs.
Whereas efficient in particular areas, earlier fashions usually wanted intensive retraining to adapt to new or diverse duties. Thus, SAM is a big shift in making these fashions extra versatile and environment friendly, setting a brand new benchmark for laptop imaginative and prescient.

Pc Imaginative and prescient at Meta: A Temporary Historical past
Meta, previously generally known as Fb, has been a key participant in advancing AI and laptop imaginative and prescient applied sciences. The journey started with foundational work in machine studying, resulting in vital contributions which have formed at the moment’s AI panorama.
Over time, Meta has launched a number of influential fashions and instruments. The event of PyTorch, a preferred open-source machine studying library, marked a big milestone, providing researchers and builders a versatile platform for AI experimentation and deployment.
The introduction of the Phase Something Mannequin (SAM) represents a end result of those efforts, standing as a testomony to Meta’s ongoing dedication to innovation in AI. SAM’s refined method to picture segmentation demonstrates a leap ahead within the firm’s AI capabilities, showcasing superior understanding and manipulation of visible information.
Right now, the pc imaginative and prescient mission has gained monumental momentum in cellular purposes, automated picture annotation instruments, and facial recognition and picture classification purposes.

Phase Something Mannequin (SAM)’s Community Structure and Design
SAM’s revolutionary capabilities are largely because of its revolutionary structure. It’s made up of three fundamental parts: the picture encoder, immediate encoder, and masks decoder.
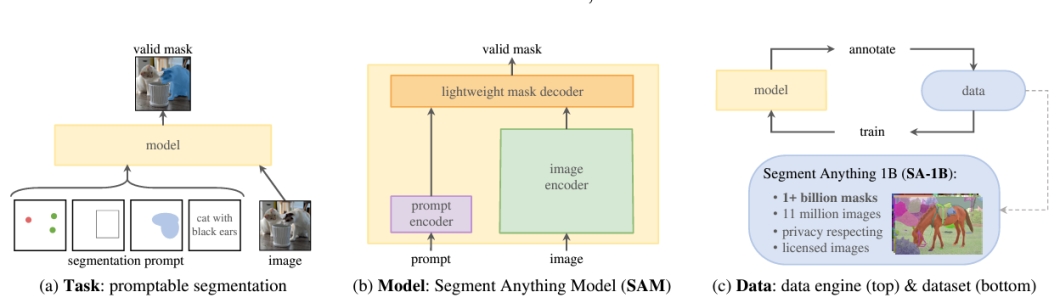
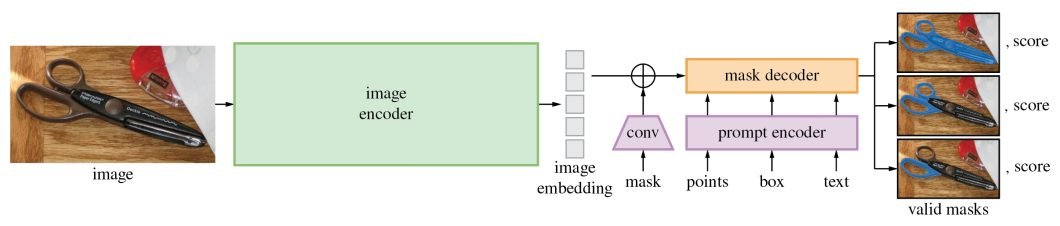
Picture Encoder
- The picture encoder is on the core of SAM’s structure, a complicated element chargeable for processing and remodeling enter pictures right into a complete set of options.
- Utilizing a transformer-based method, like what’s seen in superior NLP fashions, this encoder compresses pictures right into a dense characteristic matrix. This matrix types the foundational understanding from which the mannequin identifies numerous picture parts.
Immediate Encoder
- The immediate encoder is a singular side of SAM that units it other than conventional picture segmentation fashions.
- It interprets numerous types of enter prompts, be they text-based, factors, tough masks, or a mixture thereof.
- This encoder interprets these prompts into an embedding that guides the segmentation course of. This permits the mannequin to deal with particular areas or objects inside a picture because the enter dictates.
Masks Decoder
- The masks decoder is the place the magic of segmentation takes place. It synthesizes the data from each the picture and immediate encoders to supply correct segmentation masks.
- This element is chargeable for the ultimate output, figuring out the exact contours and areas of every phase inside the picture.
- How these parts work together with one another is equally very important for efficient picture segmentation as their capabilities:
- The picture encoder first creates an in depth understanding of the whole picture, breaking it down into options that the engine can analyze.
- The immediate encoder then provides context, focusing the mannequin’s consideration primarily based on the supplied enter, whether or not a easy level or a posh textual content description.
- Lastly, the masks decoder makes use of this mixed data to phase the picture precisely, making certain that the output aligns with the enter immediate’s intent.
The Phase Something Mannequin Technical Spine: Convolutional, Generative Networks, and Extra
Convolutional Neural Networks (CNNs) and Generative Adversarial Networks (GANs) play a foundational function within the capabilities of SAM. These deep studying fashions are central to the development of machine studying and AI, notably within the realm of picture processing. They supply the underpinning that makes SAM’s refined picture segmentation attainable.
Convolutional Neural Networks (CNNs)
CNNs are integral to the picture encoder of the Phase Something Mannequin structure. They excel at recognizing patterns in pictures by studying spatial hierarchies of options, from easy edges to extra advanced shapes.
In SAM, CNNs analyze and interpret visible information, effectively processing pixels to detect and perceive numerous options and objects inside a picture. This capability is essential for SAM’s structure’s preliminary picture evaluation stage.
Generative Adversarial Networks (GANs)
GANs contribute to SAM’s capability to generate exact segmentation masks. Consisting of two elements, the generator, and the discriminator, GANs are adept at understanding and replicating advanced information distributions.
The generator focuses on producing lifelike pictures, and the discriminator evaluates these pictures to find out if they’re actual or artificially created. This dynamic enhances the generator’s capability to create extremely real looking artificial pictures.

How CNNs and GANs Complement Every Different
The synergy between CNNs and GANs inside SAM’s framework is important. Whereas CNNs present a strong technique for characteristic extraction and preliminary picture evaluation, GANs improve the mannequin’s capability to generate correct and real looking segmentations.
This mixture permits SAM to grasp a big selection of visible inputs and reply with excessive precision. By integrating these applied sciences, SAM represents a big leap ahead, showcasing the potential of mixing completely different neural community architectures for superior AI purposes.
CLIP (Contrastive Language-Picture Pre-training)
CLIP, developed by OpenAI, is a mannequin that bridges the hole between textual content and pictures.
CLIP’s capability to grasp and interpret textual content prompts in relation to photographs is invaluable to how SAM works. It permits SAM to course of and reply to text-based inputs, comparable to descriptions or labels, and relate them precisely to visible information.
This integration enhances SAM’s versatility, enabling it to phase pictures primarily based on visible cues and observe textual directions.

Switch Studying and Pre-trained Fashions:
Switch studying entails using a mannequin educated on one process as a basis for one more associated process. Pre-trained fashions like ResNet, VGG, and EfficientNet, which have been extensively educated on giant datasets, are prime examples of this.
ResNet is understood for its deep community structure, which solves the vanishing gradient downside, permitting it to study from an enormous quantity of visible information. VGG is admired for its simplicity and effectiveness in picture recognition duties. EfficientNet, however, supplies a scalable and environment friendly structure that balances mannequin complexity and efficiency.
Utilizing switch studying and pre-trained fashions, SAM positive aspects a head begin in understanding advanced picture options. That is important for its excessive accuracy and effectivity in picture segmentation. This makes SAM highly effective and environment friendly in adapting to new segmentation challenges.

The SA-1B Dataset: A New Milestone in AI Coaching
SAM’s true superpower is its coaching information, referred to as the SA-1B Dataset. Brief for Phase Something 1 Billion, it’s essentially the most intensive and numerous picture segmentation dataset obtainable.
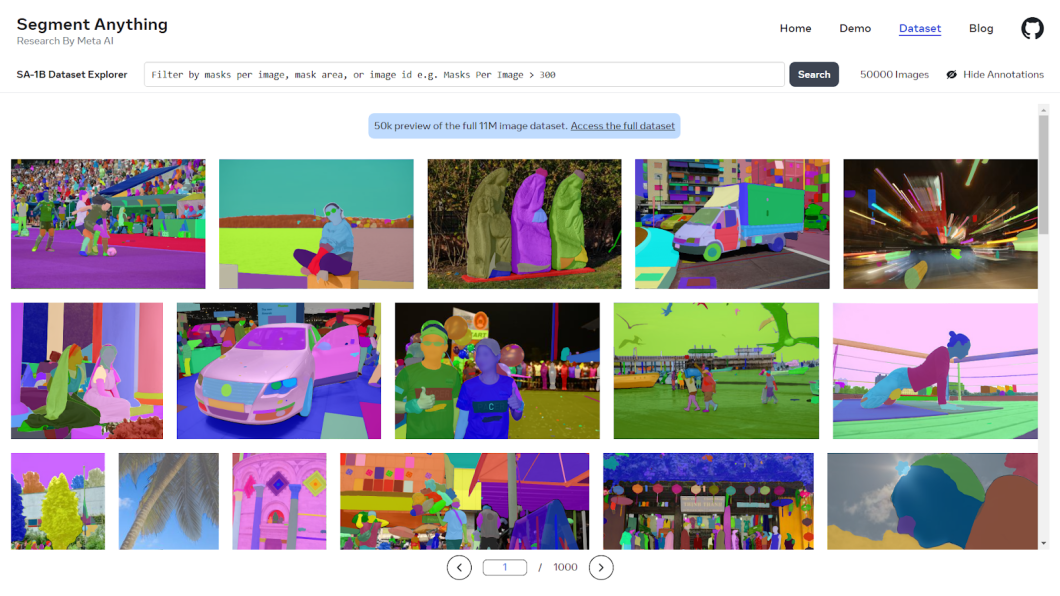
It encompasses over 1 billion high-quality segmentation masks derived from an enormous array of 11 million pictures and covers a broad spectrum of eventualities, objects, and environments. SA-1B is an unparalleled, high-quality useful resource curated particularly for coaching segmentation fashions.
Creating this dataset took a number of levels of manufacturing:
- Assisted Handbook: On this preliminary stage, human annotators work alongside the Phase Something Mannequin, making certain that each masks in a picture is precisely captured and annotated.
- Semi-Automated: Annotators are tasked with specializing in areas the place SAM is much less assured, refining and supplementing the mannequin’s predictions.
- Full-Auto: SAM independently predicts segmentation masks within the last stage, showcasing its capability to deal with advanced and ambiguous eventualities with minimal human intervention.
The vastness and number of the SA-1B Dataset push the boundaries of what’s achievable in AI analysis. Such a dataset permits extra sturdy coaching, permitting fashions like SAM to deal with an unprecedented vary of picture segmentation duties with excessive accuracy. It supplies a wealthy pool of knowledge that enhances the mannequin’s studying, making certain it might probably generalize properly throughout completely different duties and environments.
Phase Something Mannequin Sensible Functions and Future Potential
As a large leap ahead in picture segmentation, SAM can be utilized in nearly each attainable utility.
Listed below are a few of the purposes wherein SAM is already making waves:
- AI-Assisted Labeling: SAM considerably streamlines the method of labeling pictures. It will probably robotically determine and phase objects inside pictures, drastically lowering the effort and time required for handbook annotation.
- Medication Supply: In healthcare, SAM’s exact segmentation capabilities allow the identification of particular areas for drug supply. Thus, making certain precision in therapy and minimizing unwanted effects.
- Land Cowl Mapping: SAM may be utilized to categorise and map several types of land cowl, enabling purposes in city planning, agriculture, and environmental monitoring.

SAM’s potential extends past present purposes. In fields like environmental monitoring, it might assist in analyzing satellite tv for pc imagery for local weather change research or catastrophe response.
In retail, SAM might revolutionize stock administration by way of automated product recognition and categorization.
SAM’s unequaled adaptability and accuracy positions it to be the brand new commonplace in picture segmentation. Its capability to study from an enormous and numerous dataset means it might probably constantly enhance and adapt to new challenges.
We will count on SAM to evolve with higher real-time processing capabilities. With this evolution, we will count on to see SAM turn into ubiquitous in fields like autonomous automobiles and real-time surveillance. Within the leisure trade, we might see developments in visible results and augmented actuality experiences.