Information annotation permits machine studying algorithms to grasp and interpret info. The annotations are labels that establish and classify knowledge or affiliate totally different items of knowledge with one another. AI algorithms use them as floor truths to regulate their weights accordingly. The labels are task-dependent and may be additional categorized as a picture or textual content annotation.
Textual content annotations affiliate that means with textual info for ML algorithms to grasp. They generate labels that permit ML algorithms to interpret the textual content in a human-like vogue. The method includes classifying blocks of textual content, tagging textual content components for semantic annotation and understanding, or associating intent with conversational knowledge. Every of those methodologies trains machine studying fashions for various sensible use instances.
The article will talk about the next key factors:
- Definition and significance of textual content annotation
- Textual content Annotation Methodologies
- Textual content Annotation Use Circumstances
About us: Viso.ai offers a strong end-to-end no-code laptop imaginative and prescient answer – Viso Suite. Our software program helps a number of main organizations begin with laptop imaginative and prescient and implement deep studying fashions effectively with minimal overhead for varied downstream duties. Get a demo right here.
What’s Textual content Annotation?
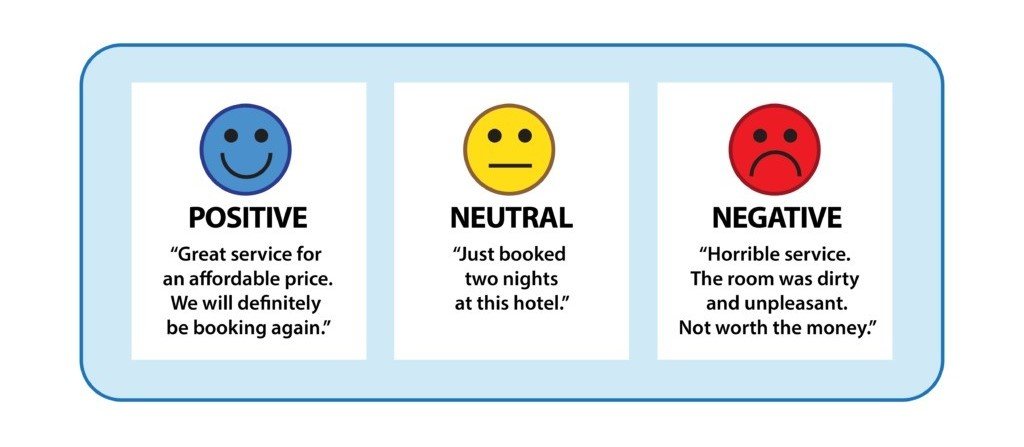
The textual content annotation course of goals to generate that means from the textual content by highlighting key options akin to elements of speech, semantic hyperlinks, or basic sentiment or intent of the doc. Every annotation process labels textual content in a different way and is used for various use instances. A sentiment evaluation utility requires blocks of textual content to be categorized right into a sentiment class. Sentiment annotations are created as follows:
“The sky is blue” – Impartial
“I’m very excited in regards to the area journey to the museum” – Pleased
“I ought to have scored larger on the maths check. It’s not honest.” – Offended
Nonetheless, not all textual content annotations are achieved as above. For instance, in semantic understanding, we label every a part of a sentence individually, akin to the topic and object.
The textual content paperwork and their related annotations (labels) are used to coach ML fashions for textual content understanding. The mannequin learns to affiliate the annotations with the offered enter corpus after which replicates the identical affiliation with unseen knowledge.
Challenges for Textual content Annotation
The annotation course of is easy, but it surely carries sure challenges. The challenges hamper the annotation high quality and impression mannequin efficiency. These embody:
- Time-Consuming: Textual content corpora may be intensive, and manually labelling the complete dataset is time and resource-consuming. Sure AI-assisted annotation instruments do pace up the method, however their efficiency varies as a result of unstructured nature of the information, and human involvement is a necessity.
- Mis-classified Intent: Sentiments and intents in textual content paperwork may be tough to decipher. Actual-world datasets are full of ambiguities like sarcasm, making annotating the person’s intent or emotions tough.
- Textual content Variations: Textual content is a type of expression and might have the identical that means even with totally different buildings or wording. A top quality dataset should embody all such variations and be annotated. Variety will increase the complexity of collected and annotated knowledge.
Kinds of Textual content Annotation Strategies
Textual content may be labelled utilizing varied strategies, and every annotation methodology targets a unique downside. Listed below are a number of the most distinguished textual content annotation strategies used within the machine studying area.
Textual content Classification
Textual content paperwork may be categorized into totally different classes relying on the duty at hand. The classification course of related every textual content doc with a single label, and this affiliation is later used to coach ML algorithms. It may be additional categorized as follows:
- Sentiment Annotation: Texts like buyer evaluations and social media posts normally categorical totally different sentiments. Such textual content chunks may be categorized into lessons like ‘Pleased,’ ‘Unhappy,’ ‘Offended,’ or ‘Excited.’ The annotations may be additional simplified by lowering the lessons to ‘Optimistic,’ ‘Unfavourable,’ or ‘Impartial.’ Class granularity is determined primarily based on the duty necessities. Sentiment annotations practice sentiment classifiers used within the retail enterprise for product evaluate evaluation.
- Matter Modelling: Textual content paperwork will also be categorized in accordance with the data they comprise and the subject they symbolize. For instance, academic texts may be categorized into topics like ‘Arithmetic,’ ‘Physics,’ ‘Biology’ and many others. These subjects act as labels for the corpus and energy subject modeling functions. Furthermore, subject modeling annotations are additionally utilized in LLMs to assist the chatbot perceive the context.
- Spam Annotation: Textual content collections from emails or messaging platforms may be annotated as ‘Spam’ or ‘Protected.’ These annotations are used to coach spam classifiers for safety functions.
Entity Tagging
Pure language textual content contains varied components that give that means to the textual content’s semantics. Entity tagging labels these components into their respective lessons. The kind of entities tagged depends on the issue to be addressed. Understanding textual content semantics and its grammatical construction requires tagging elements of pace (POS), like nouns, verbs, and adjectives.
Different issues requiring generic understanding require tagging named entities like individuals and locations and recognizing components like addresses, contact numbers, and many others.

An essential distinction between classification and entity tagging is that the previous assigns a single label to a complete doc. In distinction, the latter assigns a label to each phrase within the doc.
Entity Linking
Entity linkage is just like entity tagging because it additionally identifies particular person components current inside the textual content. Nonetheless, it goals to hyperlink the current entity to an exterior data base to create a wider context. For instance, within the textual content, “Elon Musk is the founding father of SpaceX”, entity linking would hyperlink ‘Elon Musk’ to the related info within the database to grasp who the individual is to higher perceive the textual content.
Intent Annotation
Chatbots acknowledge textual content instructions primarily based on the person’s intent and attempt to generate an applicable response. Intent annotation classifies the textual content into intent classes akin to request, query, command, and many others. These permit chatbots to navigate the dialog and reply queries or execute actions.
Sequence-to-Sequence Annotation
Trendy sequence-to-sequence fashions map a textual content sequence onto one other. A well-liked instance is textual content summarization fashions that settle for a big textual content physique as enter and output a considerably compressed sequence. One other case is human language translation, the place the output is an analogous sequence to the enter however in a unique language.
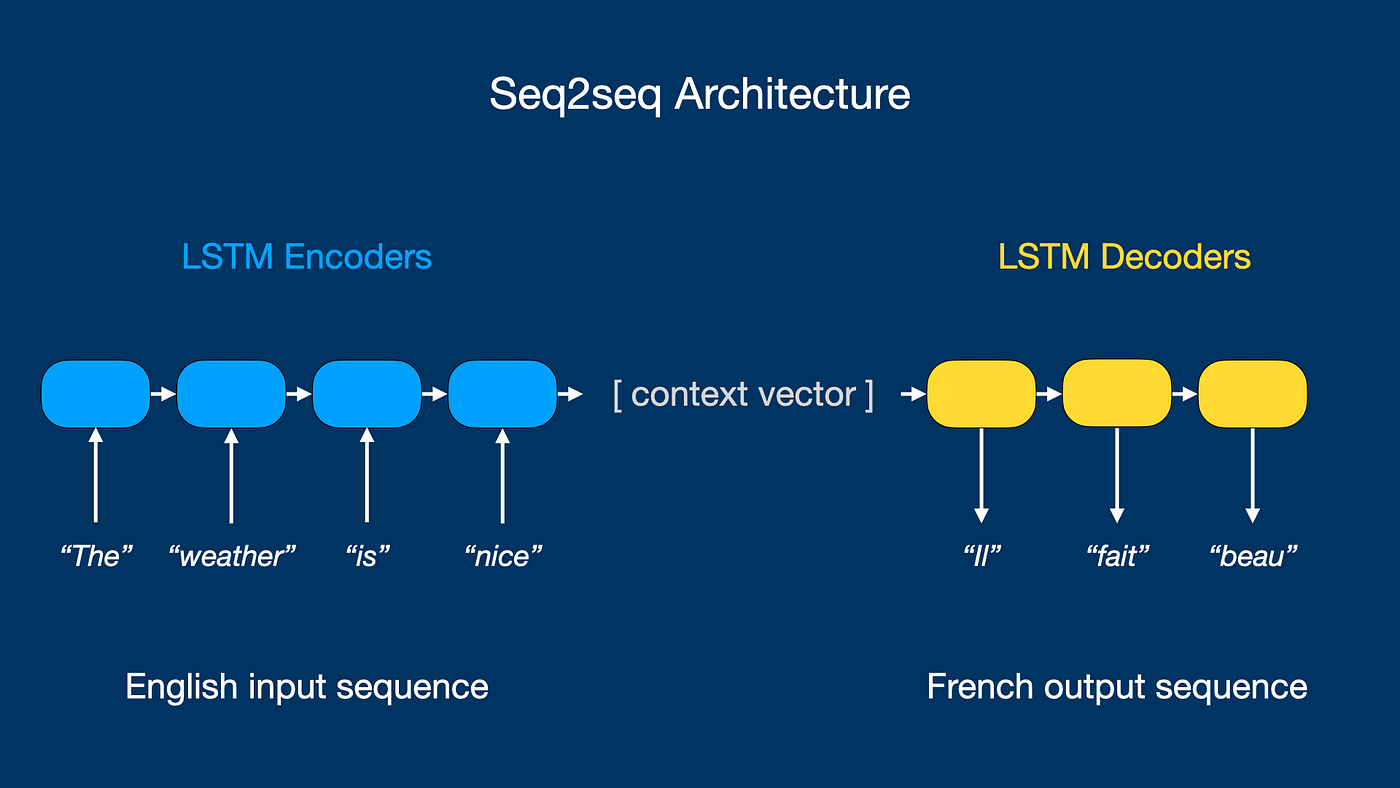
In both utility, the annotations are additionally sequences of textual content that hyperlink to the unique textual content doc. For instance, for the sentence ‘The climate is sweet’, the annotation for a French translation mannequin can be the next sequence ‘il fait beau’.
Functions
The textual content annotation strategies mentioned above energy varied Pure Language Processing (NLP) functions. The functions have a number of use instances in varied domains. They permit the automation of time-consuming duties and change handbook labor with computer-operated workflows. Let’s talk about some key use instances of textual content annotation.
Named Entity Recognition (NER)
NER is a well-liked NLP utility that identifies entities current inside the textual content. The entities can embody names, areas, date, and time. These entities permit computer systems to research textual content and execute automated workflows. For instance, NER fashions can acknowledge the situation, date, and time talked about in company emails and set computerized reminders for a gathering.
Additionally it is used to extract helpful entities from massive our bodies of textual content. Medical practitioners can use it to retrieve medication and affected person names from massive medical information to grasp what was prescribed to what affected person.
Furthermore, NER fashions additionally make the most of context home windows to grasp the entity’s identification. For instance, within the sentence ‘Paris is a gorgeous place’, the corresponding textual content helps establish that ‘Paris’ is a location and never an individual.
Buyer Assist Chatbots
Chatbots are shortly fulfilling the necessity for environment friendly buyer dealing and help. Trendy chatbots use a mixture of classification, entity tagging, and intent identification to interrupt down a buyer question. The talked about strategies assist them perceive the semantics and reply appropriately.
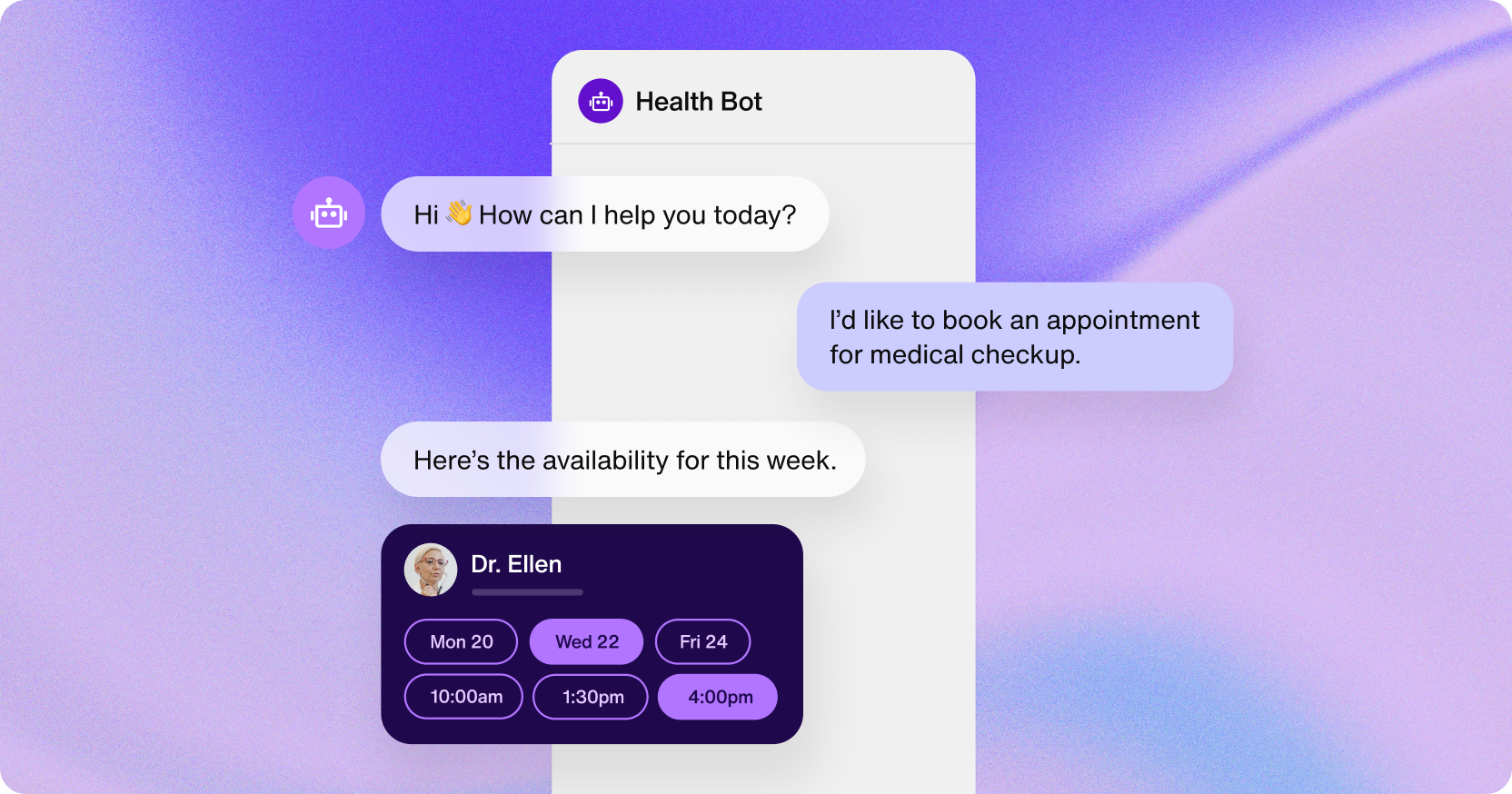
They will acknowledge entities from the textual content to grasp which product or class an individual is referring to. Moreover, they will establish the person’s intent, whether or not they’re inquiring a couple of product, requesting a refund, or registering a criticism. The intent classification helps the chatbot generate applicable responses and execute required actions. Furthermore, additionally they make the most of sentiment evaluation to acknowledge whether or not a buyer is offended or upset and redirect the question to a human.
Buyer Evaluation
Prospects usually submit product evaluations on social media or by way of a chosen portal from the corporate. Sentiment evaluation permits companies to segregate these evaluations into positives and negatives with out going via them manually. The destructive evaluations are additional noticed for any recurring patterns or merchandise that require fixing. Sentiment evaluation helps organizations enhance product high quality and buyer satisfaction.
Article Segregation
Methods like subject modelling and entity recognition segregate articles into totally different topics. That is significantly distinguished for information broadcasters, who segregate information articles into subjects akin to politics, social points, international information, and many others. The identical strategies are utilized by social media platforms to categorize content material into subjects.
The categorized paperwork are additional analyzed for hate speech or trending topics. These analyses are used to develop new options to draw new customers.
Textual content Annotation: Key Takeaways
Pure Language Processing (NLP) is an integral a part of the AI ecosystem and has varied functions powered quite a few workflows. Behind these NLP fashions are the textual content annotations that add that means to the textual content permit fashions to be taught pure language patterns.
This text mentioned textual content annotation intimately, masking the varied strategies used and their use instances within the trade. Right here’s what we realized:
- Textual content annotations affiliate labels with blocks of textual content.
- Annotating textual content is difficult as a result of unstructured and ambiguous nature of the information.
- Standard textual content annotation strategies embody:
- Sentiment Classification
- Matter Classification
- Entity Recognition
- Intent Classification
- Entity Linkage
- Classification annotations usually affiliate a single label with a complete textual content doc.
- Entity-level annotations affiliate labels with particular person phrases.
Textual content annotation powers varied NLP use instances like sentiment evaluation, chatbots, and doc evaluation. Listed below are some extra sources to compensate for the newest AI developments:
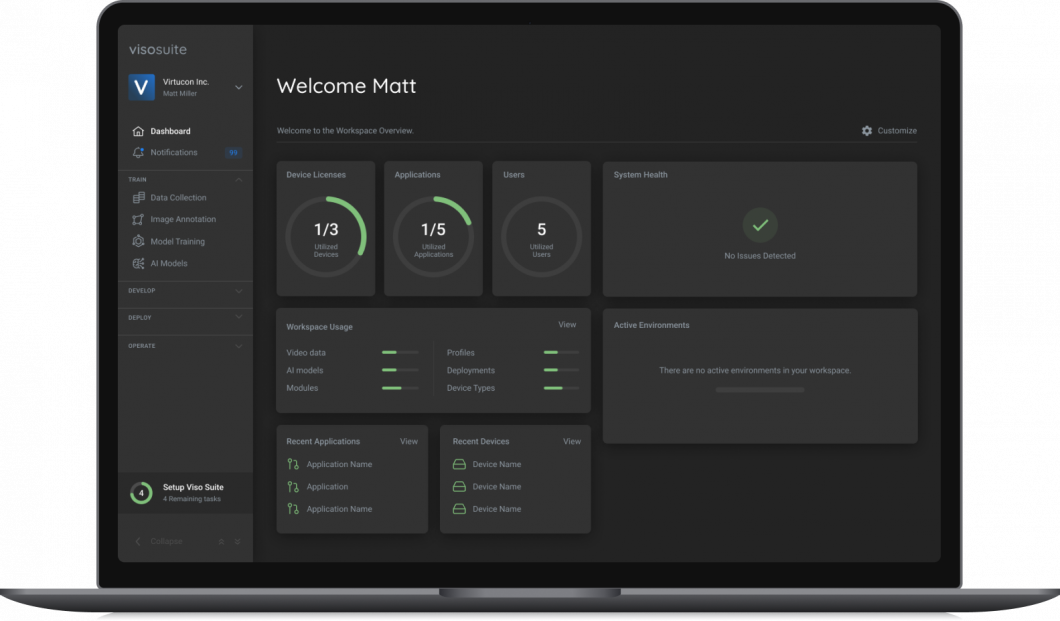
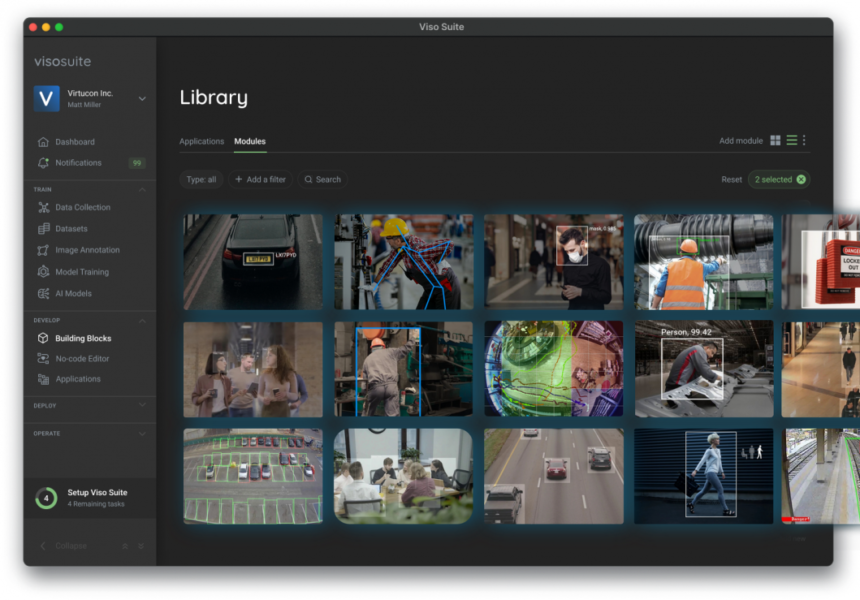
Discover Picture Annotation with Viso Suite
Trendy laptop imaginative and prescient algorithms require an unlimited quantity of knowledge for annotated initiatives. Viso Suite provides a picture annotation platform that encourages effectivity and collaboration. The toolset provides semi-automatic annotation for creating high-quality datasets that’s shared and reviewed throughout the staff.
Viso.ai offers a no-code end-to-end platform for creating and deploying CV functions. We provide an unlimited library of vision-related fashions with functions throughout varied industries. We additionally provide knowledge administration and annotation options for customized coaching. E book a demo to be taught extra about Viso suite.