

Whether or not you’re constructing a shopper app to acknowledge plant species or an enterprise software to observe workplace safety digicam footage, you’ll have to construct a Machine Studying (ML) mannequin to supply the core performance. In the present day, constructing an ML mannequin is less complicated than ever earlier than utilizing frameworks like Tensorflow. Nonetheless, it’s nonetheless vital to observe a methodical workflow to keep away from constructing a mannequin with poor efficiency or inherent bias.
Constructing a machine studying mannequin consists of seven high-level steps:
1. Drawback Identification
2. Dataset Creation
3. Mannequin Choice
4. Mannequin Coaching
5. Mannequin Evaluation
6. Mannequin Optimization
7. Mannequin Deployment and Upkeep
On this article, we’ll break down what’s concerned in every step, with a give attention to supervised studying fashions.
Step 1: Determine a Drawback for the Mannequin To Resolve
To construct a mannequin, we first have to determine the particular drawback that our mannequin ought to clear up. The issue could possibly be studying pharmaceutical labels utilizing photographs from a lab digicam, to determine threats from a faculty safety digicam feed or the rest.
The instance picture beneath is from a mannequin that was constructed to determine and section individuals inside photographs.

Step 2: Create a Dataset for Mannequin Coaching & Testing
Earlier than we are able to practice a machine studying mannequin, we have to have knowledge on which to coach.
We usually don’t need a pile of unorganized knowledge. Usually, we have to first collect knowledge, then clear the information, and eventually engineer particular knowledge options that we anticipate will probably be most related to the issue we recognized in Step 1.
Knowledge gathering
There are 4 attainable approaches to knowledge gathering. Every depends on totally different knowledge sources.
The primary method is to assemble a proprietary dataset. For instance, if we need to practice a machine studying mannequin to learn labels at a pharmacy, then setting up a proprietary dataset would imply gathering tens of 1000’s to probably tens of thousands and thousands of photographs of labels and having people create a CSV file associating the file title of every picture with the textual content of the label proven in that picture.
As you’d count on, this may be very time-consuming and really costly. Nonetheless, if our meant use case may be very novel (for instance, diagnosing automotive points for BMWs utilizing photographs of the engine block), then setting up a proprietary dataset could also be vital. This method additionally removes the danger of systematic bias in knowledge collected from third events. That may save knowledge scientists quite a lot of time since knowledge preparation and cleansing may be very time-consuming.
The second method is to make use of a number of current datasets. That is normally less expensive and extra scalable than the primary method. Nonetheless, the collected knowledge may also be of decrease high quality.
The third method is to mix a number of current datasets with a smaller proprietary dataset. For instance, if we need to practice a machine studying mannequin to learn pharmaceutical tablet bottle labels, we’d mix a big normal dataset of photographs with textual content with a smaller dataset of labeled tablet bottle photographs.
The fourth method is to create artificial knowledge. That is a complicated method that ought to be used with warning since utilizing artificial knowledge incorrectly can result in unhealthy fashions that carry out fantastically on assessments however terribly in the actual world.
Knowledge cleansing
If we collect knowledge utilizing the second or third method described above, then it’s doubtless that there will probably be some quantity of corrupted, mislabeled, incorrectly formatted, duplicate, or incomplete knowledge that was included within the third-party datasets. By the precept of rubbish in, and rubbish out, we have to clear up these knowledge points earlier than feeding the information into our mannequin.
Exploratory knowledge evaluation & characteristic engineering
When you’ve ever taken a calculus class, chances are you’ll bear in mind doing a “change of variables” to unravel sure issues. For instance, altering from Euclidean x-y coordinates to polar r-theta coordinates. Altering variables can generally make it a lot simpler to unravel an issue (simply attempt writing down an integral for the realm of a circle in Euclidean vs polar coordinates).
Function engineering is only a change of variables that makes it simpler for our mannequin to determine significant patterns than can be the case utilizing the uncooked knowledge. It will probably additionally assist scale back the dimensionality of the enter which might help to keep away from overfitting in conditions the place we don’t have as a lot coaching knowledge as we want.
How will we carry out characteristic engineering? It usually helps to do some exploratory knowledge science.
Strive working some fundamental statistical analyses in your knowledge. Generate some plots of various subsets of variables. Search for patterns.
For instance, in case your mannequin goes to be skilled on audio knowledge, you would possibly need to do a Fourier rework of your knowledge and use the Fourier elements as options.
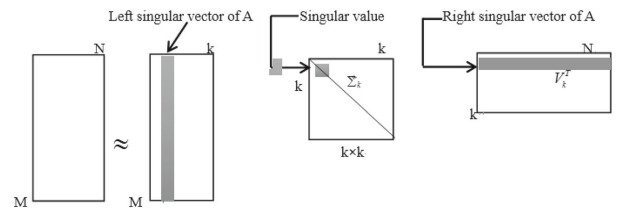
Step 3: Choose a Mannequin Structure
Now that we have now a big sufficient dataset that has been cleaned and feature-engineered, we have to select what kind of mannequin to make use of.
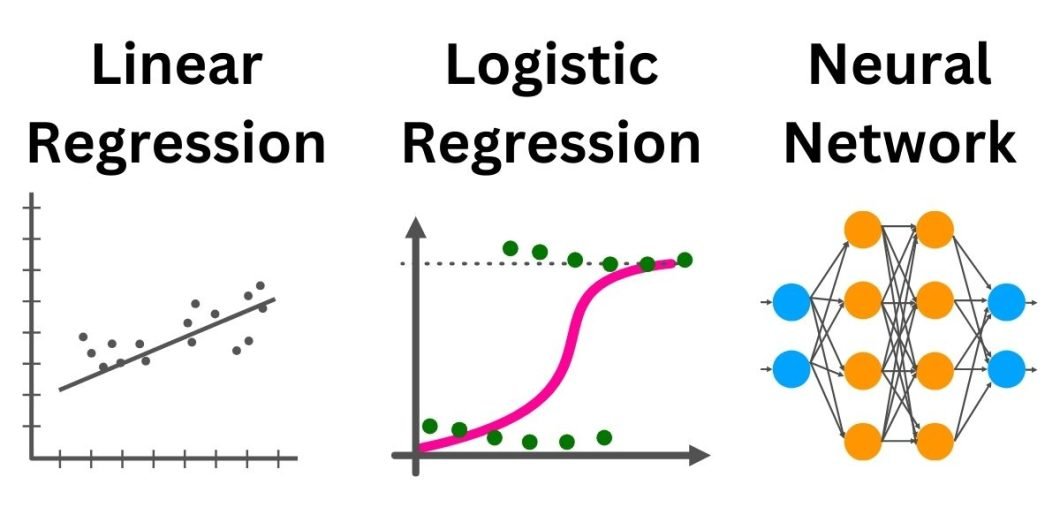
Some widespread kinds of machine studying algorithms embrace:
- Regression fashions (e.g. linear regression, logistic regression, Lasso regression, and ridge regression)
- Convolutional neural networks (these are generally used for laptop imaginative and prescient purposes)
- Recurrent neural networks (these are used on textual content and genomic knowledge)
- Transformers (these have been initially developed for textual content knowledge however have since additionally been tailored to laptop imaginative and prescient purposes)
In the end, the kind of mannequin you choose will depend upon (1) the kind of knowledge that will probably be enter into the mannequin (e.g. textual content vs photographs) and (2) the specified output (e.g. a binary classification or a bounding field for a picture).
Step 4: Practice the Mannequin
As soon as we have now our chosen mannequin and our cleaned dataset with engineered options, we’re prepared to begin coaching our AI mannequin.
Loss capabilities
To begin, we have to select a loss perform. The aim of the loss perform is to inform us how far aside our anticipated and predicted values are on each enter to our mannequin. The mannequin will then be “skilled” by repeatedly updating the mannequin parameters to reduce the loss perform throughout our coaching dataset.
The commonest loss perform is the Imply Squared Error (additionally known as the L2 loss). The L2 loss is a clean perform which suggests it may be differentiated with none points. That makes it straightforward to make use of gradient descent to reduce the loss perform throughout mannequin coaching.
One other widespread loss perform is the Imply Absolute Error (additionally known as the L1 loss). The L1 loss shouldn’t be a clean perform, which suggests it’s tougher to make use of gradient descent to coach the mannequin. Nonetheless, the L1 loss perform is much less delicate to outliers than the L2 loss perform. That may generally make it worthwhile to make use of the L1 loss perform to make the mannequin coaching extra strong.
Coaching knowledge
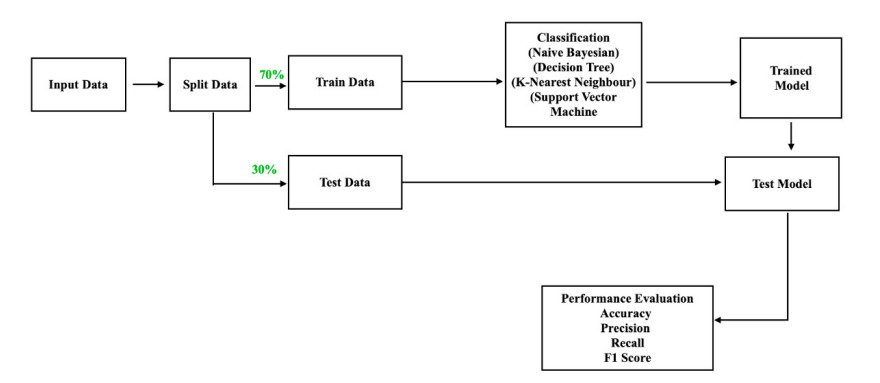
After we select our loss perform, we have to determine how a lot of our knowledge to make use of for coaching and the way a lot to order for testing. We don’t need to practice and take a look at on the identical knowledge in any other case we run the danger of over-fitting our mannequin and overestimating the mannequin’s efficiency based mostly on a statistically flawed take a look at.
It’s widespread apply to make use of 70-80% of your knowledge for coaching and hold the remaining 20-30% for testing.
Coaching process
The high-level coaching process for constructing an AI mannequin is just about the identical no matter the kind of mannequin. Gradient descent is used to discover a native minimal of the loss perform averaged throughout the coaching dataset.
For neural networks, gradient descent is achieved by means of a way known as backpropagation. You may learn extra concerning the concept of backpropagation here. Nonetheless, it’s straightforward to carry out backpropagation in apply with out figuring out a lot concept through the use of libraries like Tensorflow or Pytorch.
Step 5: Mannequin Evaluation
Now that we completed coaching our machine studying mannequin, we have to assess its efficiency.
Mannequin testing
Step one of mannequin evaluation is mannequin testing (additionally known as mannequin validation).
That is the place we calculate the typical worth of the loss perform throughout the information we put aside for testing. If the typical loss on the testing knowledge is just like the typical loss on the coaching knowledge, then our mannequin is nice. Nonetheless, if the typical loss on the testing knowledge is considerably larger than the typical loss on the coaching knowledge, then there’s a drawback both with our knowledge or with our mannequin’s capability to adequately extrapolate patterns from the information.
Cross-validation
The selection of which portion of our knowledge to make use of because the coaching set and which to make use of because the testing set is an arbitrary one, however we don’t need our mannequin’s predictions to be arbitrary. Cross-validation is a way to check how dependent our mannequin efficiency is on the actual method that we select to slice up the information. Profitable cross-validation provides us confidence that our mannequin is definitely generalizable to the actual world.
Cross-validation is simple to carry out. We begin by bucketing our knowledge into chunks. We will use any variety of chunks, however 10 is widespread. Then, we re-train and re-test our mannequin utilizing totally different units of chunks.
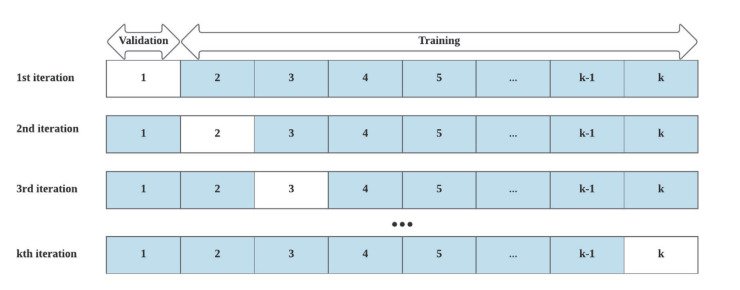
For instance, suppose we bucket our knowledge into 10 chunks and use 70% of our knowledge for testing. Then cross-validation would possibly seem like this:
- Situation 1: Practice on chunks 1-7 and take a look at on chunks 8-10.
- Situation 2: Practice on chunks 4-10 and take a look at on chunks 1-3.
- Situation 3: Practice on chunks 1-3 and 7-10 and take a look at on chunks 4-6.
There are numerous different eventualities we may run as properly, however I feel you see the sample. Every cross-validation situation consists of coaching after which testing our mannequin on totally different subsets of the information.
We hope that the mannequin’s efficiency is comparable throughout all of the cross-validation eventualities. If the mannequin’s efficiency differs considerably from one situation to a different, that could possibly be an indication that we don’t have sufficient knowledge.
Nonetheless, aggressively cross-validating mannequin efficiency on too many subsets of our knowledge may also result in over-fitting as mentioned here.
Decoding outcomes
How are you aware in case your mannequin is performing properly?
You may have a look at the typical loss perform worth to begin. That works properly for some classification duties. Nonetheless, it may be tougher to interpret loss values for regression fashions or picture segmentation fashions.
Having area information definitely helps. It will probably additionally generally assist to carry out some exploratory knowledge evaluation to get an intuitive understanding of how a lot two outputs should differ to supply a sure loss worth.
For classification duties specifically, there are additionally quite a lot of statistical metrics that may be benchmarked:
- Accuracy
- Precision
- Recall
- F1 rating
- Space below the ROC curve (AUC-ROC)
classification mannequin ought to have excessive scores on every of these metrics.
Step 6: Mannequin Optimization
In actuality, the ML workflow for mannequin constructing shouldn’t be a purely linear course of. Quite, it’s an iterative course of. When you decide that your mannequin’s efficiency shouldn’t be as excessive as you want to after going by means of mannequin coaching and evaluation, then chances are you’ll have to do some mannequin optimization. One widespread solution to accomplish that’s by means of hyperparameter tuning.
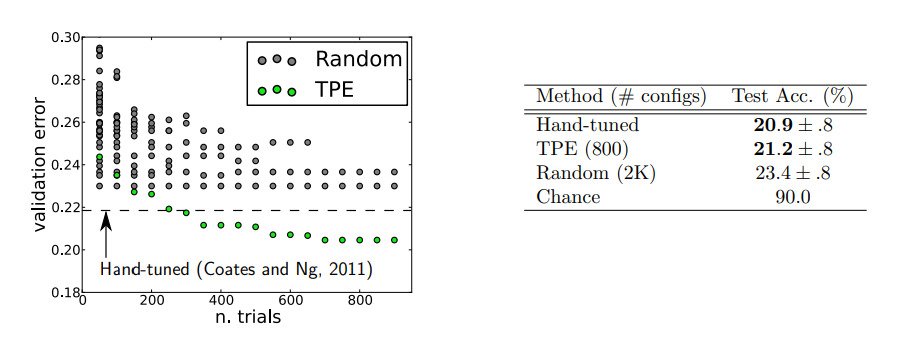
Hyperparameter tuning
Hyperparameters of a machine studying mannequin are parameters which might be fastened earlier than the training course of begins.
Hyperparameter tuning has historically been extra artwork than science. If the variety of hyperparameters is small, you then would possibly be capable of do a brute-force grid search to determine the hyperparameters that yield optimum mannequin efficiency. Because the variety of hyperparameters will increase, AI mannequin builders usually resort to random search by means of hyperparameter area.
Nonetheless, there are additionally extra structured approaches to hyperparameter optimization as described here.
Step 7: Mannequin Deployment & Upkeep
Constructing machine studying fashions is extra than simply a tutorial train. It ought to be one thing that drives enterprise worth, and it might solely do that when it’s deployed.
Mannequin deployment
You may deploy fashions instantly on cloud servers comparable to AWS, Azure, or GCP. Nonetheless, doing so necessitates establishing and sustaining a whole atmosphere. Alternatively, you should use a platform like Viso to deploy your mannequin with considerably much less headache.
There are numerous platforms out there to assist make mannequin deployment simpler.
Mannequin monitoring & upkeep
As soon as our mannequin is deployed, we want to verify nothing breaks it. If we’re working on AWS, Azure, or GCP, which means conserving libraries and containers up to date. It might additionally imply establishing a CI/CD pipeline to automate mannequin updates sooner or later. In the end, having a usable mannequin in manufacturing is the tip aim of our machine studying mission.
Future Developments
Machine studying is a quickly altering discipline, and developments are made each day and weekly, not yearly. Among the present areas of cutting-edge analysis embrace:
- Multi-media transformer fashions,
- Human explainable AI,
- Machine studying fashions for quantum computer systems,
- Neural Radiance Fields (NeRFs),
- Privateness-preserving ML fashions utilizing methods like differential privateness and homomorphic encryption,
- Utilizing artificial knowledge as a part of the mannequin coaching course of, and
- Automating machine studying workflows utilizing self-improving generative fashions.
Moreover, a major quantity of present analysis is devoted to the event of AI “brokers”. AI brokers are primarily multi-step reasoning fashions that may iteratively outline after which clear up complicated issues. Usually, AI brokers may also instantly carry out actions comparable to looking the web, sending an e-mail, or submitting a kind.