

In laptop imaginative and prescient, picture segmentation breaks down a picture into distinct segments or areas for simpler evaluation. This method helps exactly determine objects, boundaries, and contours, making it essential for medical imaging, autonomous automobiles, and satellite tv for pc imagery evaluation.
Healthcare leverages picture segmentation extensively for exactly segmenting medical scans which aids in diagnosing and monitoring ailments.
U-Web, a deep studying mannequin particularly designed for biomedical picture segmentation, exemplifies this. Launched in 2015 by Olaf Ronneberger’s workforce, U-Web aimed to create a high-performing community that might work with restricted coaching knowledge, addressing the problem of scarce annotated photos within the medical discipline.
Challenges in Picture Segmentation
Earlier than the superior deep studying fashions like U-Web and Masks R-CNN, picture segmentation confronted a number of vital challenges.
- Precision and Accuracy: Conventional strategies struggled with precisely segmenting photos, particularly these with various textures, complicated buildings, or noise. Researchers used strategies equivalent to thresholding, region-based segmentation, and edge detection; nevertheless, these strategies didn’t ship the mandatory element and accuracy for complicated functions like medical imaging.
- Dependence on Handcrafted Options: Earlier approaches relied closely on guide function extraction strategies which have been time-consuming and fewer sturdy.
- Scalability and Effectivity: Because of handcrafted function extractors, it was almost not possible to scale the mannequin, as doing so would require one to handcraft all of the options required for the picture variations.
The method of picture segmentation
Deep Studying fashions have solved the constraints mentioned above. A number of deep-learning fashions are used for picture segmentation, equivalent to U-Web, Absolutely Convolutional Networks (FCN), and Masks R-CNN. Nevertheless, all of those fashions roughly observe the next process for picture segmentation.
- Knowledge Preparation: To coach a deep studying mannequin for picture segmentation, you will need to put together a considerable quantity of annotated knowledge. This entails labeling photos on the pixel degree and assigning a category label to every pixel.
- Pre-processing: This step consists of resizing photos, augmenting the dataset with strategies like flipping, rotating, and altering brightness to enhance the mannequin’s robustness, and normalizing the pictures to reinforce studying effectivity.
- Mannequin Coaching: You practice the mannequin on the annotated dataset, enabling it to discover ways to classify every pixel of the enter picture right into a related class.
- Put up-processing: After the mannequin predicts the pixel lessons, you apply post-processing steps equivalent to eradicating small islands of misclassified pixels or utilizing Conditional Random Fields (CRFs) to refine the outcomes.
- Visualization: To visualise the segmentation within the post-processing step, you map every distinctive class worth to a particular colour. This mapping is bigoted and chosen to maximise the distinction between totally different lessons for simpler visible distinction.
Key Improvements in U-Web
As talked about earlier, researchers initially created U-Web for medical picture segmentation, nevertheless it quickly gained reputation throughout numerous different segmentation functions. The widespread adoption is as a result of progressive strategies and strategies utilized in its design.
- Symmetric Increasing Path: In contrast to earlier fashions equivalent to FCN, which had solely contracting paths, U-Web launched a U-shaped structure that consists of an encoding path to seize context and a decoding path that permits exact localization.
- Skip Connections: These join the contracting path with the expansive path, retrieving spatial data misplaced throughout down-sampling.
- Knowledge Augmentation: To sort out the difficulty of restricted coaching knowledge, U-Web employed intensive knowledge augmentation strategies which allowed the mannequin to study extra sturdy options with no need an unlimited variety of annotated samples.
Benefits of U-Web:
- Excessive Accuracy with Restricted Knowledge: U-Web achieves glorious efficiency even with small coaching datasets attributable to its structure and knowledge augmentation methods.
- Exact Localization: The mixture of low-level and high-level options by way of skip connections permits for exact localization of object boundaries.
- Quick and Environment friendly: U-Web’s totally convolutional structure allows environment friendly processing of enormous photos with quick segmentation speeds.
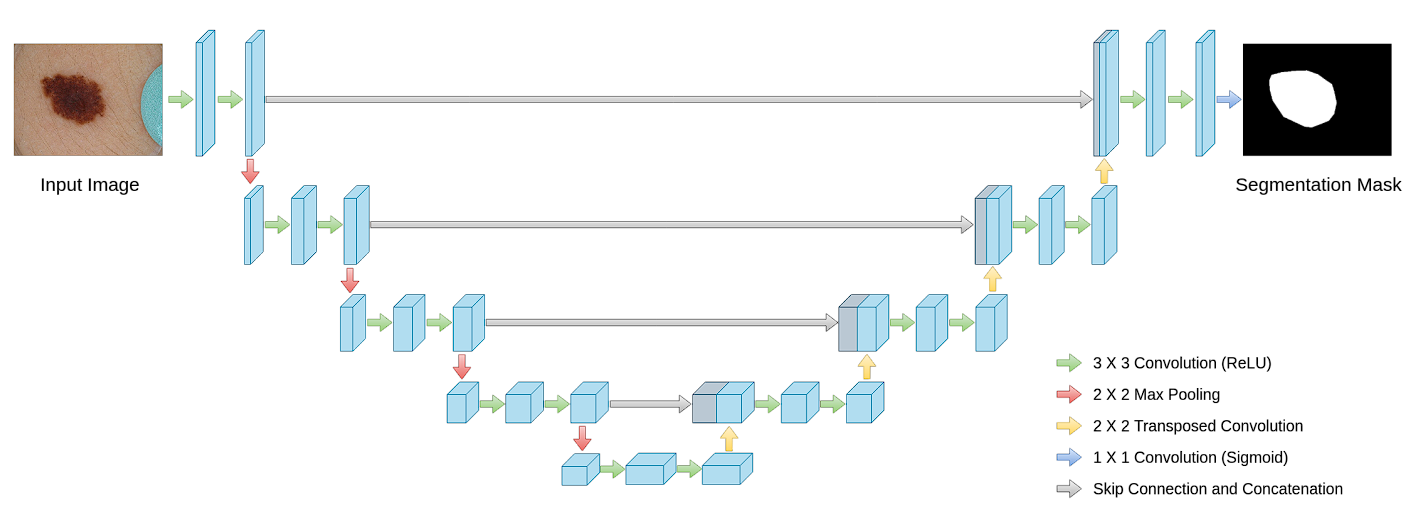
Structure of U-Web
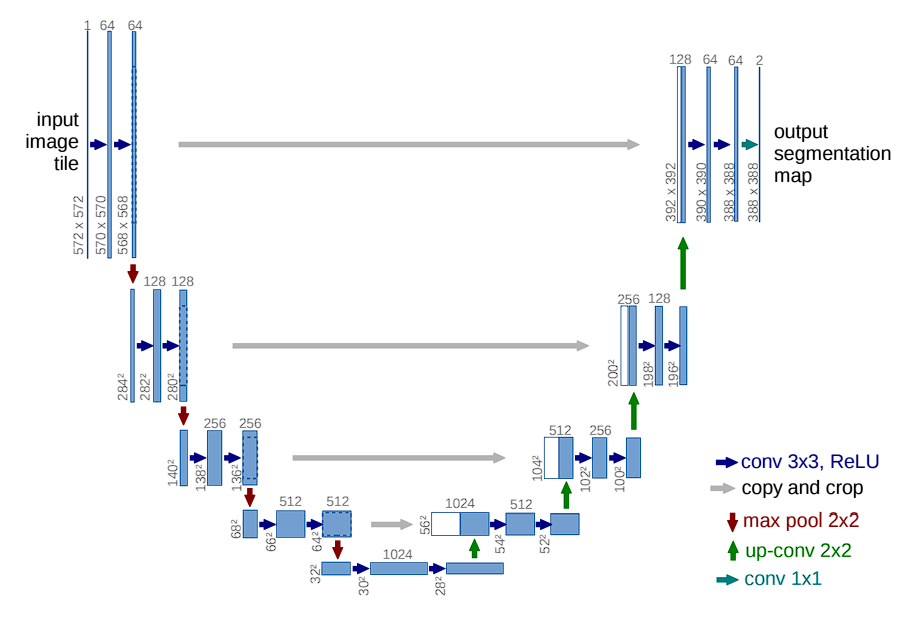
The mannequin contains a distinctive U-shaped construction, comprising two major components: the contracting path (encoder) and the increasing path (decoder). The encoding path captures context, and the decoding path allows exact localization.
Contracting Path (Encoder)
Listed here are the totally different layers and elements in U-Web:
- Convolutional Layers: Convolution Layers are the first elements of the contracting path. Within the initially proposed mannequin, every block consists of two consecutive 3×3 convolutional layers adopted by a Rectified Linear Unit (ReLU) activation operate. By stacking a number of convolutional layers, U-Web learns more and more complicated options.
- Activation Features: After every convolution operation, a ReLU activation operate is utilized. The position of ReLU right here is essential because it introduces non-linearities into the system, which permits for studying extra complicated patterns in knowledge that aren’t doable with simply linear transformations.
- Max Pooling: Following the convolutional layers, a 2×2 max pooling operation with stride 2 is used. This step reduces the spatial dimensions by half. Nevertheless, it captures summary data (that makes the mannequin invariant to small shifts and distortions).
- Characteristic Doubling: After every max pooling step, the next convolutional layer doubles the variety of filters used. For instance, if a layer begins with 64 function channels, it is going to have 128 channels after the following pooling and convolution operations. By doubling the variety of function channels, the community can keep and even enhance its capability to characterize data regardless of the discount in spatial decision. That is essential as a result of the chance of shedding vital particulars will increase because the picture dimension reduces.
Expansive Path (Decoder)
Goals to get better spatial data and generate the segmentation map utilizing up-convolution (or transposed convolution).
Every block consists of:
-
- Up-sampling of the function map to extend picture dimension.
- A 2×2 convolution to halve the variety of function channels.
- Two 3×3 convolutions adopted by ReLU activation.
U-Web additionally makes use of skip connections.
What are skip connections?
Skip connections considerably contribute to U-Web’s effectiveness. By merging function maps from the contracting path immediately with the increasing path, U-Web combines low-level element data with high-level contextual data throughout the community.
Right here is why it’s important.
- Get better Spatial Hierarchies: These connections enable U-Web to concatenate high-resolution options from the contracting path with up-sampled outputs from the increasing path. This helps get better spatial hierarchies misplaced throughout pooling operations within the contracting section.
Output
On the last layer of the Convolutional Neural Community, a 1×1 convolution maps the function vector (usually with 64 elements on the final stage of the expansive path) to the specified variety of lessons for segmentation.
Overlap-Tile Technique
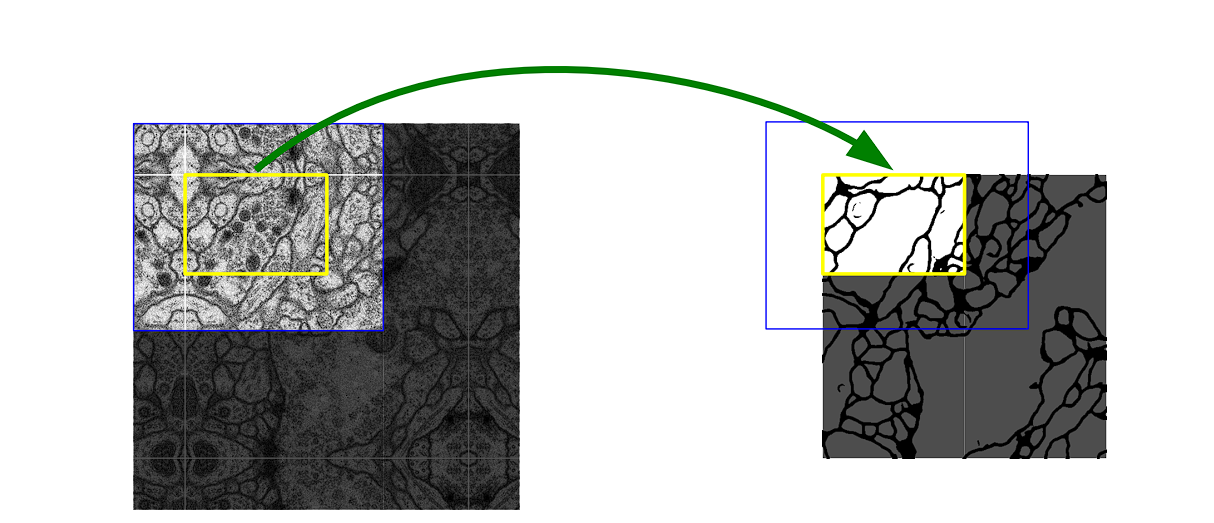
To successfully predict segments in border areas of photos for every pixel’s classification, U-Web employs an overlap-tile technique. This permits U-Web to deal with giant photos by segmenting them into small manageable sections of a picture after which stitching them collectively.
- Tile Processing: As an alternative of processing entire photos (which is computationally intensive), the community divides photos into overlapping tiles that may match into it.
- Overlap Dealing with: The overlaps between tiles assist continuity and stop inaccuracies at tile boundaries.
Knowledge Augmentation
In situations like medical imaging the place annotated samples are restricted, knowledge augmentation assumes a essential position.
Knowledge augmentation is the method of artificially rising the scale of a coaching set utilizing transformations equivalent to rotations, elastic deformations, and scaling. This helps enhance mannequin generalization and robustness by introducing it to several types of photos. Listed here are a number of the variations utilized:
- Biased crop: Randomly crops patches with a bias in direction of together with foreground.
- Zoom: Randomly zooms in on the picture.
- Flipping of Picture
- Gaussian Noise: Provides random noise to the enter.
- Gaussian Blur
- Brightness and Distinction: Randomly adjusts brightness and distinction.
Efficiency Benchmarks
The printed paper of U-Web exhibits distinctive efficiency in medical picture evaluation, with U-Web outperforming all of the earlier strategies on the ISBI EM segmentation problem, reaching state-of-the-art outcomes.
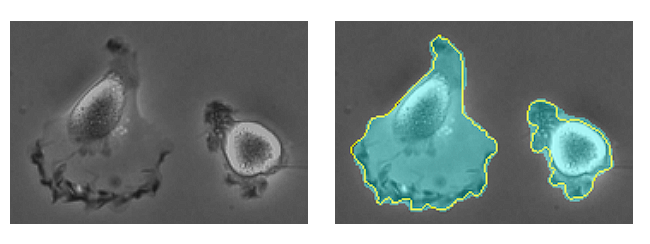
The mannequin was utilized to 2 totally different datasets of sunshine microscopic photos and the next outcomes have been obtained:
- PhC-U373 Dataset: Attaining a median Intersection Over Union (IOU) of 92%, the very best amongst rivals.
- DIC-HeLa Dataset: Attaining a 77.5% IOU, once more outperforming different fashions considerably.
U-Web Variants
For the reason that introduction of U-Web, numerous variations have been developed to sort out particular challenges or improve efficiency. Some notable variants embody:
3D U-Web
Tailored from the unique U-Web for volumetric segmentation, the 3D U-Web extends the structure to a few dimensions by using 3-D convolutions which permits for analyzing 3D medical photos like CT or MRI scans for organ segmentation and tumor identification.
Residual U-Web:
This variant provides residual connections throughout the convolutional blocks of the U-Web structure. The residual connections can assist mitigate the vanishing gradient downside and allow the coaching of deeper networks.
Consideration U-Web
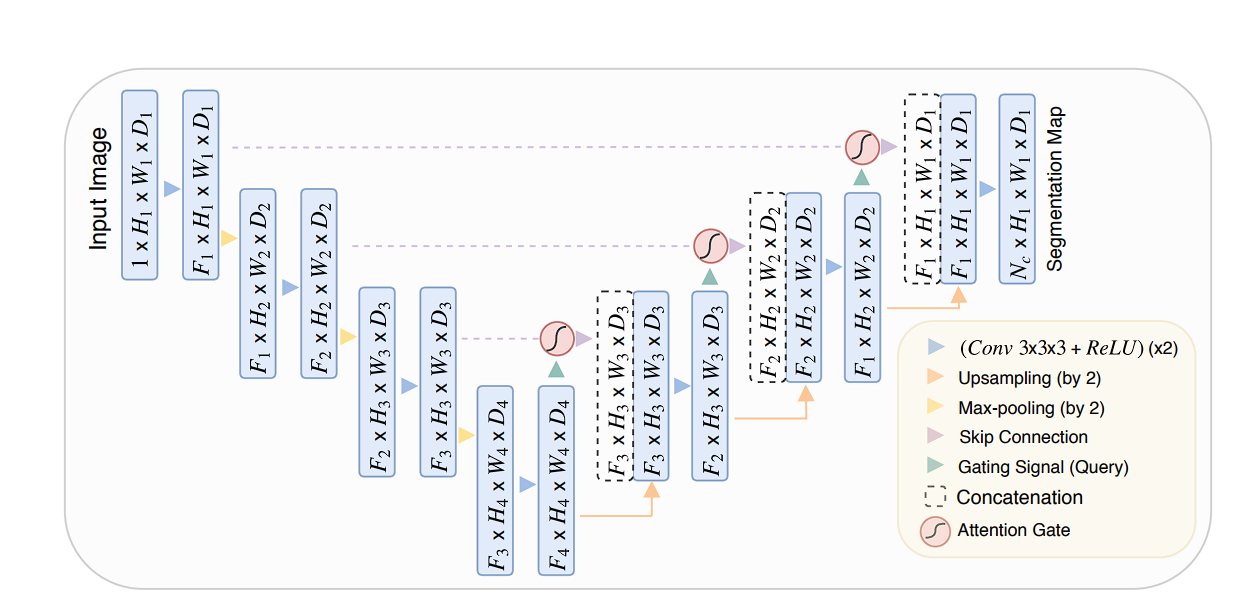
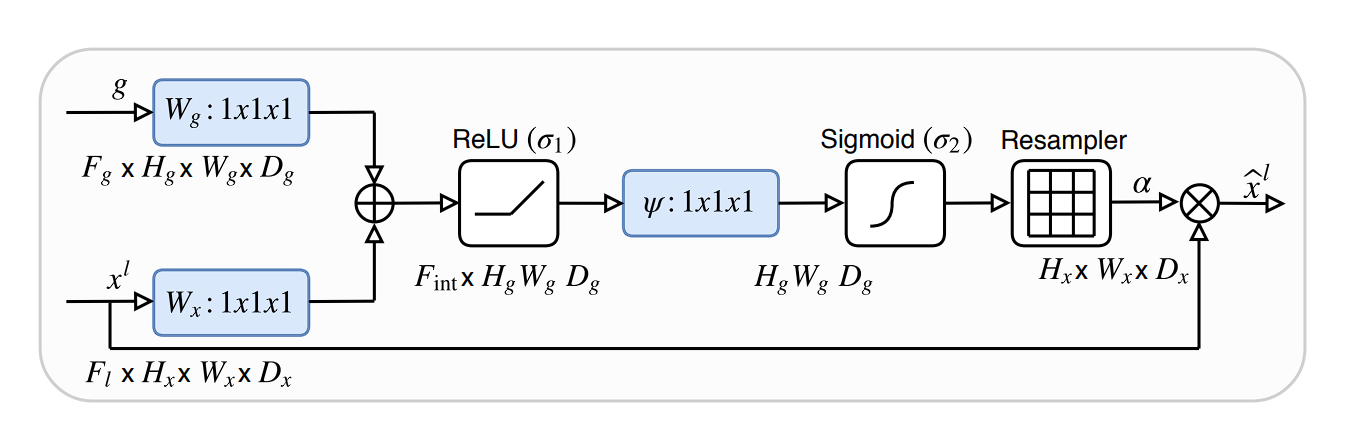
This variant integrates consideration mechanisms into the usual U-Web structure. The Consideration gates study to concentrate on related areas of the encoder function maps by assigning weights based mostly on the context. They enhance the mannequin’s efficiency resulting in extra exact segmentation boundaries.
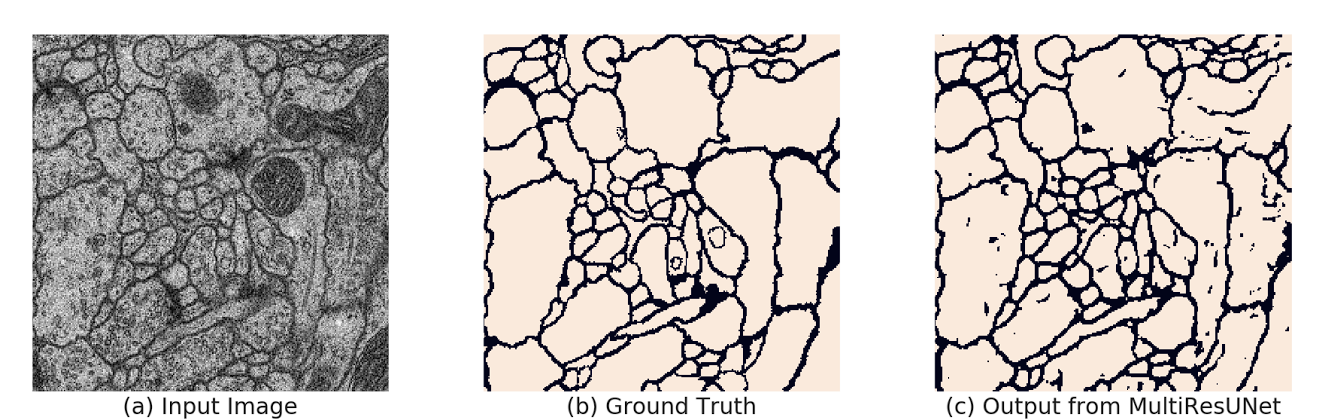
MultiResUNet
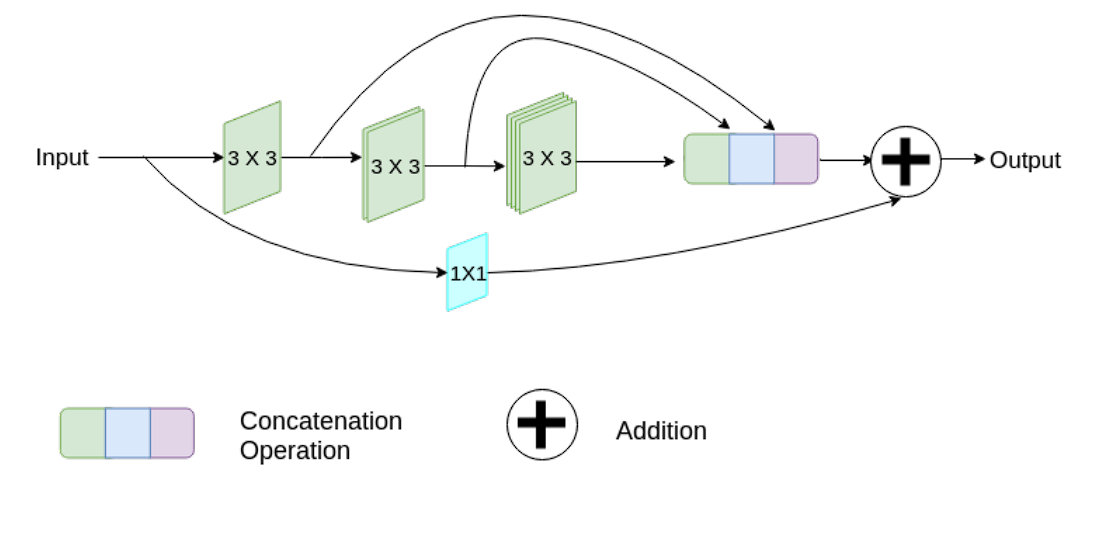
MultiResUNet introduces the idea of Multi-Decision blocks at every stage of the community. These blocks consist ‘of a number of parallel convolutional pathways with various kernel sizes that seize options at totally different resolutions.
Furthermore, it additionally incorporates residual connections, which assist in combating the vanishing gradient downside.
UNETR
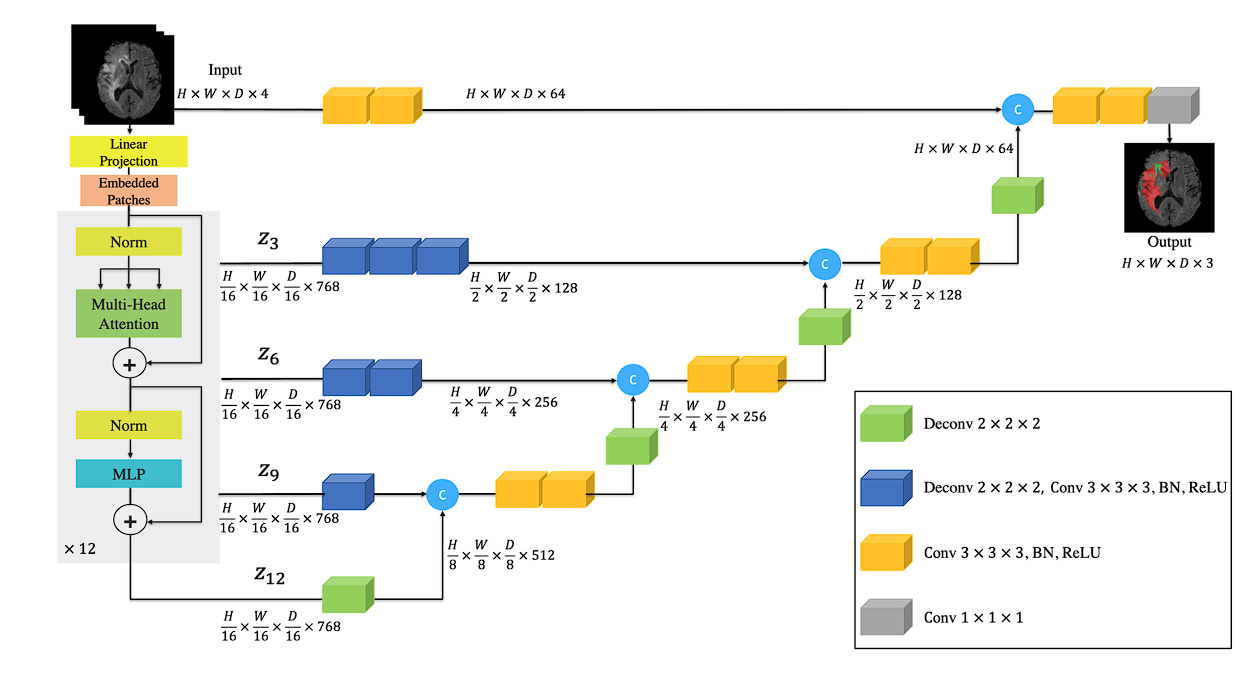
The UNETR mannequin replaces the convolutional encoder of U-Web with a transformer-based encoder that leverages self-attention mechanisms.
The self-attention mechanism permits the mannequin to seize long-range dependencies and international context throughout the enter knowledge, probably enhancing segmentation accuracy.
Functions of U-Web
U-Web’s design, characterised by its effectivity and precision, has made it profoundly impactful throughout numerous domains past its preliminary biomedical functions. Listed here are some key areas the place U-Web has been extensively utilized:
Medical Picture Segmentation
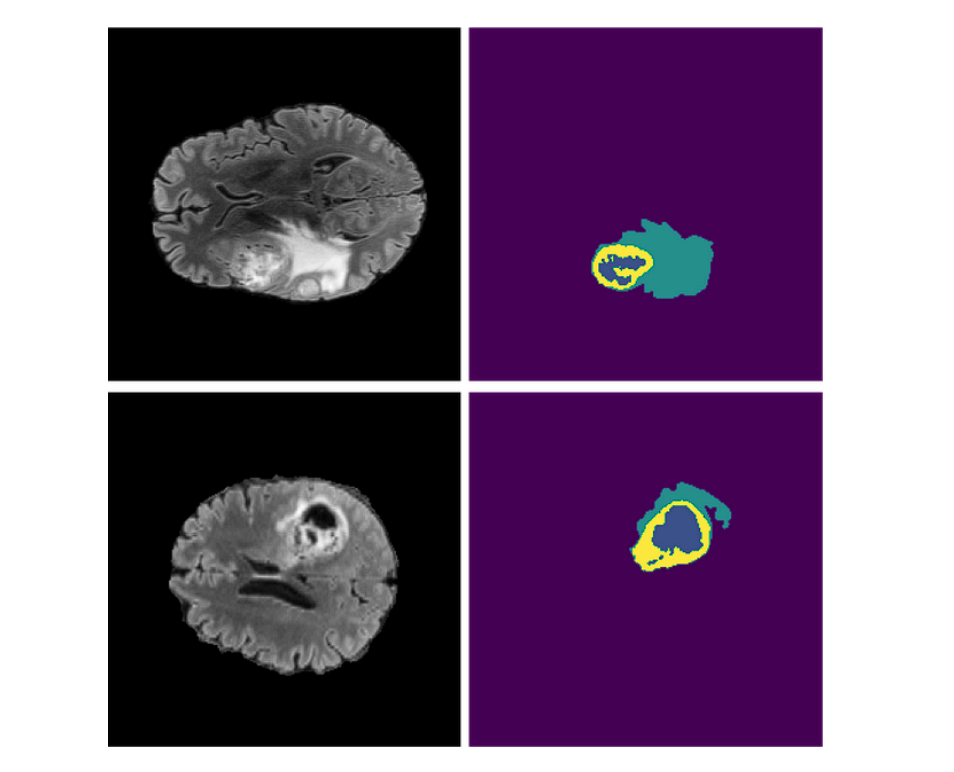
U-Web is particularly standard within the discipline of medical picture segmentation attributable to its potential to supply detailed and correct segmentations of complicated anatomical buildings.
- Organs: U-Web has been utilized to phase numerous organs in several types of medical scans (CT, MRI, Ultrasound). For example, it helps in delineating the boundaries of the liver, coronary heart, lungs, and pancreas which is essential for surgical planning and prognosis.

- Tumors: U-Web is used for exact tumor segmentation on radiological photos, to precisely distinguish tumors from wholesome tissues.
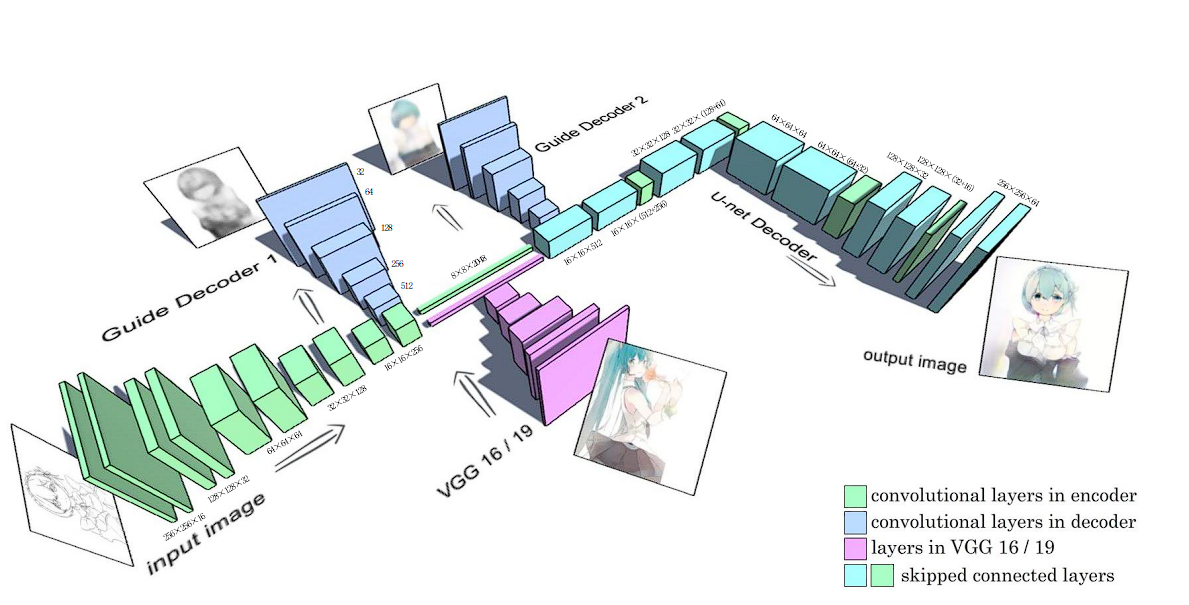
Model Switch
U-Web mixed with GANs has been used for fashion switch for Anime sketches. The generator within the GAN relies on a U-net with skip-connection layers. Learn here.
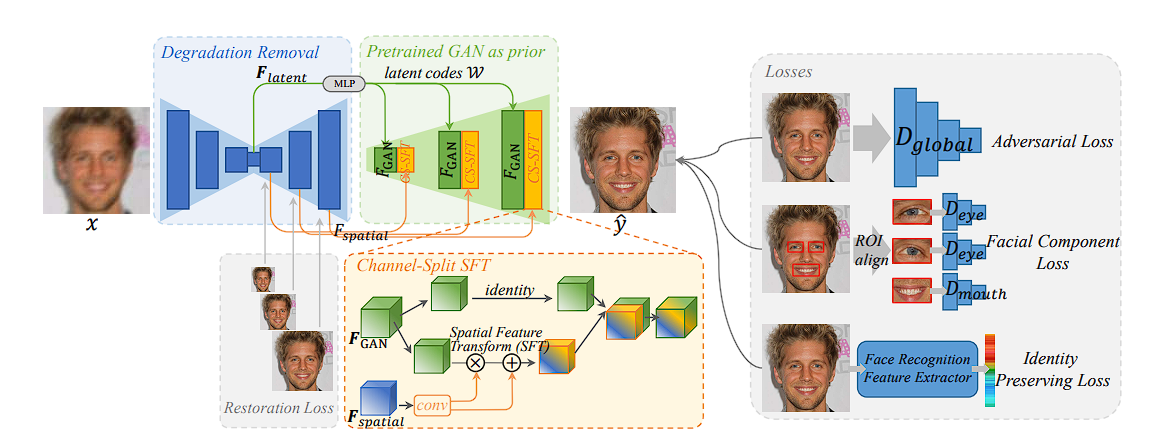
Face Restoration
Implementers have utilized pre-trained face Generative Adversarial Community (GAN) fashions, equivalent to StyleGAN, for blind face restoration. On this implementation, UNet removes degradations equivalent to low-resolution, blur, noise, and JPEG artifacts. Learn here.
Conclusion
On this weblog, we regarded on the U-shaped structure of U-Web, which performs exceptionally nicely in fields like medical imaging the place coaching knowledge is proscribed. Furthermore, the encoder and decoder a part of the mannequin permits for summary illustration and localization of objects, which performs a key position in numerous functions equivalent to tumor detection, face restoration, and so forth. Moreover, we additionally regarded briefly on the variants of the unique U-Web mannequin attributable to which the capabilities of U-Web have been expanded.