
The latest developments within the structure and efficiency of Multimodal Massive Language Fashions or MLLMs has highlighted the importance of scalable information and fashions to reinforce efficiency. Though this strategy does improve the efficiency, it incurs substantial computational prices that limits the practicality and usefulness of such approaches. Through the years, Combination of Professional or MoE fashions have emerged as a profitable alternate strategy to scale image-text and enormous language fashions effectively since Combination of Professional fashions have considerably decrease computational prices, and robust efficiency. Nevertheless, regardless of their benefits, Combination of Fashions should not the best strategy to scale massive language fashions since they typically contain fewer specialists, and restricted modalities, thus limiting the purposes.
To counter the roadblocks encountered by present approaches, and to scale massive language fashions effectively, on this article, we’ll discuss Uni-MoE, a unified multimodal massive language mannequin with a MoE or Combination of Professional structure that’s able to dealing with a big selection of modalities and specialists. The Uni-MoE framework additionally implements a sparse Combination of Professional structure inside the massive language fashions in an try to make the coaching and inference course of extra environment friendly by using expert-level mannequin parallelism and information parallelism. Moreover, to reinforce generalization and multi-expert collaboration, the Uni-MoE framework presents a progressive coaching technique that could be a mixture of three totally different processes. Within the first, the Uni-MoE framework achieves cross-modality alignment utilizing numerous connectors with totally different cross modality information. Second, the Uni-MoE framework prompts the choice of the skilled parts by coaching modality-specific specialists with cross modality instruction information. Lastly, the Uni-MoE mannequin implements the LoRA or Low-Rank Adaptation studying approach on blended multimodal instruction information to tune the mannequin. When the instruction-tuned Uni-MoE framework was evaluated on a complete set of multimodal datasets, the intensive experimental outcomes highlighted the principal benefit of the Uni-MoE framework in decreasing efficiency bias in dealing with blended multimodal datasets considerably. The outcomes additionally indicated a major enchancment in multi-expert collaboration, and generalization.
This text goals to cowl the Uni-MoE framework in depth, and we discover the mechanism, the methodology, the structure of the framework together with its comparability with state-of-the-art frameworks. So let’s get began.
The appearance of open-source multimodal massive language fashions together with LLama and InstantBlip have outlined the notable success and development in duties involving image-text understanding over the previous few years. Moreover, the AI group is working actively in direction of constructing a unified multimodal massive language mannequin that would accommodate a big selection of modalities together with picture, textual content, audio, video, and extra, transferring past the normal image-text paradigm. A standard strategy adopted by the open supply group to spice up the talents of multimodal massive language fashions is to extend the dimensions of imaginative and prescient basis fashions, and integrating it with massive language fashions with billions of parameters, and utilizing numerous multimodal datasets to reinforce instruction tuning. These developments have highlighted the rising capability of multimodal massive language fashions to cause and course of a number of modalities, showcasing the significance of increasing multimodal educational information and mannequin scalability.
Though scaling up a mannequin is a tried and examined strategy that delivers substantial outcomes, scaling a mannequin is a computationally costly course of for each the coaching and inference processes.
To counter the difficulty of excessive overhead computational prices, the open supply group is transferring in direction of integrating the MoE or Combination of Professional mannequin structure in massive language fashions to reinforce each the coaching and inference effectivity. Opposite to multimodal massive language and enormous language fashions that make use of all of the accessible parameters to course of every enter leading to a dense computational strategy, the Combination of Professional structure solely requires the customers to activate a subset of skilled parameters for every enter. Because of this, the Combination of Professional strategy emerges as a viable route to reinforce the effectivity of huge fashions with out intensive parameter activation, and excessive overhead computational prices. Though present works have highlighted the profitable implementation and integration of Combination of Professional fashions within the development of text-only and text-image massive fashions, researchers are but to completely discover the potential of growing the Combination of Professional structure to assemble highly effective unified multimodal massive language fashions.
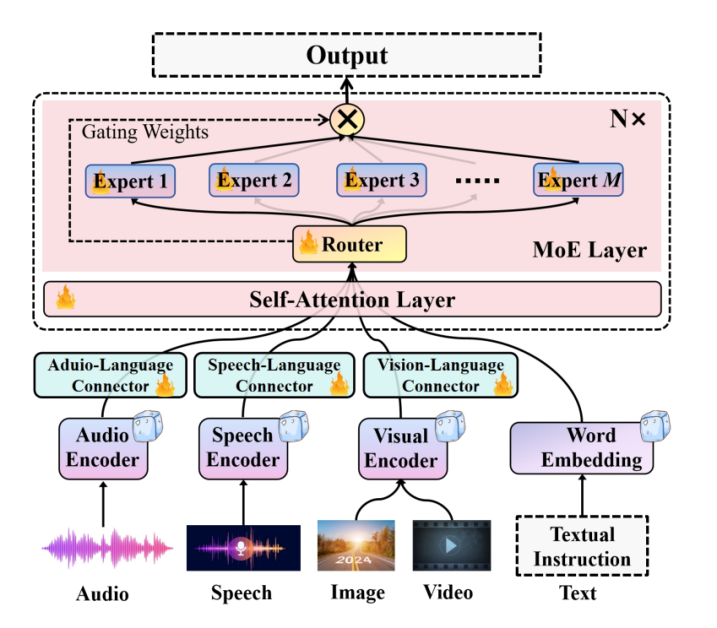
Uni-MoE is a multimodal massive language mannequin that leverages sparse Combination of Professional fashions to interpret and handle a number of modalities in an try to discover scaling unified multimodal massive language fashions with the MoE structure. As demonstrated within the following picture, the Uni-MoE framework first obtains the encoding of various modalities utilizing modality-specific encoders, after which maps these encodings into the language illustration house of the massive language fashions utilizing numerous designed connectors. These connectors include a trainable transformer mannequin with subsequent linear projections to distill and mission the output representations of the frozen encoder. The Uni-MoE framework then introduces a sparse Combination of Professional layers inside the inner block of the dense Massive Language Mannequin. Because of this, every Combination of Professional based mostly block incorporates a shared self-attention layer relevant throughout all modalities, a sparse router for allocating experience at token degree, and numerous specialists based mostly on the feedforward community. Owing to this strategy, the Uni-MoE framework is able to understanding a number of modalities together with speech, audio, textual content, video, picture, and solely requires activating partial parameters throughout inference.

Moreover, to reinforce multi-expert collaboration and generalization, the Uni-MoE framework implements a three-stage coaching technique. Within the first stage, the framework makes use of intensive picture/audio/speech to language pairs to coach the corresponding connector owing to the unified modality illustration within the language house of the massive language mannequin. Second, the Uni-MoE mannequin trains modality-specific specialists using cross-modality datasets individually in an try to refine the proficiency of every skilled inside its respective area. Within the third stage, the Uni-MoE framework integrates these educated specialists into the Combination of Professional layer of the massive language mannequin, and trains your complete Uni-MoE framework with blended multimodal instruction information. To scale back the coaching value additional, the Uni-MoE framework employs the LoRA studying strategy to fine-tune these self-attention layers and the pre-tuned specialists.
Uni-MoE : Methodology and Structure
The essential motivation behind the Uni-MoE framework is the excessive coaching and inference value of scaling multimodal massive language fashions together with the effectivity of Combination of Professional fashions, and discover the potential of creating an environment friendly, highly effective, and unified multimodal massive language mannequin using the MoE structure. The next determine presents a illustration of the structure carried out within the Uni-MoE framework demonstrating the design that features particular person encoders for various modalities i.e. audio, speech and visuals together with their respective modality connectors.

The Uni-MoE framework then integrates the Combination of Professional structure with the core massive language mannequin blocks, a course of essential for reinforcing the general effectivity of each the coaching and inference course of. The Uni-MoE framework achieves this by implementing a sparse routing mechanism. The general coaching means of the Uni-MoE framework will be cut up into three phases: cross-modality alignment, coaching modality-specific specialists, and tuning Uni-MoE utilizing a various set of multimodal instruction datasets. To effectively rework numerous modal inputs right into a linguistic format, the Uni-MoE framework is constructed on prime of LLaVA, a pre-trained visible language framework. The LLaVA base mannequin integrates CLIP as its visible encoder alongside a linear projection layer that converts picture options into their corresponding smooth picture tokens. Moreover, to course of video content material, the Uni-MoE framework selects eight consultant frames from every video, and transforms them into video tokens by common pooling to combination their picture or frame-based illustration. For audio duties, the Uni-MoE framework deploys two encoders, BEATs and the Whisper encoder to reinforce characteristic extraction. The mannequin then distills audio options vector and fixed-length speech, and maps them into speech tokens and smooth audio respectively through a linear projection layer.
Coaching Technique
The Uni-MoE framework introduces a progressive coaching technique for the incremental improvement of the mannequin. The progressive coaching technique launched makes an attempt to harness the distinct capabilities of assorted specialists, improve multi-expert collaboration effectivity, and enhance the general generalizability of the framework. The coaching course of is cut up into three phases with the try to actualize the MLLM construction constructed on prime of built-in Combination of Consultants.
Stage 1 : Cross Modality Alignment
Within the first stage, the Uni-MoE framework makes an attempt to ascertain connectivity between totally different linguistics and modalities. The Uni-MoE framework achieves this by translating modal information into smooth tokens by setting up connectors. The first object of the primary coaching stage is to attenuate the generative entropy loss. Throughout the Uni-MoE framework, the LLM is optimized to generate descriptions for inputs throughout totally different modalities, and the mannequin solely topics the connectors to coaching, a technique that allows the Uni-MoE framework to combine totally different modalities inside a unified language framework.

Stage 2: Coaching Modality Particular Consultants
Within the second stage, the Uni-MoE framework focuses on growing single modality specialists by coaching the mannequin dedicatedly on particular cross modality information. The first goal is to refine the proficiency of every skilled inside its respective area, thus enhancing the general efficiency of the Combination of Professional system on a big selection of multimodal information. Moreover, the Uni-MoE framework tailors the feedforward networks to align extra intently with the traits of the modality whereas sustaining generative entropy loss as focal metric coaching.

Stage 3: Tuning Uni-MoE
Within the third and the ultimate stage, the Uni-MoE framework integrates the weights tuned by specialists throughout Stage 2 into the Combination of Professional layers. The Uni-MoE framework then fine-tunes the MLLMs using blended multimodal instruction information collectively. The loss curves within the following picture replicate the progress of the coaching course of.

Comparative evaluation between the configurations of Combination of Professional revealed that the specialists the mannequin refined throughout the 2nd coaching stage displayed enhanced stability and achieved faster convergence on mixed-modal datasets. Moreover, on duties that concerned advanced multi-modal information together with textual content, photos, audio, movies, the Uni-MoE framework demonstrated extra constant coaching efficiency and lowered loss variability when it employed 4 specialists than when it employed two specialists.

Uni-MoE : Experiments and Outcomes
The next desk summarizes the architectural specs of the Uni-MoE framework. The first purpose of the Uni-MoE framework, constructed on LLaMA-7B structure, is to scale the mannequin measurement.

The next desk summarizes the design and optimization of the Uni-MoE framework as guided by specialised coaching duties. These duties are instrumental in refining the capabilities of the MLP layers, thereby leveraging their specialised data for enhanced mannequin efficiency. The Uni-MoE framework undertakes eight single-modality skilled duties to elucidate the differential impacts of assorted coaching methodologies.

The mannequin evaluates the efficiency of assorted mannequin variants throughout a various set of benchmarks that encompasses two video-understanding, three audio-understanding, and 5 speech-related duties. First, the mannequin is examined on its capability to grasp speech-image and speech-text duties, and the outcomes are contained within the following desk.

As it may be noticed, the earlier baseline fashions ship inferior outcomes throughout speech understanding duties which additional impacts the efficiency on image-speech reasoning duties. The outcomes point out that introducing Combination of Professional structure can improve the generalizability of MLLMs on unseen audi-image reasoning duties. The next desk presents the experimental outcomes on image-text understanding duties. As it may be noticed, one of the best outcomes from the Uni-MoE fashions outperforms the baselines, and surpasses the fine-tuning process by a mean margin of 4 factors.

Remaining Ideas
On this article now we have talked about Uni-MoE, , a unified multimodal massive language mannequin with a MoE or Combination of Professional structure that’s able to dealing with a big selection of modalities and specialists. The Uni-MoE framework additionally implements a sparse Combination of Professional structure inside the massive language fashions in an try to make the coaching and inference course of extra environment friendly by using expert-level mannequin parallelism and information parallelism. Moreover, to reinforce generalization and multi-expert collaboration, the Uni-MoE framework presents a progressive coaching technique that could be a mixture of three totally different processes. Within the first, the Uni-MoE framework achieves cross-modality alignment utilizing numerous connectors with totally different cross modality information. Second, the Uni-MoE framework prompts the choice of the skilled parts by coaching modality-specific specialists with cross modality instruction information. Lastly, the Uni-MoE mannequin implements the LoRA or Low-Rank Adaptation studying approach on blended multimodal instruction information to tune the mannequin.

