
Machine studying is a key area of Synthetic Intelligence that creates algorithms and coaching fashions. Two necessary issues that machine studying tries to take care of are Regression and Classification. Many machine Studying algorithms carry out these two duties. Nonetheless, algorithms like Linear regression make assumptions in regards to the dataset. These algorithms could not work correctly if the dataset fails to fulfill the assumptions. The Resolution Tree algorithm is impartial of such assumptions and works advantageous for each regression and classification duties.
On this article, we are going to focus on the Resolution Tree algorithm, and the way it works. We may also see find out how to implement a choice tree in Python, and its functions in several domains. By the top of this text, you should have a complete understanding of the choice bushes algorithm.
About us: Viso Suite is the pc imaginative and prescient infrastructure permitting enterprises to handle the complete software lifecycle. With Viso Suite, it’s attainable for ML groups supply knowledge, practice fashions, and deploy them wherever, leading to simply 3 days of time-to-value. Study extra with a demo of Viso Suite.
What’s a Resolution Tree?
Resolution Tree is a tree-based algorithm. Each classification and regression duties use this algorithm. It really works by creating bushes to make choices based mostly on the chances at every step. That is referred to as recursive partitioning.
It is a non-parametric and supervised studying algorithm. It doesn’t make assumptions in regards to the dataset and requires a labeled dataset for coaching. It has the construction as proven beneath:
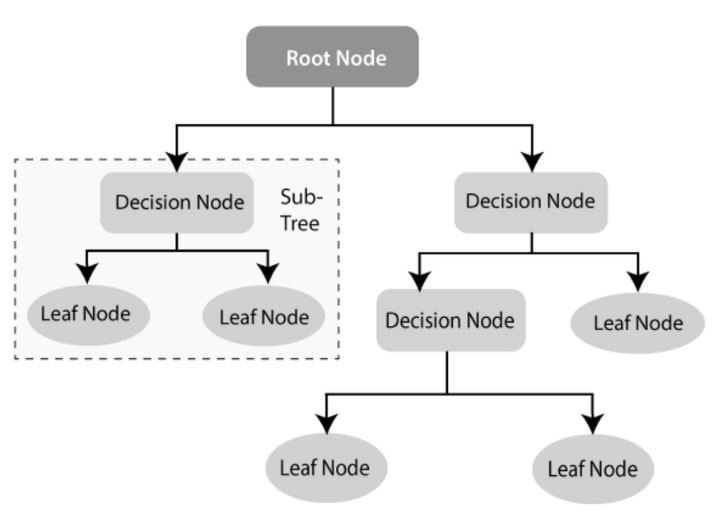
As we are able to see within the above tree diagram construction, the Resolution tree algorithm has a number of nodes. They’re categorized as beneath.
- Root Node: The choice tree algorithm begins with the Root Node. This node represents the whole dataset and offers rise to all different nodes within the algorithm.
- Resolution Node/Inner Node: These nodes are based mostly on the enter options of the dataset and are additional break up into different inner nodes. Generally, these will also be referred to as mum or dad nodes in the event that they break up and provides rise to additional inner nodes that are referred to as baby nodes.
- Leaf Node/Terminal Node: This node is the top prediction or the category label of the choice tree. This node doesn’t break up additional and stops the tree execution. The Leaf node represents the goal variable.
How Does a Resolution Tree Work?
Think about a binary classification downside of predicting if a given buyer is eligible for the mortgage or not. Let’s say the dataset has the next attributes:
| Attribute | Description |
|---|---|
| Job | Occupation of the Applicant |
| Age | Age of Applicant |
| Revenue | Month-to-month Revenue of the Applicant |
| Training | Training Qualification of the Applicant |
| Marital Standing | Marital Standing of the Applicant |
| Current Mortgage | Whether or not the Applicant has an present EMI or not |
Right here, the goal variable determines whether or not the client is eligible for the mortgage or not. The algorithm begins with the complete dataset because the Root Node. It splits the info recursively on options that give the very best data achieve.
This node of the tree offers rise to baby nodes. Bushes signify a choice.
This course of continues till the standards for stopping is happy, which is determined by the max depth. Constructing a choice tree is a straightforward course of. The beneath picture illustrates the splitting course of on the attribute ‘Age’.
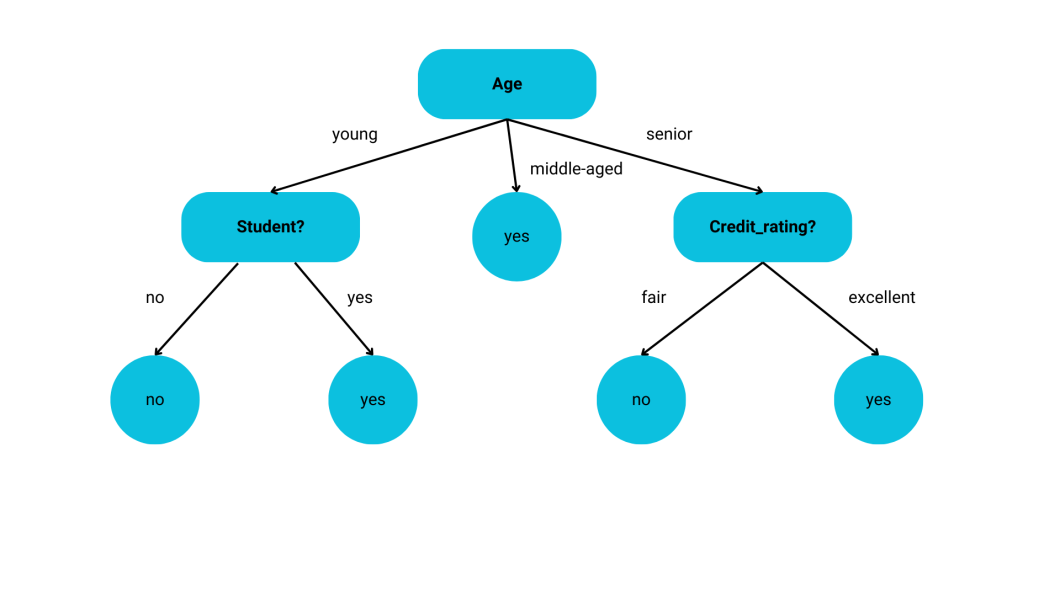
Completely different values of the ‘Age’ attribute are analyzed and the tree is break up accordingly. Nonetheless, the standards for splitting the nodes have to be decided. The algorithm doesn’t perceive what every attribute means.
Therefore it wants a worth to find out the standards for splitting the node.
Splitting Standards for Resolution Tree
Resolution tree fashions are based mostly on tree buildings. So, we want some standards to separate the nodes and create new nodes in order that the mannequin can higher determine the helpful options.
Data Acquire
- Data achieve is the measure of the discount within the Entropy at every node.
- Entropy is the measure of randomness or purity on the node.
- The formulation of Data Acquire is, Acquire(S,A) = Entropy(S) -∑n(i=1)(|Si|/|S|)*Entropy(Si)
- {S1,…, Si,…,Sn} = partition of S in accordance with worth of attribute A
- n = variety of attribute A
- |Si| = variety of instances within the partition Si
- |S| = whole variety of instances in S
- The formulation of Entropy is, Entropy=−∑i1=cpilogpi
- A node splits if it has the very best data achieve.
Gini Index
- The Gini index is the measure of the impurity within the dataset.
- It makes use of the likelihood distribution of the goal variables for calculations.
- The formulation for the Gini Index is, Gini(S)=1−∑pi2
- Classification and regression resolution tree fashions use this criterion for splitting the nodes.
Discount in Variance
- Variance Discount measures the lower in variance of the goal variable.
- Regression duties primarily use this criterion.
- When the Variance is minimal, the node splits.
Chi-Squared Automated Interplay Detection (CHAID)
- This algorithm makes use of the Chi-Sq. take a look at.
- It splits the node based mostly on the response between the dependent variable and the impartial variables.
- Categorical variables similar to gender and shade use these standards for splitting.
A choice tree mannequin builds the bushes utilizing the above splitting standards. Nonetheless, one necessary downside that each mannequin in machine studying is inclined to is over-fitting. Therefore, the Resolution Tree mannequin can also be liable to over-fitting. Generally, there are numerous methods to keep away from this. Essentially the most generally used approach is Pruning.
What’s Pruning?
Bushes that don’t assist the issue we try to unravel often start to develop. These bushes could carry out nicely on the coaching dataset. Nonetheless, they could fail to generalize past the take a look at dataset. This ends in over-fitting.
Pruning is a method for stopping the event of pointless bushes. It prevents the tree from rising to its most depth. Pruning, in fundamental phrases, permits the mannequin to generalize efficiently on the take a look at dataset, reducing overfitting.
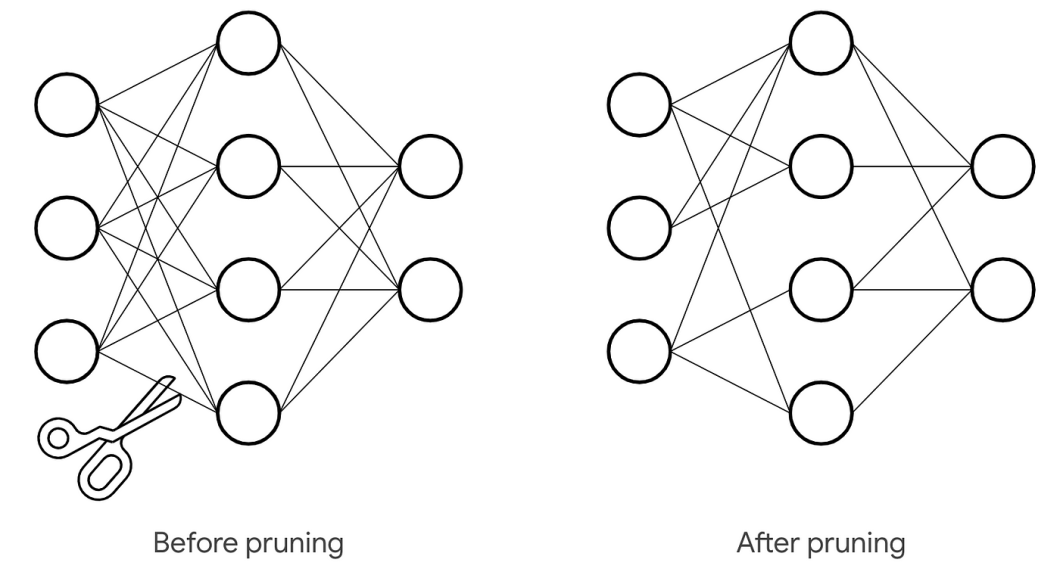
However how can we prune a choice tree? There are two pruning strategies.
Pre-Pruning
This system includes stopping the expansion of the choice tree at early levels. The tree doesn’t attain its full depth. So, the bushes that don’t contribute to the mannequin don’t develop. That is also referred to as ‘Early Stopping’.
The expansion of the tree stops when the cross-validation error doesn’t lower. This course of is quick and environment friendly. We cease the tree at its early levels by utilizing the parameters, ‘min_samples_split‘, ‘min_samples_leaf‘, and ‘max_depth‘. These are the hyper-parameters in a choice tree algorithm.
Put up-Pruning
Put up-pruning permits the tree to develop to its full depth after which cuts down the pointless branches to forestall over-fitting. Data achieve or Gini Impurity determines the standards to take away the tree department. ‘ccp_alpha‘ is the hyper-parameter used on this course of.
Price Complexity Pruning (ccp) controls the scale of the tree. The variety of nodes will increase with the rise in ‘ccp_alpha‘.
These are among the strategies to scale back over-fitting within the resolution tree mannequin.
Python Resolution Tree Classifier
We’ll use the 20 newsgroups dataset within the scikit-learn’s dataset module. This dataset is a classification dataset.
Step One: Import all the mandatory modules
from sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.textual content import CountVectorizer from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
Step Two: Load the dataset
# Load the 20 Newsgroups dataset newsgroups = fetch_20newsgroups(subset="all") X, y = newsgroups.knowledge, newsgroups.goal
Step Three: Vectorize the textual content knowledge
# Convert textual content knowledge to numerical options vectorizer = CountVectorizer() X_vectorized = vectorizer.fit_transform(X)
Step 4: Cut up the info
# Cut up the dataset into coaching and testing units X_train, X_test, y_train, y_test = train_test_split(X_vectorized, y, test_size=0.2, random_state=42)
Step 5: Create a classifier and practice
# Create and practice the choice tree classifier clf = DecisionTreeClassifier(random_state=42) clf.match(X_train, y_train)
Step Six: Make correct predictions on take a look at knowledge
# Make predictions on take a look at knowledge y_pred = clf.predict(X_test)
Step Seven: Consider the mannequin utilizing the Accuracy rating
# Consider the mannequin on the take a look at set
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
The above code would produce a mannequin that has an ‘accuracy_score’ of 0.65. We will enhance the mannequin with hyper-parameter tuning and extra pre-processing steps.
Python Resolution Tree Regressor
To construct a regression mannequin utilizing resolution bushes, we are going to use the diabetes dataset out there within the Scikit Study’s dataset module. We’ll use the ‘mean_squared_error‘ for analysis.
Step One: Import all the mandatory modules
from sklearn.datasets import load_diabetes from sklearn.tree import DecisionTreeRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error
Step Two: Load the dataset
# Load the Diabetes dataset diabetes = load_diabetes() X, y = diabetes.knowledge, diabetes.goal
This dataset doesn’t have any textual content knowledge and has solely numeric knowledge. So, there is no such thing as a have to vectorize something. We’ll break up the info for coaching the mannequin.
Step Three: Cut up the dataset
# Cut up the dataset into coaching and testing units X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 4: Create a Regressor and practice
# Create and practice the choice tree regressor reg = DecisionTreeRegressor(random_state=42) reg.match(X_train, y_train)
Step 5: Make correct predictions on take a look at knowledge
# Make predictions on take a look at knowledge y_pred = reg.predict(X_test)
Step 5: Consider the mannequin
# Consider the mannequin on the take a look at set
mse = mean_squared_error(y_test, y_pred)
print(f"Imply Squared Error: {mse:.2f}")
The regressor will give a imply squared error of 4976.80. That is fairly excessive. We will optimize the mannequin additional by utilizing hyper-parameter tuning and extra pre-processing steps.
Actual Life Makes use of Instances With Resolution Bushes
The Resolution Tree algorithm is tree-based and can be utilized for each classification and regression tree functions. A Resolution tree is a flowchart-like decision-making course of which makes it a straightforward algorithm to grasp. Because of this, it’s utilized in a number of domains for classification and regression functions. It’s utilized in domains similar to:
Healthcare
Since resolution bushes are tree-based algorithms, they can be utilized to find out a illness and its early analysis by analyzing the signs and take a look at ends in the healthcare sector. They will also be used for remedy planning, and optimizing medical processes. For instance, we are able to evaluate the negative effects and, the price of completely different remedy plans to make knowledgeable choices about affected person care.
Banking Sector
Resolution bushes can be utilized to construct a classifier for numerous monetary use instances. We will detect fraudulent transactions, and mortgage eligibility of shoppers utilizing a choice tree classifier. We will additionally consider the success of recent banking merchandise utilizing the tree-based resolution construction.

Threat Evaluation
Resolution Bushes are used to detect and manage potential dangers, one thing beneficial within the insurance coverage world. This permits analysts to contemplate numerous situations and their implications. It may be utilized in venture administration, and strategic planning to optimize choices and save prices.
Knowledge Mining
Resolution bushes are used for regression and classification duties. They’re additionally used for function choice to determine vital variables and eradicate irrelevant options. They’re additionally used to deal with lacking values and mannequin non-linear relationships between numerous variables.
Machine Studying as a subject has advanced in several methods. If you’re planning to be taught machine studying, then beginning your studying with a choice tree is a good suggestion as it’s easy and straightforward to interpret. Resolution Bushes may be utilized with different algorithms utilizing ensembling, stacking, and staging which may enhance the efficiency of the mannequin.
What’s Subsequent?
To be taught extra in regards to the aspects of pc imaginative and prescient AI, try the next articles: