
Understanding the Origins: The Limitations of LSTM
Earlier than we dive into the world of xLSTM, it is important to grasp the constraints that conventional LSTM architectures have confronted. These limitations have been the driving drive behind the event of xLSTM and different various approaches.
- Lack of ability to Revise Storage Selections: One of many main limitations of LSTM is its wrestle to revise saved values when a extra comparable vector is encountered. This may result in suboptimal efficiency in duties that require dynamic updates to saved info.
- Restricted Storage Capacities: LSTMs compress info into scalar cell states, which might restrict their means to successfully retailer and retrieve advanced knowledge patterns, significantly when coping with uncommon tokens or long-range dependencies.
- Lack of Parallelizability: The reminiscence mixing mechanism in LSTMs, which includes hidden-hidden connections between time steps, enforces sequential processing, hindering the parallelization of computations and limiting scalability.
These limitations have paved the way in which for the emergence of Transformers and different architectures which have surpassed LSTMs in sure points, significantly when scaling to bigger fashions.
The xLSTM Structure

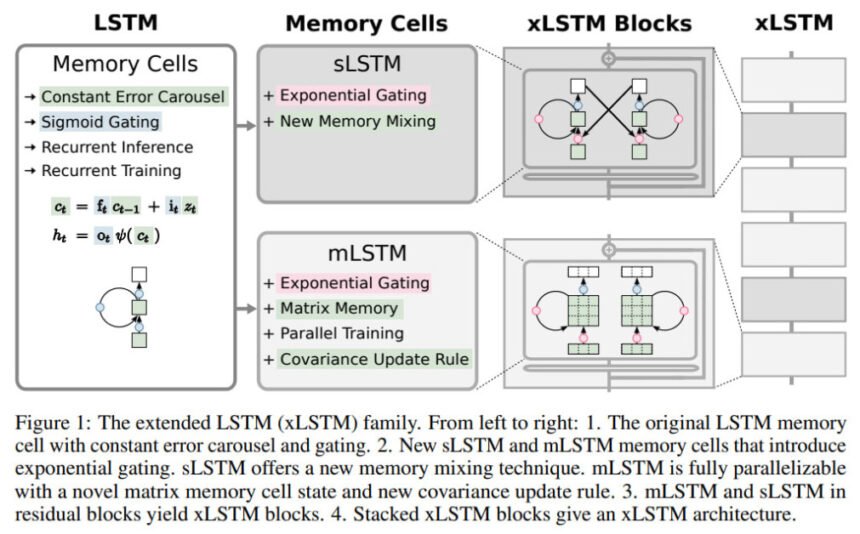
Prolonged LSTM (xLSTM) household
On the core of xLSTM lies two most important modifications to the normal LSTM framework: exponential gating and novel reminiscence constructions. These enhancements introduce two new variants of LSTM, often known as sLSTM (scalar LSTM) and mLSTM (matrix LSTM).
- sLSTM: The Scalar LSTM with Exponential Gating and Reminiscence Mixing
- Exponential Gating: sLSTM incorporates exponential activation features for enter and overlook gates, enabling extra versatile management over info move.
- Normalization and Stabilization: To stop numerical instabilities, sLSTM introduces a normalizer state that retains observe of the product of enter gates and future overlook gates.
- Reminiscence Mixing: sLSTM helps a number of reminiscence cells and permits for reminiscence mixing through recurrent connections, enabling the extraction of advanced patterns and state monitoring capabilities.
- mLSTM: The Matrix LSTM with Enhanced Storage Capacities
- Matrix Reminiscence: As a substitute of a scalar reminiscence cell, mLSTM makes use of a matrix reminiscence, growing its storage capability and enabling extra environment friendly retrieval of data.
- Covariance Replace Rule: mLSTM employs a covariance replace rule, impressed by Bidirectional Associative Reminiscences (BAMs), to retailer and retrieve key-value pairs effectively.
- Parallelizability: By abandoning reminiscence mixing, mLSTM achieves full parallelizability, enabling environment friendly computations on trendy {hardware} accelerators.
These two variants, sLSTM and mLSTM, may be built-in into residual block architectures, forming xLSTM blocks. By residually stacking these xLSTM blocks, researchers can assemble highly effective xLSTM architectures tailor-made for particular duties and utility domains.
The Math
Conventional LSTM:
The unique LSTM structure launched the fixed error carousel and gating mechanisms to beat the vanishing gradient downside in recurrent neural networks.

The repeating module in an LSTM – Source
The LSTM reminiscence cell updates are ruled by the next equations:
Cell State Replace: ct = ft ⊙ ct-1 + it ⊙ zt
Hidden State Replace: ht = ot ⊙ tanh(ct)
The place:
- 𝑐𝑡 is the cell state vector at time 𝑡
- 𝑓𝑡 is the overlook gate vector
- 𝑖𝑡 is the enter gate vector
- 𝑜𝑡 is the output gate vector
- 𝑧𝑡 is the enter modulated by the enter gate
- ⊙ represents element-wise multiplication
The gates ft, it, and ot management what info will get saved, forgotten, and outputted from the cell state ct, mitigating the vanishing gradient situation.
xLSTM with Exponential Gating:

The xLSTM structure introduces exponential gating to permit extra versatile management over the knowledge move. For the scalar xLSTM (sLSTM) variant:
Cell State Replace: ct = ft ⊙ ct-1 + it ⊙ zt
Normalizer State Replace: nt = ft ⊙ nt-1 + it
Hidden State Replace: ht = ot ⊙ (ct / nt)
Enter & Overlook Gates: it = exp(W_i xt + R_i ht-1 + b_i) ft = σ(W_f xt + R_f ht-1 + b_f) OR ft = exp(W_f xt + R_f ht-1 + b_f)
The exponential activation features for the enter (it) and overlook (ft) gates, together with the normalizer state nt, allow simpler management over reminiscence updates and revising saved info.
Key Options and Benefits of xLSTM
- Capability to Revise Storage Selections: Due to exponential gating, xLSTM can successfully revise saved values when encountering extra related info, overcoming a major limitation of conventional LSTMs.
- Enhanced Storage Capacities: The matrix reminiscence in mLSTM gives elevated storage capability, enabling xLSTM to deal with uncommon tokens, long-range dependencies, and sophisticated knowledge patterns extra successfully.
- Parallelizability: The mLSTM variant of xLSTM is totally parallelizable, permitting for environment friendly computations on trendy {hardware} accelerators, akin to GPUs, and enabling scalability to bigger fashions.
- Reminiscence Mixing and State Monitoring: The sLSTM variant of xLSTM retains the reminiscence mixing capabilities of conventional LSTMs, enabling state monitoring and making xLSTM extra expressive than Transformers and State Area Fashions for sure duties.
- Scalability: By leveraging the newest strategies from trendy Giant Language Fashions (LLMs), xLSTM may be scaled to billions of parameters, unlocking new prospects in language modeling and sequence processing duties.
Experimental Analysis: Showcasing xLSTM’s Capabilities

The analysis paper presents a complete experimental analysis of xLSTM, highlighting its efficiency throughout numerous duties and benchmarks. Listed below are some key findings:
- Artificial Duties and Lengthy Vary Enviornment:
- xLSTM excels at fixing formal language duties that require state monitoring, outperforming Transformers, State Area Fashions, and different RNN architectures.
- Within the Multi-Question Associative Recall process, xLSTM demonstrates enhanced reminiscence capacities, surpassing non-Transformer fashions and rivaling the efficiency of Transformers.
- On the Lengthy Vary Enviornment benchmark, xLSTM reveals constant sturdy efficiency, showcasing its effectivity in dealing with long-context issues.
- Language Modeling and Downstream Duties:
- When educated on 15B tokens from the SlimPajama dataset, xLSTM outperforms current strategies, together with Transformers, State Area Fashions, and different RNN variants, by way of validation perplexity.
- Because the fashions are scaled to bigger sizes, xLSTM continues to keep up its efficiency benefit, demonstrating favorable scaling conduct.
- In downstream duties akin to frequent sense reasoning and query answering, xLSTM emerges as the perfect technique throughout numerous mannequin sizes, surpassing state-of-the-art approaches.
- Efficiency on PALOMA Language Duties:
- Evaluated on 571 textual content domains from the PALOMA language benchmark, xLSTM[1:0] (the sLSTM variant) achieves decrease perplexities than different strategies in 99.5% of the domains in comparison with Mamba, 85.1% in comparison with Llama, and 99.8% in comparison with RWKV-4.
- Scaling Legal guidelines and Size Extrapolation:
- When educated on 300B tokens from SlimPajama, xLSTM reveals favorable scaling legal guidelines, indicating its potential for additional efficiency enhancements as mannequin sizes enhance.
- In sequence size extrapolation experiments, xLSTM fashions preserve low perplexities even for contexts considerably longer than these seen throughout coaching, outperforming different strategies.
These experimental outcomes spotlight the outstanding capabilities of xLSTM, positioning it as a promising contender for language modeling duties, sequence processing, and a variety of different functions.
Actual-World Functions and Future Instructions
The potential functions of xLSTM span a variety of domains, from pure language processing and technology to sequence modeling, time collection evaluation, and past. Listed below are some thrilling areas the place xLSTM might make a major impression:
- Language Modeling and Textual content Era: With its enhanced storage capacities and skill to revise saved info, xLSTM might revolutionize language modeling and textual content technology duties, enabling extra coherent, context-aware, and fluent textual content technology.
- Machine Translation: The state monitoring capabilities of xLSTM might show invaluable in machine translation duties, the place sustaining contextual info and understanding long-range dependencies is essential for correct translations.
- Speech Recognition and Era: The parallelizability and scalability of xLSTM make it well-suited for speech recognition and technology functions, the place environment friendly processing of lengthy sequences is important.
- Time Sequence Evaluation and Forecasting: xLSTM’s means to deal with long-range dependencies and successfully retailer and retrieve advanced patterns might result in important enhancements in time collection evaluation and forecasting duties throughout numerous domains, akin to finance, climate prediction, and industrial functions.
- Reinforcement Studying and Management Methods: The potential of xLSTM in reinforcement studying and management methods is promising, as its enhanced reminiscence capabilities and state monitoring skills might allow extra clever decision-making and management in advanced environments.


