

YOLOv10 is the newest development within the YOLO (You Solely Look As soon as) household of object detection fashions, recognized for real-time object detection. The YOLOv10 mannequin pushes the performance-efficiency boundaries, constructing on the success of its predecessors. The brand new thrilling enhancements promise to rework real-time object detection throughout varied purposes.
Researchers have carried out in depth experiments on the YOLO fashions, attaining notable progress. Nonetheless, YOLOv10 goals to advance earlier variations’ post-processing and mannequin structure. The result’s a brand new technology of the YOLO collection for real-time end-to-end object detection.
Prepare for a deep dive into YOLOv10. We’ll look at the architectural modifications, evaluate its effectivity with different YOLO fashions, uncover its sensible makes use of, and reveal learn how to apply it for inference and coaching in your knowledge.
About us: Viso Suite offers laptop imaginative and prescient infrastructure for enterprises. As the one end-to-end answer, Viso Suite consolidates your entire software pipeline into a sturdy interface. Study extra about how firms worldwide are utilizing Viso Suite for on a regular basis enterprise options.
YOLOv10: An Evolution of Object Detection
The YOLO collection has been predominant through the years within the discipline of real-time object detection. Every YOLO mannequin is available in a number of sizes with a unique stability of accuracy and pace. Under are the standard sizes for a YOLO mannequin, together with the newest YOLOv10.
- YOLO-N (Nano)
- YOLO-S (Small)
- YOLO-M (Medium)
- YOLO-B (Balanced)
- YOLO-L (Giant)
- YOLO-X (X-Giant)
Object detection, particularly in real-time has at all times been an necessary space of analysis in laptop imaginative and prescient. The aim of object detection in real-time is to find and determine objects in a picture underneath low latency. Researchers usually make use of variations of a Convolution Neural Community (CNN) like R-CNN (Regional CNN), Quick R-CNN, Quicker R-CNN, and Masks R-CNN.
Nonetheless, YOLO fashions make the most of a extra advanced structure than that, providing a stability between efficiency and effectivity for real-time object detection. Let’s recap these fundamentals earlier than diving into the specifics of YOLOv10.
Background
The earliest object detection methodology was the sliding window method the place a fixed-size bounding field strikes throughout the picture till we discover the article of curiosity. As that is resource-intensive, researchers developed extra environment friendly approaches, similar to Quicker R-CNN, one of many earliest approaches shifting towards real-time object detection.
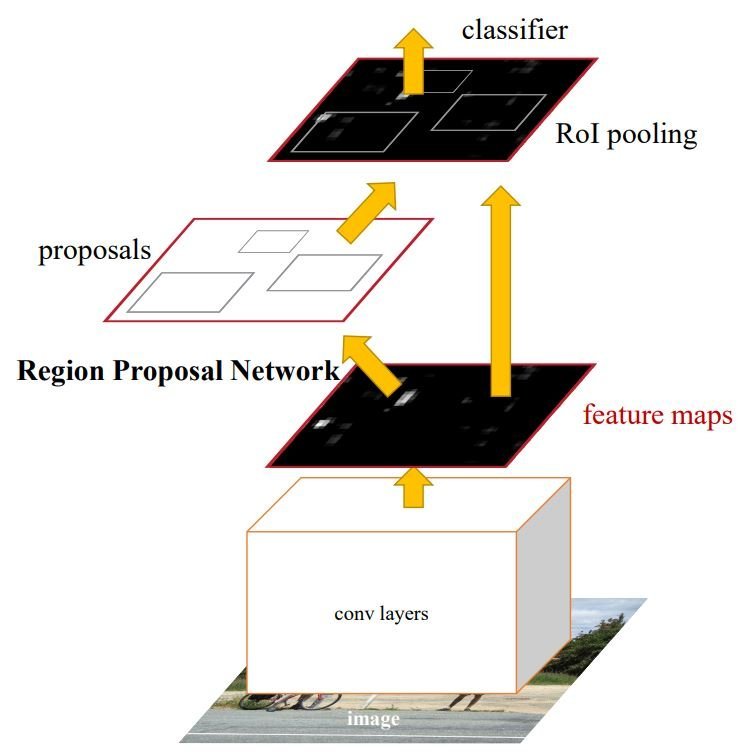
The thought behind Quicker R-CNN is to make use of R-CNN which goals to optimize the sliding window method with a area proposal community. This algorithm would suggest bounding packing containers the place the article is extra prone to be. Then Convolutional layers extract function maps which are used to categorise the objects inside the bounding packing containers. Moreover, Quicker R-CNN consists of optimization to extend pace and effectivity.
Nonetheless, the YOLO fashions include a unique method in thoughts. These fashions make the most of a single-shot methodology, the place each detection and classification occur in a single step. YOLO fashions, together with YOLOv10, body object detection as a regression downside, the place a single neural community predicts the bounding packing containers and the lessons in a single analysis.

The YOLO detection system works in a pipeline of a single community, thus it’s optimized for detection efficiency.
- The pipeline first resizes the picture to the enter dimension of the YOLO mannequin.
- Runs a Convolutional Neural Community on the picture.
- The pipeline then makes use of Non-max suppression (NMS) to optimize the CNN’s detections by making use of confidence thresholding.
Non-maximum suppression (NMS) is a method utilized in object detection to take away duplicate bounding packing containers and choose solely the related ones. By tuning this postprocessing approach and different methods like optimization, knowledge augmentation, and architectural adjustments, researchers create totally different variations of YOLO fashions. As we’ll see later, the YOLOv10’s most notable evolution is expounded to the NMS approach.
Benchmarks
To know the developments in YOLOv10, we are going to begin by evaluating its benchmark outcomes to these of earlier YOLO variations. The 2 principal efficiency measures used with real-time object-detection fashions are often common precision (AP) or mAP (imply AP), and latency. We measure these metrics on benchmark datasets just like the COCO dataset.
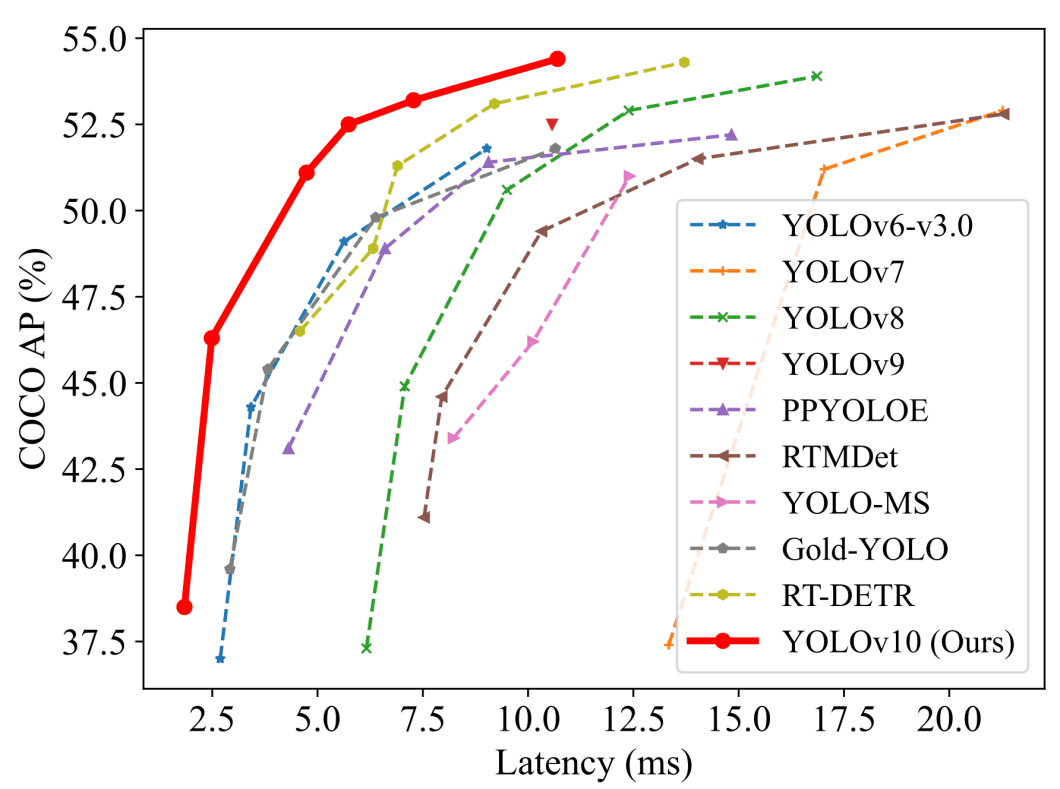
Whereas this comparability reveals solely metrics like latency and AP, we will see how the YOLOv10 mannequin considerably improves these measures. We have to have a look at a extra detailed comparability to grasp the total image. This comparability will present different metrics to examine the areas the place YOLOv10 excels.
| Mannequin | Params (M) | FLOPs (G) | APval (%) | Latency (ms) | Latency (Ahead) (ms) |
|---|---|---|---|---|---|
| YOLOv6-3.0-S | 18.5 | 45.3 | 44.3 | 3.42 | 2.35 |
| YOLOv8-S | 11.2 | 28.6 | 44.9 | 7.07 | 2.33 |
| YOLOv9-S | 7.1 | 26.4 | 46.7 | – | – |
| YOLOv10-S | 7.2 | 21.6 | 46.3 / 46.8 | 2.49 | 2.39 |
| YOLOv6-3.0-M | 34.9 | 85.8 | 49.1 | 5.63 | 4.56 |
| YOLOv8-M | 25.9 | 78.9 | 50.6 | 9.50 | 5.09 |
| YOLOv9-M | 20.0 | 76.3 | 51.1 | – | – |
| YOLOv10-M | 15.4 | 59.1 | 51.1/51.3 | 4.74 | 4.63 |
| YOLOv8-L | 43.7 | 165.2 | 52.9 | 12.39 | 8.06 |
| YOLOv10-L | 24.4 | 120.3 | 53.2 / 53.4 | 7.28 | 7.21 |
| YOLOv8-X | 68.2 | 257.8 | 53.9 | 16.86 | 12.83 |
| YOLOv10-X | 29.5 | 160.4 | 54.4 | 10.70 | 10.60 |
As proven within the desk, we will see how the YOLOv10 achieves state-of-the-art efficiency throughout varied scales. YOLOv10 in comparison with baseline fashions just like the YOLOv8 has a spread of enhancements. The S/ M/ L/ X sizes obtain 1.4%/0.5%/0.3%/0.5% AP enchancment with 36%/41%/44%/57% fewer parameters and 65%/ 50%/ 41%/ 37% decrease latencies. Importantly, YOLOv10 achieves superior trade-offs between accuracy and computational value.
These enhancements in opposition to different YOLO variations just like the YOLOv9, YOLOv8, and YOLOv6, point out the effectiveness of the YOLOv10’s architectural design. Subsequent, let’s examine and discover the architectural design of YOLOv10.
The Structure Of YOLOv10
The structure design in YOLO fashions is a elementary problem due to its impact on accuracy and pace. Researchers explored totally different design methods for YOLO fashions, however the detection pipeline of most YOLO fashions stays the identical. There are two components to the pipeline.
- Ahead course of
- NMS postprocessing
Moreover, YOLO structure design often consists of three principal elements.
- Spine: Used for function extraction making a illustration of the picture.
- Neck: This element, launched in YOLOv4, is the bridge between the spine and the pinnacle. It combines options throughout totally different scales from the extracted options.
- Head: That is the place the classification occurs, it predicts the bounding packing containers and the lessons of the objects.
With that in thoughts, we are going to have a look at the important thing enhancements and architectural design of the YOLOv10.
Key Enhancements
Since YOLOs body object detection as a regression downside, the mannequin divides the picture right into a grid of cells.
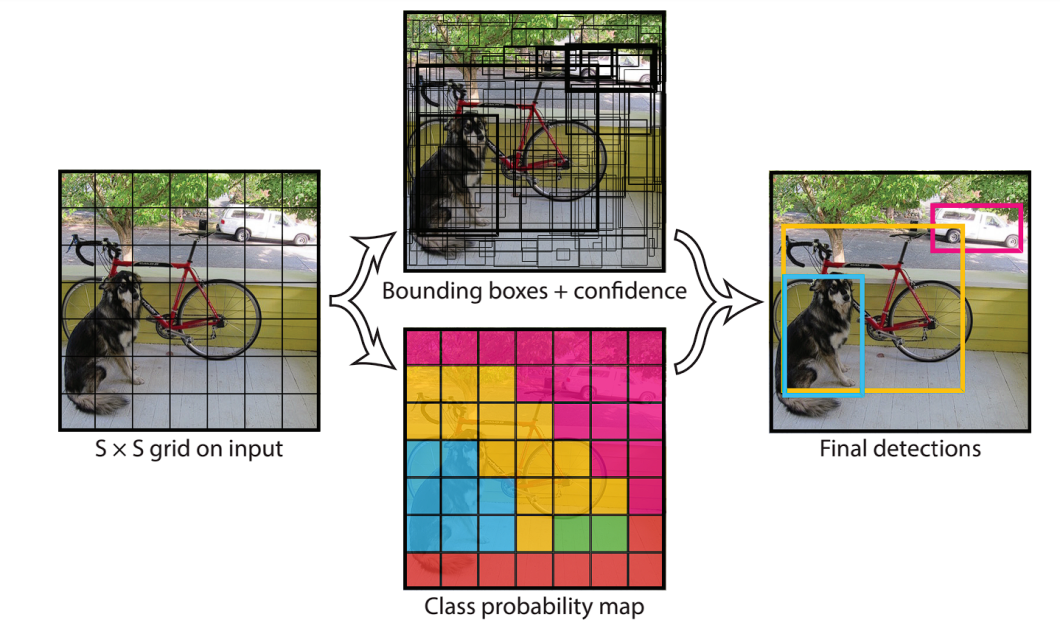
Every cell is liable for predicting a number of bounding packing containers. In YOLOs, every ground-truth object (the precise object within the coaching picture) is related to a number of predicted bounding packing containers.
This one-to-many label task technique has proven sturdy efficiency however requires Non-Most Suppression (NMS) throughout inference. NMS depends on Intersection over Union (IoU), a metric to calculate the overlap between the expected bounding field and the bottom fact. By setting an IoU threshold, NMS can filter out redundant packing containers.
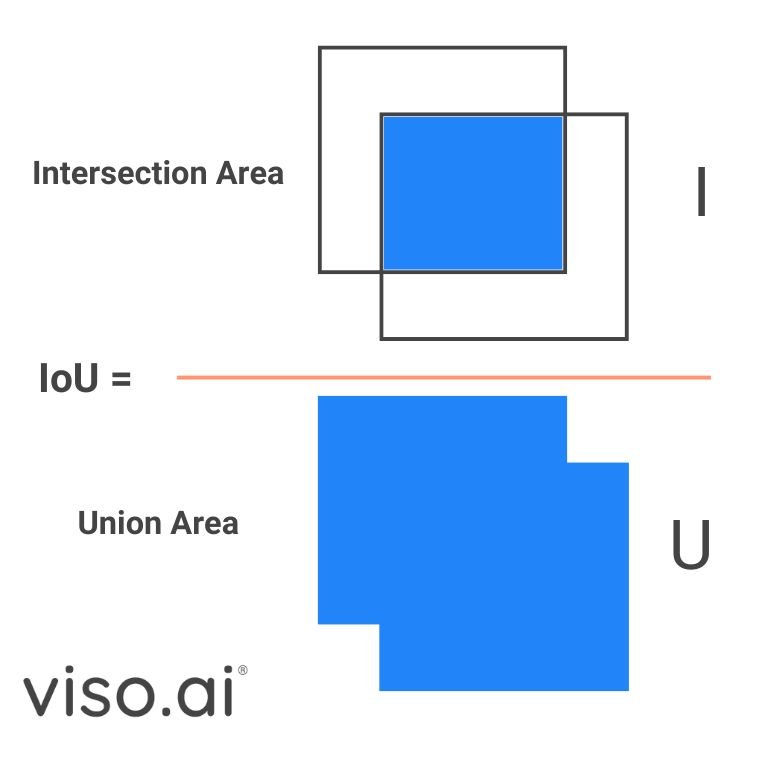
Nonetheless, this post-processing step slows down the inference pace, stopping YOLOs from reaching their optimum efficiency. The YOLOv10 eliminates the NMS postprocessing step with NMS-Free coaching. The researchers make the most of a constant twin assignments coaching methodology that effectively reduces the latency.
Constant twin task permits the mannequin to make a number of predictions on an object, with a confidence rating for every. Throughout inference, we will choose the bounding field with the best IOU or confidence, lowering inference time with out sacrificing accuracy.
Moreover, YOLOv10 consists of enhancements within the optimization and structure of the mannequin.
- Holistic Design: This refers back to the optimization completed to numerous elements of the mannequin, the holistic method maximizes the effectivity and accuracy of every. We’ll delve deeper into the specifics of this design later.
- Improved Structure and Capabilities: This consists of adjustments to the convolutional layers, and including partial self-attention modules to boost effectivity with out risking computational value.
Subsequent, we are going to have a look at the elements of the YOLOv10 mannequin, exploring the enhancements.
Parts
YOLOv10 elements construct upon the success of earlier YOLO variations, retaining a lot of their construction whereas introducing key improvements. Throughout coaching, YOLOs often use a one-to-many task technique which wants NMS postprocessing. Different earlier works have explored issues like one-to-one matching which assigns just one prediction to every object, thus eliminating NMS, however this launched extra inference overhead.
The YOLOv10 introduces the dual-label task and constant matching metric. This combines the most effective of the one-to-one and the one-to-many label assignments and achieves excessive efficiency and effectivity.
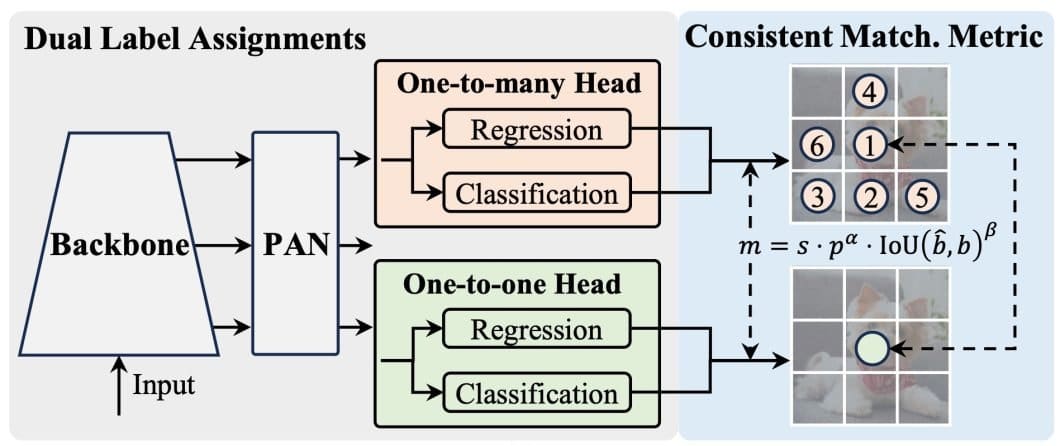
As proven within the determine above, the YOLOv10 provides a further one-to-one head to the structure of YOLOs. This head retains the identical construction and optimization as the unique one-to-many head.
- Whereas coaching the mannequin, each heads are collectively optimized giving the spine and the neck wealthy supervision.
- The wealthy supervision comes from the flexibility of the one-to-many task technique to permit the mannequin to contemplate a number of potential bounding packing containers for every floor fact object. This offers the spine and neck fashions extra data to study from.
- The constant matching metric optimizes the one-to-one head supervision to the course of the one-to-many head. A metric measures the IOU settlement between each heads and aligns their predictions.
- Throughout inference, the one-to-many head is discarded and we use the one-to-one head to make predictions. YOLOv10 additionally adopts the top-one choice methodology, in the end giving it much less coaching time and no extra inference prices.
The spine and neck are additionally necessary elements in any YOLO mode. Particularly, in YOLOv10 the researchers employed an enhanced model of CSPNet to do function extraction. In addition they used PAN layers to mix options from totally different scales inside the neck.
Holistic Design-Effectivity-Pushed
The YOLOv10 goals to optimize the elements from effectivity and accuracy views. Beginning with the efficiency-driven mannequin design, the YOLOv10 applies optimization to the downsampling layers, the essential constructing block levels, and the pinnacle.
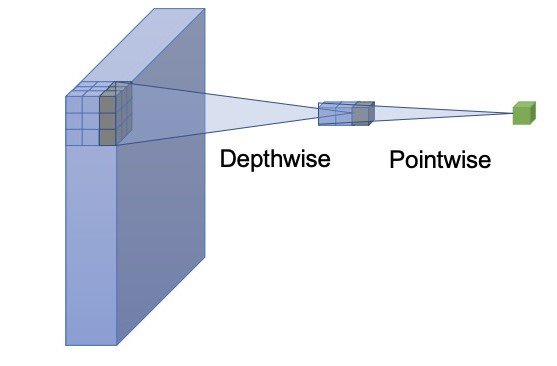
The primary optimization is the light-weight classification head utilizing depth-wise separable convolution. YOLOs often use a regression and a classification element. A light-weight classification head will scale back inference time and never drastically damage efficiency. Depth-wise separable convolution consists of a depthwise and a pointwise community, the one adopted in YOLOv10 has a kernel dimension of three×3 adopted by a 1×1 convolution.
The second optimization is the spatial-channel decoupled downsampling. YOLOs usually use common 3×3 normal convolutions with a stride of two. As an alternative, the YOLOv10 makes use of the pointwise convolution to regulate the channel dimensions and the depthwise for spatial downsampling. This method separates the 2 operations resulting in diminished computational value and parameter rely.
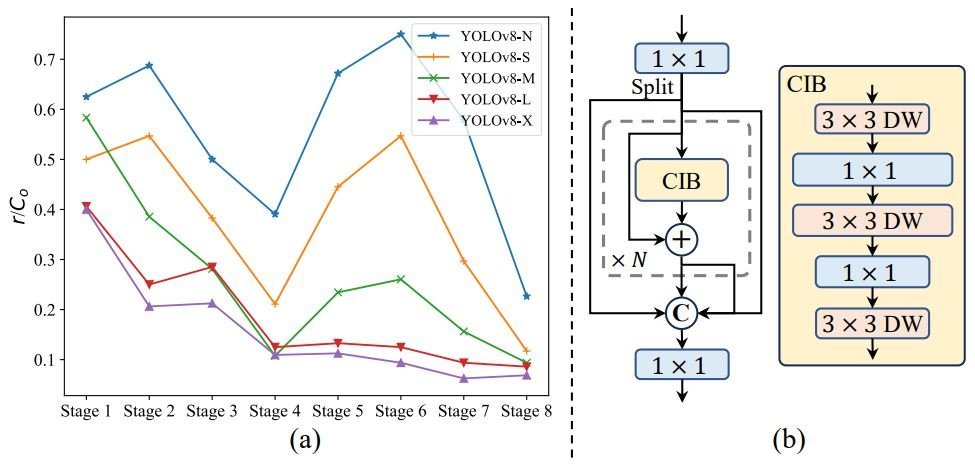
Moreover, the YOLOv10 makes use of a 3rd optimization for effectivity, the rank-guided block design. YOLOs often use the identical primary constructing blocks for all levels. Thus, the researchers behind YOLOv10 introduce an intrinsic rank metric to research the redundancy of mannequin levels.
The analyses present that deep levels and huge fashions are susceptible to extra redundancy, half (a) of the determine above. This causes inefficiency and suboptimal efficiency.
To deal with this, they introduce the rank-guided block design:
- Compact inverted block (CIB): Makes use of cost-effective depthwise convolutions for spatial mixing and pointwise convolutions for channel mixing, half (b) of the determine above.
- Rank-guided block allocation: Kind all levels of a mannequin primarily based on their intrinsic ranks in ascending order. Moreover, they change redundant blocks with CIBs in levels the place it doesn’t have an effect on efficiency.
Holistic Design-Accuracy-Pushed
Effectivity and accuracy are the most important trade-offs in object detection, however the YOLOv10 holistic method minimizes this trade-off. The researchers discover large-kernel convolution and self-attention for the accuracy-driven design, boosting efficiency with minimal prices.
The primary accuracy-driven optimization is the large-kernel convolution. Utilizing giant kernel convolutions can improve the mannequin’s receptive discipline enhancing object detection. Nonetheless, utilizing these convolutions in all levels could cause issues detecting small objects or be inefficient in high-resolution levels.
Subsequently, the YOLOv10 introduces utilizing large-kernel depthwise convolutions in compact inverted block (CIB), solely within the deeper levels and with small mannequin scales. Particularly, the researchers improve the kernel dimension from 3×3 to 7×7 within the second depthwise convolution of the CIB.
Moreover, they use the structural reparameterization approach by introducing a further 3×3 depthwise convolution department which mitigates potential optimization points and retains the advantages of smaller kernels.
This optimization enhances the mannequin’s capacity to seize positive particulars and contextual data with out sacrificing effectivity or value throughout inference.
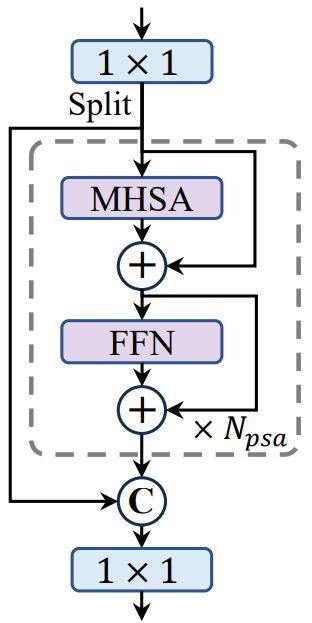
Lastly, the YOLOv10 employs a further accuracy-driven optimization, the partial self-attention (PSA). Self-attention is extensively utilized in visible duties for its highly effective international modeling capabilities however comes with excessive computational prices. To deal with this, the researchers of YOLOv10 introduce an environment friendly design for the partial self-attention module.
Particularly, they evenly divide the options throughout channels into two components and solely apply self-attention (NPSA blocks) to at least one half. Moreover, they optimize the eye mechanism by lowering the size of question and key and changing LayerNorm with BatchNorm for quicker inference. This reduces value and retains the worldwide modeling advantages.
Moreover, PSA is simply utilized after the stage with the bottom decision to regulate the computational overhead, resulting in improved mannequin efficiency.
Implementation And Functions Of YOLOv10
The accuracy and efficiency-driven design is an evolutionary step for the YOLO household. This complete inspection of elements resulted in YOLOv10, a brand new technology of real-time, end-to-end object detection fashions.
Whereas real-time object detection has existed since Quicker R-CNN, minimizing latency has at all times been a key aim. The latency of a mannequin is a vital consider figuring out its sensible purposes. Excessive-integrity purposes have to have optimum performances in effectivity and accuracy, and that’s what YOLOv10 offers us.
We’ll discover the YOLOv10 code, after which have a look at the way it can evolve real-world purposes.
YOLOv10 Inference-HuggingFace
Most YOLOs are simply applied with Python code by means of the Ultralytics library. This library offers us the choice to coach and fine-tune YOLO fashions on our knowledge, or just run inference. Nonetheless, YOLOv10 remains to be not absolutely built-in into the Ultralytics library. We will nonetheless attempt the YOLOv10 and use its code by means of the obtainable Colab pocket book or the HuggingFace areas.
Let’s begin by trying out the HuggingFace house.
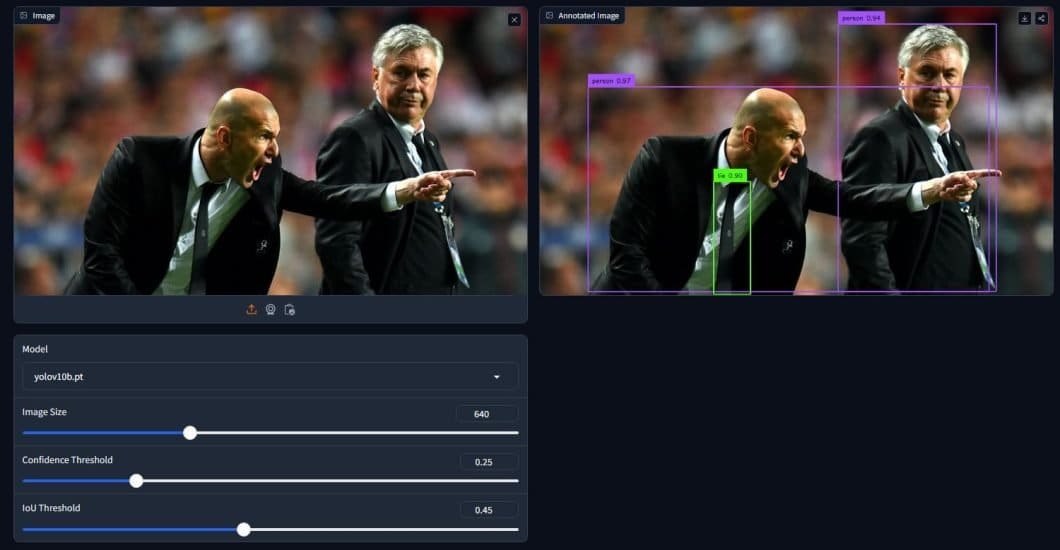
Utilizing one of many examples obtainable, we will see how the YOLOv10 can rapidly generate predictions. We will additionally use the obtainable choices to check and take a look at varied settings and see how they differ. Within the instance above, we’re utilizing the YOLOv10-base mannequin, with a picture dimension of 640×640. Moreover, we have now the arrogance and IoU thresholds.
Whereas the IoU threshold received’t maintain many advantages throughout inference, we have now learnt its significance throughout coaching. Then again, the arrogance threshold is helpful throughout inference, particularly for advanced photographs, a better worth makes extra correct predictions however general fewer predictions, and the other is true.
Inference-Command line Interface (CLI)
Moreover, we will delve into the code for YOLOv10 by means of the Colab pocket book. The pocket book tutorial is fairly clear and provides you choices like operating inference utilizing the command line interface (CLI), or the Python SDK, in addition to an possibility to coach on customized knowledge.
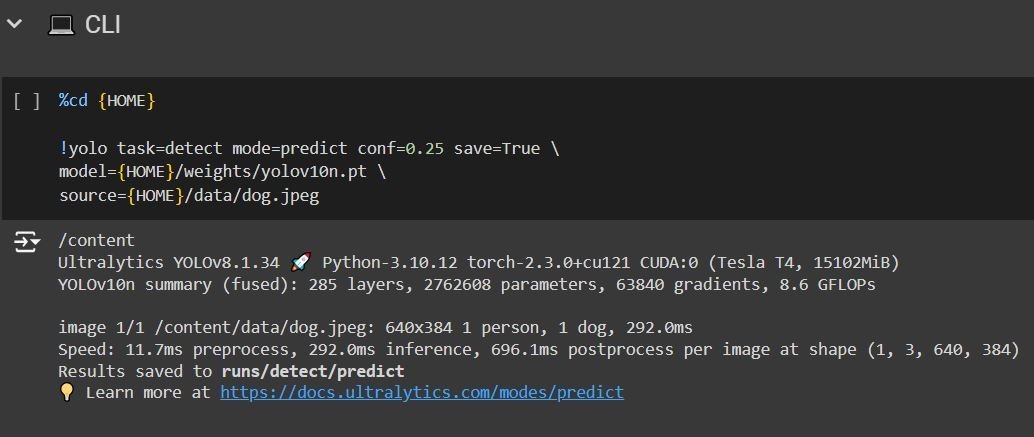
After operating all of the earlier code blocks, you’ll have to run them as they’re as a result of they supply the mandatory setup to make use of YOLOv10. Now you may attempt the CLI inference, the above code makes use of the yolov10-nano mannequin, makes use of a confidence threshold of 0.25, and uploads a picture from the info supplied by the pocket book.
If we need to make inferences on totally different mannequin sizes, a customized picture, or regulate the arrogance threshold we will merely do:
%cd {HOME} #Navigate to residence listing
!yolo activity=detect mode=predict conf=0.25 save=True # utilizing the !yolo command to run cli inference. Outline the duty as prediction, and use the predict mannequin, regulate conf worth as wanted.
mannequin={HOME}/weights/yolov10l.pt # Altering the letter after YOLOv10 will change the mannequin dimension. Mannequin sizes are mentioned earlier within the article.
supply=/content material/instance.jpg # Add Picture on to Colab on the left handside, or mount the drive and duplicate picture path
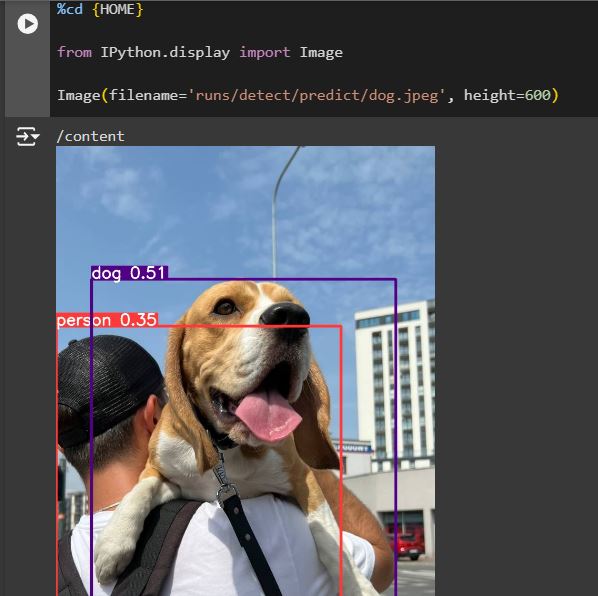
Within the subsequent code block, we will present the outcome prediction utilizing the Python show library, the “filename” variable signifies the place the outcome photographs are saved (discover that we use save=True within the CLI command).
Inference-Python SDK
The code block after that reveals the utilization of YOLOv10 utilizing the Python SDK:
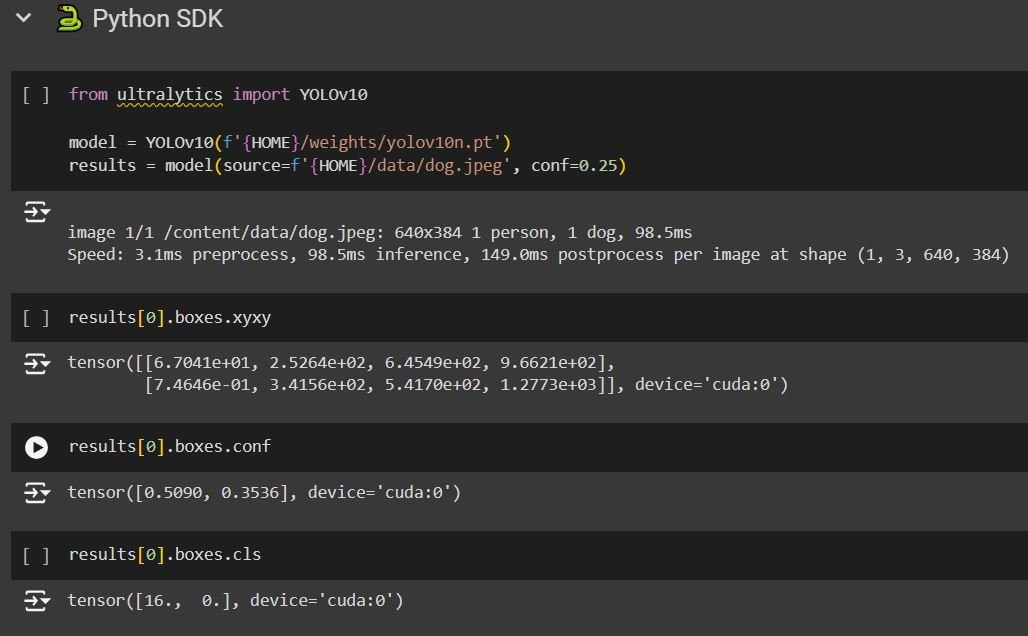
The SDK inference offers us with extra data relating to the prediction. We will see the coordinates of the packing containers, the arrogance, and lastly “packing containers.cls” representing the variety of the class (class) detected.
This code can be adjustable, so you need to use the mannequin dimension and the picture you need. The subsequent code block reveals how we will show the prediction utilizing the “supervision” library, which can even present data just like the postprocessing and preprocessing pace, the inference pace, and the class names.
With this, we have now concluded the utilization of YOLOv10 by means of code and HuggingFace, the pocket book supplied within the official YOLOv10 GitHub is sort of helpful and the tutorial inside will information you thru the method. Nonetheless, coaching the YOLOv10 requires additional effort to create your personal dataset, and iterate with the coaching course of.
Now let’s have a look at methods we will use these enhancements of the YOLOv10 in real-world purposes.
Actual-World Functions For YOLOv10:
YOLOv10’s effectivity, accuracy, and light-weight make it appropriate for a wide range of purposes, maybe changing earlier YOLO fashions in most real-time detection purposes. These new capabilities are pushing the boundaries of what’s attainable in laptop imaginative and prescient.
- Object Monitoring: The latency enchancment in YOLOv10 makes it very appropriate to be used instances that want object-tracking in video streams. Functions vary from sports activities analytics (monitoring gamers and ball motion) to safety surveillance (figuring out suspicious conduct).
- Autonomous Driving: Object detection is the core of self-driving vehicles. The power of an object detection mannequin to detect and classify objects on the highway is crucial for this use case. YOLOv10’s pace and accuracy make it a major candidate for real-time notion techniques in autonomous automobiles.
- Robotic Navigation: Robots geared up with YOLOv10 can navigate advanced environments by precisely recognizing objects and obstacles of their paths. This permits purposes in manufacturing, warehouses, and even family chores
- Agriculture: Object detection will be essential for crop monitoring (figuring out pests, illnesses, or ripe produce) and automatic harvesting. YOLOv10’s accuracy and light-weight make it well-suited for these purposes.
Whereas these are only some purposes, the probabilities are infinite for YOLOv10. A brand new age of real-time object detection is coming, and YOLOv10 is likely to be the beginning.
What’s Subsequent For YOLOv10?
YOLOv10 is a big leap ahead within the evolution of real-time object detection. Its modern structure, intelligent optimization, and memorable efficiency make it a priceless software for a wide range of purposes.
However what does the long run maintain for YOLOv10, and the broader discipline of real-time object detection? One factor is obvious: innovation doesn’t cease right here. Anticipate to see much more refined architectures, streamlined coaching processes, and a wider vary of purposes for this versatile expertise.
YOLOv10 is a big milestone, nevertheless it’s only one step within the ongoing evolution of object detection. We’re excited to see the place this expertise takes us subsequent!
If you wish to know extra in regards to the older fashions and the way Yolov10 is totally different from them, learn our articles under: