
Object detection has seen fast development in recent times due to deep studying algorithms like YOLO (You Solely Look As soon as). The newest iteration, YOLOv9, brings main enhancements in accuracy, effectivity and applicability over earlier variations. On this submit, we’ll dive into the improvements that make YOLOv9 a brand new state-of-the-art for real-time object detection.
A Fast Primer on Object Detection
Earlier than moving into what’s new with YOLOv9, let’s briefly evaluate how object detection works. The aim of object detection is to determine and find objects inside a picture, like vehicles, individuals or animals. It is a key functionality for functions like self-driving vehicles, surveillance programs, and picture search.
The detector takes a picture as enter and outputs bounding bins round detected objects, every with an related class label. In style datasets like MS COCO present hundreds of labeled pictures to coach and consider these fashions.
There are two foremost approaches to object detection:
- Two-stage detectors like Quicker R-CNN first generate area proposals, then classify and refine the boundaries of every area. They are typically extra correct however slower.
- Single-stage detectors like YOLO apply a mannequin immediately over the picture in a single cross. They commerce off some accuracy for very quick inference occasions.
YOLO pioneered the single-stage strategy. Let us take a look at the way it has advanced over a number of variations to enhance accuracy and effectivity.
Overview of Earlier YOLO Variations
The YOLO (You Solely Look As soon as) household of fashions has been on the forefront of quick object detection because the unique model was revealed in 2016. This is a fast overview of how YOLO has progressed over a number of iterations:
- YOLOv1 proposed a unified mannequin to foretell bounding bins and sophistication chances immediately from full pictures in a single cross. This made it extraordinarily quick in comparison with earlier two-stage fashions.
- YOLOv2 improved upon the unique by utilizing batch normalization for higher stability, anchoring bins at numerous scales and side ratios to detect a number of sizes, and a wide range of different optimizations.
- YOLOv3 added a brand new characteristic extractor referred to as Darknet-53 with extra layers and shortcuts between them, additional enhancing accuracy.
- YOLOv4 mixed concepts from different object detectors and segmentation fashions to push accuracy even increased whereas nonetheless sustaining quick inference.
- YOLOv5 absolutely rewrote YOLOv4 in PyTorch and added a brand new characteristic extraction spine referred to as CSPDarknet together with a number of different enhancements.
- YOLOv6 continued to optimize the structure and coaching course of, with fashions pre-trained on giant exterior datasets to spice up efficiency additional.
So in abstract, earlier YOLO variations achieved increased accuracy via enhancements to mannequin structure, coaching strategies, and pre-training. However as fashions get larger and extra complicated, pace and effectivity begin to undergo.
The Want for Higher Effectivity
Many functions require object detection to run in real-time on gadgets with restricted compute sources. As fashions change into bigger and extra computationally intensive, they change into impractical to deploy.
For instance, a self-driving automotive must detect objects at excessive body charges utilizing processors contained in the automobile. A safety digital camera must run object detection on its video feed inside its personal embedded {hardware}. Telephones and different shopper gadgets have very tight energy and thermal constraints.
Current YOLO variations receive excessive accuracy with giant numbers of parameters and multiply-add operations (FLOPs). However this comes at the price of pace, measurement and energy effectivity.
For instance, YOLOv5-L requires over 100 billion FLOPs to course of a single 1280×1280 picture. That is too gradual for a lot of real-time use instances. The pattern of ever-larger fashions additionally will increase danger of overfitting and makes it tougher to generalize.
So with a purpose to increase the applicability of object detection, we want methods to enhance effectivity – getting higher accuracy with much less parameters and computations. Let us take a look at the strategies utilized in YOLOv9 to sort out this problem.
YOLOv9 – Higher Accuracy with Much less Assets
The researchers behind YOLOv9 centered on enhancing effectivity with a purpose to obtain real-time efficiency throughout a wider vary of gadgets. They launched two key improvements:
- A brand new mannequin structure referred to as Common Environment friendly Layer Aggregation Community (GELAN) that maximizes accuracy whereas minimizing parameters and FLOPs.
- A coaching method referred to as Programmable Gradient Data (PGI) that gives extra dependable studying gradients, particularly for smaller fashions.
Let us take a look at how every of those developments helps enhance effectivity.
Extra Environment friendly Structure with GELAN
The mannequin structure itself is essential for balancing accuracy in opposition to pace and useful resource utilization throughout inference. The neural community wants sufficient depth and width to seize related options from the enter pictures. However too many layers or filters result in gradual and bloated fashions.
The authors designed GELAN particularly to squeeze the utmost accuracy out of the smallest doable structure.
GELAN makes use of two foremost constructing blocks stacked collectively:
- Environment friendly Layer Aggregation Blocks – These combination transformations throughout a number of community branches to seize multi-scale options effectively.
- Computational Blocks – CSPNet blocks assist propagate info throughout layers. Any block might be substituted primarily based on compute constraints.
By fastidiously balancing and mixing these blocks, GELAN hits a candy spot between efficiency, parameters, and pace. The identical modular structure can scale up or down throughout completely different sizes of fashions and {hardware}.
Experiments confirmed GELAN matches extra efficiency into smaller fashions in comparison with prior YOLO architectures. For instance, GELAN-Small with 7M parameters outperformed the 11M parameter YOLOv7-Nano. And GELAN-Medium with 20M parameters carried out on par with YOLOv7 medium fashions requiring 35-40M parameters.
So by designing a parameterized structure particularly optimized for effectivity, GELAN permits fashions to run quicker and on extra useful resource constrained gadgets. Subsequent we’ll see how PGI helps them prepare higher too.
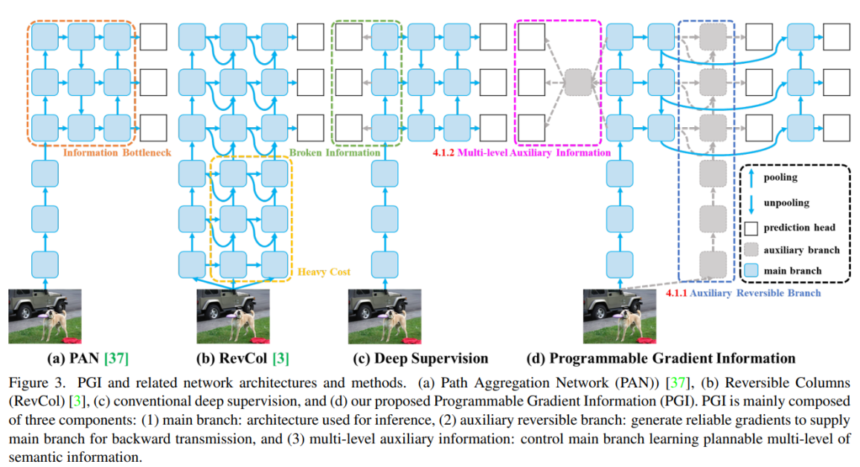
Higher Coaching with Programmable Gradient Data (PGI)
Mannequin coaching is simply as essential to maximise accuracy with restricted sources. The YOLOv9 authors recognized points coaching smaller fashions attributable to unreliable gradient info.
Gradients decide how a lot a mannequin’s weights are up to date throughout coaching. Noisy or deceptive gradients result in poor convergence. This problem turns into extra pronounced for smaller networks.
The strategy of deep supervision addresses this by introducing further facet branches with losses to propagate higher gradient sign via the community. But it surely tends to interrupt down and trigger divergence for smaller light-weight fashions.

YOLOv9: Studying What You Wish to Study Utilizing Programmable Gradient Data https://arxiv.org/abs/2402.13616
To beat this limitation, YOLOv9 introduces Programmable Gradient Data (PGI). PGI has two foremost elements:
- Auxiliary reversible branches – These present cleaner gradients by sustaining reversible connections to the enter utilizing blocks like RevCols.
- Multi-level gradient integration – This avoids divergence from completely different facet branches interfering. It combines gradients from all branches earlier than feeding again to the principle mannequin.
By producing extra dependable gradients, PGI helps smaller fashions prepare simply as successfully as larger ones:
Experiments confirmed PGI improved accuracy throughout all mannequin sizes, particularly smaller configurations. For instance, it boosted AP scores of YOLOv9-Small by 0.1-0.4% over baseline GELAN-Small. The positive aspects had been much more vital for deeper fashions like YOLOv9-E at 55.6% mAP.
So PGI permits smaller, environment friendly fashions to coach to increased accuracy ranges beforehand solely achievable by over-parameterized fashions.
YOLOv9 Units New State-of-the-Artwork for Effectivity
By combining the architectural advances of GELAN with the coaching enhancements from PGI, YOLOv9 achieves unprecedented effectivity and efficiency:
- In comparison with prior YOLO variations, YOLOv9 obtains higher accuracy with 10-15% fewer parameters and 25% fewer computations. This brings main enhancements in pace and functionality throughout mannequin sizes.
- YOLOv9 surpasses different real-time detectors like YOLO-MS and RT-DETR when it comes to parameter effectivity and FLOPs. It requires far fewer sources to succeed in a given efficiency stage.
- Smaller YOLOv9 fashions even beat bigger pre-trained fashions like RT-DETR-X. Regardless of utilizing 36% fewer parameters, YOLOv9-E achieves higher 55.6% AP via extra environment friendly architectures.
So by addressing effectivity on the structure and coaching ranges, YOLOv9 units a brand new state-of-the-art for maximizing efficiency inside constrained sources.
GELAN – Optimized Structure for Effectivity
YOLOv9 introduces a brand new structure referred to as Common Environment friendly Layer Aggregation Community (GELAN) that maximizes accuracy inside a minimal parameter funds. It builds on high of prior YOLO fashions however optimizes the assorted elements particularly for effectivity.

YOLOv9: Studying What You Wish to Study Utilizing Programmable Gradient Data
https://arxiv.org/abs/2402.13616
Background on CSPNet and ELAN
Current YOLO variations since v5 have utilized backbones primarily based on Cross-Stage Partial Community (CSPNet) for improved effectivity. CSPNet permits characteristic maps to be aggregated throughout parallel community branches whereas including minimal overhead:
That is extra environment friendly than simply stacking layers serially, which frequently results in redundant computation and over-parameterization.
YOLOv7 upgraded CSPNet to Environment friendly Layer Aggregation Community (ELAN), which simplified the block construction:
ELAN eliminated shortcut connections between layers in favor of an aggregation node on the output. This additional improved parameter and FLOPs effectivity.
Generalizing ELAN for Versatile Effectivity
The authors generalized ELAN even additional to create GELAN, the spine utilized in YOLOv9. GELAN made key modifications to enhance flexibility and effectivity:
- Interchangeable computational blocks – Earlier ELAN had fastened convolutional layers. GELAN permits substituting any computational block like ResNets or CSPNet, offering extra architectural choices.
- Depth-wise parametrization – Separate block depths for foremost department vs aggregator department simplifies fine-tuning useful resource utilization.
- Secure efficiency throughout configurations – GELAN maintains accuracy with completely different block varieties and depths, permitting versatile scaling.
These adjustments make GELAN a robust however configurable spine for maximizing effectivity:
In experiments, GELAN fashions constantly outperformed prior YOLO architectures in accuracy per parameter:
- GELAN-Small with 7M parameters beat YOLOv7-Nano’s 11M parameters
- GELAN-Medium matched heavier YOLOv7 medium fashions
So GELAN offers an optimized spine to scale YOLO throughout completely different effectivity targets. Subsequent we’ll see how PGI helps them prepare higher.
PGI – Improved Coaching for All Mannequin Sizes
Whereas structure selections impression effectivity at inference time, coaching course of additionally impacts mannequin useful resource utilization. YOLOv9 makes use of a brand new method referred to as Programmable Gradient Data (PGI) to enhance coaching throughout completely different mannequin sizes and complexities.
The Drawback of Unreliable Gradients
Throughout coaching, a loss operate compares mannequin outputs to floor reality labels and computes an error gradient to replace parameters. Noisy or deceptive gradients result in poor convergence and effectivity.
Very deep networks exacerbates this via the info bottleneck – gradients from deep layers are corrupted by misplaced or compressed indicators.
Deep supervision helps by introducing auxiliary facet branches with losses to supply cleaner gradients. But it surely typically breaks down for smaller fashions, inflicting interference and divergence between completely different branches.
So we want a means to supply dependable gradients that works throughout all mannequin sizes, particularly smaller ones.
Introducing Programmable Gradient Data (PGI)
To deal with unreliable gradients, YOLOv9 proposes Programmable Gradient Data (PGI). PGI has two foremost elements designed to enhance gradient high quality:
1. Auxiliary reversible branches
Further branches present reversible connections again to the enter utilizing blocks like RevCols. This maintains clear gradients avoiding the data bottleneck.
2. Multi-level gradient integration
A fusion block aggregates gradients from all branches earlier than feeding again to the principle mannequin. This prevents divergence throughout branches.
By producing extra dependable gradients, PGI improves coaching convergence and effectivity throughout all mannequin sizes:
- Light-weight fashions profit from deep supervision they could not use earlier than
- Bigger fashions get cleaner gradients enabling higher generalization
Experiments confirmed PGI boosted accuracy for small and huge YOLOv9 configurations over baseline GELAN:
- +0.1-0.4% AP for YOLOv9-Small
- +0.5-0.6% AP for bigger YOLOv9 fashions
So PGI’s programmable gradients allow fashions massive and small to coach extra effectively.
YOLOv9 Units New State-of-the-Artwork Accuracy
By combining architectural enhancements from GELAN and coaching enhancements from PGI, YOLOv9 achieves new state-of-the-art outcomes for real-time object detection.
Experiments on the COCO dataset present YOLOv9 surpassing prior YOLO variations, in addition to different real-time detectors like YOLO-MS, in accuracy and effectivity:
Some key highlights:
- YOLOv9-Small exceeds YOLO-MS-Small with 10% fewer parameters and computations
- YOLOv9-Medium matches heavier YOLOv7 fashions utilizing lower than half the sources
- YOLOv9-Giant outperforms YOLOv8-X with 15% fewer parameters and 25% fewer FLOPs
Remarkably, smaller YOLOv9 fashions even surpass heavier fashions from different detectors that use pre-training like RT-DETR-X. Regardless of 4x fewer parameters, YOLOv9-E outperforms RT-DETR-X in accuracy.
These outcomes show YOLOv9’s superior effectivity. The enhancements allow high-accuracy object detection in additional real-world use instances.
Key Takeaways on YOLOv9 Upgrades
Let’s shortly recap among the key upgrades and improvements that allow YOLOv9’s new state-of-the-art efficiency:
- GELAN optimized structure – Improves parameter effectivity via versatile aggregation blocks. Permits scaling fashions for various targets.
- Programmable gradient info – Supplies dependable gradients via reversible connections and fusion. Improves coaching throughout mannequin sizes.
- Larger accuracy with fewer sources – Reduces parameters and computations by 10-15% over YOLOv8 with higher accuracy. Permits extra environment friendly inference.
- Superior outcomes throughout mannequin sizes – Units new state-of-the-art for light-weight, medium, and huge mannequin configurations. Outperforms closely pre-trained fashions.
- Expanded applicability – Larger effectivity broadens viable use instances, like real-time detection on edge gadgets.
By immediately addressing accuracy, effectivity, and applicability, YOLOv9 strikes object detection ahead to fulfill various real-world wants. The upgrades present a robust basis for future innovation on this essential pc imaginative and prescient functionality.

