The most recent set up within the YOLO sequence, YOLOv9, was launched on February twenty first, 2024. Since its inception in 2015, the YOLO (You Solely Look As soon as) object-detection algorithm has been intently adopted by tech fanatics, information scientists, ML engineers, and extra, gaining a large following resulting from its open-source nature and group contributions. With each new launch, the YOLO structure turns into simpler to make use of and far sooner, decreasing the boundaries to make use of for folks around the globe.
YOLO was launched as a analysis paper by J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, signifying a step ahead within the real-time object detection house, outperforming its predecessor – the Area-based Convolutional Neural Community (R-CNN). It’s a single-pass algorithm having just one neural community to foretell bounding containers and sophistication possibilities utilizing a full picture as enter.

What’s YOLOv9?
YOLOv9 is the newest model of YOLO, launched in February 2024, by Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao. It’s an improved real-time object detection mannequin that goals to surpass all convolution-based, and transformer-based strategies.
YOLOv9 is launched in 4 fashions, ordered by parameter rely: v9-S, v9-M, v9-C, and v9-E. To enhance accuracy, it introduces programmable gradient info (PGI) and the Generalized Environment friendly Layer Aggregation Community (GELAN). PGI prevents information loss and ensures correct gradient updates and GELAN optimizes light-weight fashions with gradient path planning.
At the moment, the one laptop imaginative and prescient activity supported by YOLOv9 is object detection.

YOLO Model Historical past
Earlier than diving into the YOLOv9 specifics, let’s briefly recap on the opposite YOLO variations obtainable immediately.
YOLOv1
YOLOv1 structure (displayed above) surpassed R-CNN with a imply common precision (mAP) of 63.4, and an inference pace of 45 FPS on the open-source Pascal VOC 2007 dataset. With YOLOv1, object detection is handled as a regression activity to foretell bounding containers and sophistication possibilities from a single go of a picture.
YOLOv2
Launched in 2016, it might detect 9000+ object classes. YOLOv2 launched anchor containers – predefined bounding containers known as priors that the mannequin makes use of to pin down the best place of an object. YOLOv2 achieved 76.8 mAP at 67 FPS on the VOC 2007 dataset.
YOLOv3
The authors launched YOLOv3 in 2018 which boasted increased accuracy than earlier variations, with an mAP of 28.2 at 22 milliseconds. To foretell lessons, the YOLOv3 mannequin makes use of Darknet-53 because the spine with logistic classifiers as an alternative of softmax and Binary Cross-entropy (BCE) loss.

YOLOv4
2020, Alexey Bochkovskiy et al. launched YOLOv4, introducing the idea of a Bag of Freebies (BoF) and a Bag of Specials (BoS). BoF is a set of information augmentation strategies that enhance accuracy at no extra inference value. (BoS considerably enhances accuracy with a slight enhance in value). The mannequin achieved 43.5 mAP at 65 FPS on the COCO dataset.
YOLOv5
With out an official analysis paper, Ultralytics launched YOLOv5 additionally in 2020. The mannequin is straightforward to coach since it’s applied in PyTorch. The mannequin structure makes use of a Cross-stage Partial (CSP) Connection block because the spine for a greater gradient circulation to scale back computational value. YOLOv5 makes use of YAML information as an alternative of CFG information within the mannequin configurations.

YOLOv6
YOLOv6 is one other unofficial model launched in 2022 by Meituan – a Chinese language purchasing platform. The corporate focused the mannequin for industrial functions with higher efficiency than its predecessor. The modifications resulted in YOLOv6n reaching an mAP of 37.5 at 1187 FPS on the COCO dataset and YOLOv6s reaching 45 mAP at 484 FPS.
YOLOv7
In July 2022, a bunch of researchers launched the open-source mannequin YOLOv7, the quickest and probably the most correct object detector with an mAP of 56.8% at FPS starting from 5 to 160. YOLOv7 is predicated on the Prolonged Environment friendly Layer Aggregation Community (E-ELAN), which improves coaching by letting the mannequin study various options with environment friendly computation.

YOLOv8
YOLOv8 has no official paper (as with YOLOv5 and v6) however boasts increased accuracy and sooner pace for state-of-the-art efficiency. As an illustration, the YOLOv8m has a 50.2 mAP rating at 1.83 milliseconds on the MS COCO dataset and A100 TensorRT. YOLO v8 additionally incorporates a Python bundle and CLI-based implementation, making it simple to make use of and develop.

Structure YOLOv9
To deal with the knowledge bottleneck (information loss within the feed-forward course of), YOLOv9 creators suggest a brand new idea, i.e. the programmable gradient info (PGI). The mannequin generates dependable gradients through an auxiliary reversible department. Deep options nonetheless execute the goal activity and the auxiliary department avoids the semantic loss resulting from multi-path options.
The authors achieved the most effective coaching outcomes by making use of PGI propagation at completely different semantic ranges. The reversible structure of PGI is constructed on the auxiliary department, so there isn’t any extra value. Since PGI can freely choose a loss operate appropriate for the goal activity, it additionally overcomes the issues encountered by masks modeling.
The proposed PGI mechanism may be utilized to deep neural networks of varied sizes. Within the paper, the authors designed a generalized ELAN (GELAN) that concurrently takes under consideration the variety of parameters, computational complexity, accuracy, and inference pace. The design permits customers to decide on applicable computational blocks arbitrarily for various inference units.
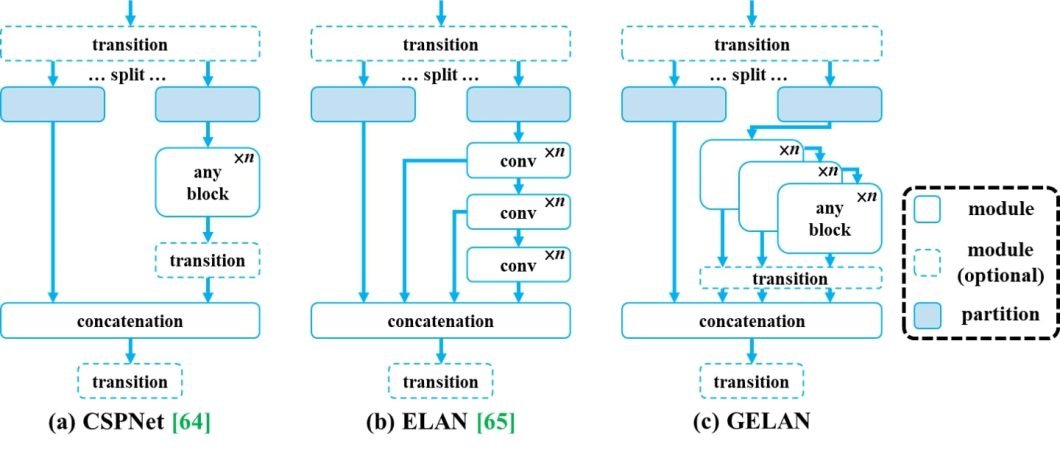
Utilizing the proposed PGI and GELAN – the authors designed YOLOv9. To conduct experiments they used the MS COCO dataset, and the experimental outcomes verified that the proposed YOLO v9 achieved the highest efficiency in all circumstances.
Analysis Contributions
- Theoretical evaluation of deep neural community structure from the angle of reversible operate. The authors designed PGI and auxiliary reversible branches based mostly on this evaluation and achieved glorious outcomes.
- The designed PGI solves the issue that deep supervision can solely be used for very deep neural community architectures. Thus, it permits new light-weight architectures to be really utilized in day by day life.
- The GELAN community solely makes use of standard convolution to realize the next parameter utilization than the depth sensible convolution design. So it reveals the nice benefits of being gentle, quick, and correct.
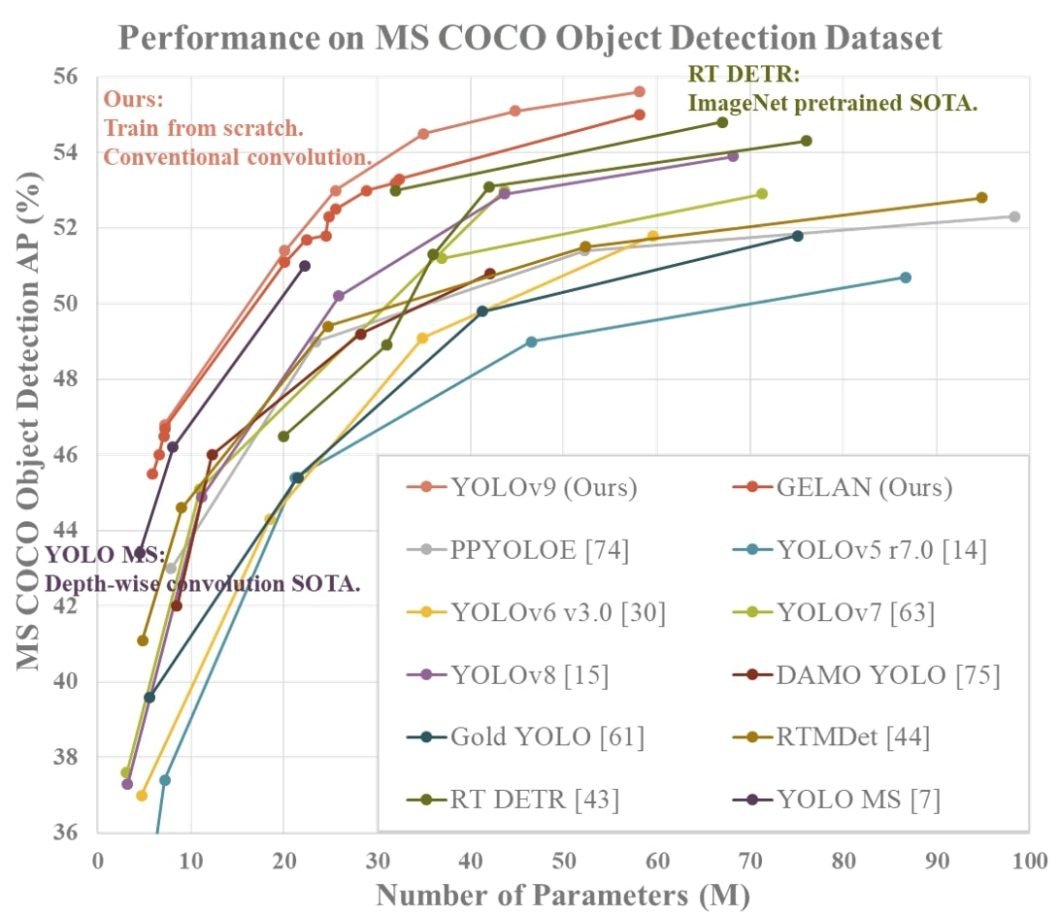
- Combining the proposed PGI and GELAN, the article detection efficiency of the YOLOv9 on the MS COCO dataset largely surpasses the present real-time object detectors in all points.
YOLOv9 License
YOLOv9 was not launched with an official license. Within the following days, nonetheless WongKinYiu up to date the official license to GPL-3.0. YOLOv7 and YOLOv9 have been launched beneath WongKinYiu’s repository.
Benefits of YOLOv9
YOLOv9 arises as a strong mannequin, providing revolutionary options that can play an necessary function within the additional improvement of object detection, and perhaps even picture segmentation and classification down the highway. It gives sooner, clearer, and extra versatile actions, and different benefits embrace:
- Dealing with the knowledge bottleneck and adapting deep supervision to light-weight architectures of neural networks by introducing the Programmable Gradient Data (PGI).
- Creating the GELAN, a sensible and efficient neural community. GELAN has confirmed its sturdy and secure efficiency in object detection duties at completely different convolution and depth settings. It may very well be extensively accepted as a mannequin appropriate for numerous inference configurations.
- By combining PGI and GELAN – YOLOv9 has proven sturdy competitiveness. Its intelligent design permits the deep mannequin to scale back the variety of parameters by 49% and the variety of calculations by 43% in contrast with YOLOv9. And it nonetheless has a 0.6% Common Precision enchancment on the MS COCO dataset.
- The developed YOLOv9 mannequin is superior to RT-DETR and YOLO-MS when it comes to accuracy and effectivity. It units new requirements in light-weight mannequin efficiency by making use of standard convolution for higher parameter utilization.
| Mannequin | #Param. | FLOPs | AP50:95val | APSval | APMval | APLval |
|---|---|---|---|---|---|---|
| YOLOv7 [63] | 36.9 | 104.7 | 51.2% | 31.8% | 55.5% | 65.0% |
| + AF [63] | 43.6 | 130.5 | 53.0% | 35.8% | 58.7% | 68.9% |
| + GELAN | 41.7 | 127.9 | 53.2% | 36.2% | 58.5% | 69.9% |
| + DHLC [34] | 58.1 | 192.5 | 55.0% | 38.0% | 60.6% | 70.9% |
| + PGI | 58.1 | 192.5 | 55.6% | 40.2% | 61.0% | 71.4% |
The above desk demonstrates common precision (AP) of varied object detection fashions.
YOLOv9 Purposes
YOLOv9 is a versatile laptop imaginative and prescient mannequin that you should use in several real-world functions. Right here we recommend just a few fashionable use circumstances.

- Logistics and distribution: Object detection can help in estimating product stock ranges to make sure enough inventory ranges and supply info relating to shopper habits.
- Autonomous automobiles: Autonomous automobiles can make the most of YOLOv9 object detection to assist navigate self-driving vehicles safely by the highway.
- Folks counting: Retailers and purchasing malls can prepare the mannequin to detect real-time foot visitors of their outlets, detect queue size, and extra.
- Sports activities analytics: Analysts can use the mannequin to trace participant actions in a sports activities subject to assemble related insights relating to crew efficiency.

YOLOv9: Principal Takeaways
The YOLO fashions are the usual within the object detection house with their nice efficiency and broad applicability. Listed below are our first conclusions about YOLOv9:
- Ease-of-use: YOLOv9 is already in GitHub, so the customers can implement YOLOv9 shortly by the CLI and Python IDE.
- YOLOv9 duties: YOLOv9 is environment friendly for real-time object detection with improved accuracy and pace.
- YOLOv9 enhancements: YOLOv9’s predominant enhancements embrace a decoupled head with anchor-free detection and mosaic information augmentation that turns off within the final ten coaching epochs.
Sooner or later, we stay up for seeing if the creators will develop YOLOv9 capabilities to a variety of different laptop imaginative and prescient duties as effectively.
Viso Suite is the end-to-end platform for no code laptop imaginative and prescient. Viso Suite provides a bunch of pre-trained fashions to select from, or the likelihood to import or prepare your individual customized AI fashions. To study how one can resolve your trade’s challenges with no-code laptop imaginative and prescient, guide a demo of Viso Suite.