
The power and efficiency of smaller, open giant language fashions have superior considerably lately, and we’ve witnessed the progress from early GPT-2 fashions to extra compact, correct, and efficient LLM frameworks that make use of a significantly bigger quantity of tokens that the “compute-optimal” quantity of tokens really useful by the Chinchilla scaling legal guidelines. Moreover, builders have demonstrated that these smaller LLM frameworks will be skilled additional utilizing a proprietary-models based mostly dSFT or Distilled Supervised Fantastic-Tuning method, that makes use of the output from an efficient trainer mannequin as supervised knowledge for the scholar mannequin in an try to spice up the accuracy.
On this article, we can be speaking concerning the Zephyr-7B framework, a state-of-the-art chat benchmark for 7B parameter fashions that doesn’t require human annotations. The first purpose of the framework is to allow builders to supply smaller giant language fashions which can be aligned to the consumer intent nearer than ever earlier than. The Zephyr-7B framework not solely examines the applying of present approaches for bigger LLM frameworks like dSFT, but in addition explores the potential of utilizing different approaches to be taught a chat mannequin with higher alignment with the consumer intent. We can be taking a deeper dive into the Zephyr framework, and discover its structure, working, and outcomes. So let’s get began.
As talked about earlier, language fashions have progressed quickly lately, from the sooner GPT-2 frameworks to present GPT-4 and MiniGPT-5 LLM frameworks that though are extremely token exhaustive, are actually extra correct, and rather more environment friendly. A serious spotlight of those superior LLM frameworks is that they incorporate a considerably greater quantity of tokens than the variety of tokens that have been earlier thought-about to be computationally optimum below the Chinchilla scaling legal guidelines. Moreover, builders and researchers engaged on LLM frameworks have realized that these smaller LLM frameworks will be skilled additional utilizing a proprietary-models based mostly dSFT or Distilled Supervised Fantastic-Tuning method, that makes use of the output from an efficient trainer mannequin as supervised knowledge for the scholar mannequin in an try to spice up the accuracy. The distillation technique has confirmed itself to be a extremely efficient, and useful gizmo to maximise the potential and talents of open fashions on a big selection of duties, though it but can’t replicate the efficiency achieved by the trainer mannequin. Moreover, customers have typically reported that these fashions typically show “intent misalignment”, that means the fashions don’t behave in a way that aligns with the necessities of the top customers, resulting in incorrect outputs that don’t present the proper output or responses to the consumer inputs or queries.
Intent alignment has at all times been a significant problem for builders with current works specializing in improvement of benchmarks like AlpacaEval and MT-Bench developed to focus on the misalignment. The motivation for creating the Zephyr framework will be credited to the issue of utilizing distillation to align a small open LLM framework solely the place the first step is to make the most of an AIF or Synthetic Intelligence Suggestions to acquire desire knowledge from an ensemble of the trainer mannequin, after which making use of distilled desire optimization immediately as the first studying goal, an method that’s known as dDPO or Denoising Diffusion Coverage Optimization. The principle spotlight of the dDPO method is that not like its predecessors like PPO or Proximal Choice Optimization, it doesn’t require human sampling or annotations, and likewise reduces the time it takes to coach a language mannequin. Moreover, it additionally permits builders to maximise the rewards of the ultimate pattern by paying shut consideration to the sequence of the denoising steps proper from the start until the top, in different phrases, all through its entirety.
Builders have developed the Zephyr-7B framework to validate this method, and in some methods, it’s an aligned model of the state-of-the-art Mistral-7B framework. The framework first makes use of dSFT or Distilled Supervised Fantastic-Tuning based mostly on the UltraChat dataset, and applies the dDPO or Denoising Diffusion Coverage Optimization method on the suggestions knowledge. Experiments point out that the Zephyr-7B framework with 7 billion parameters delivers outcomes akin to the one delivered by human-feedback aligned chat fashions with over 70 billion parameters. Moreover, experiments additionally point out that outcomes will be improved each when it comes to benchmarks that take conversational capabilities under consideration, in addition to commonplace educational benchmarks, and using desire studying is important to attain the specified outcomes.

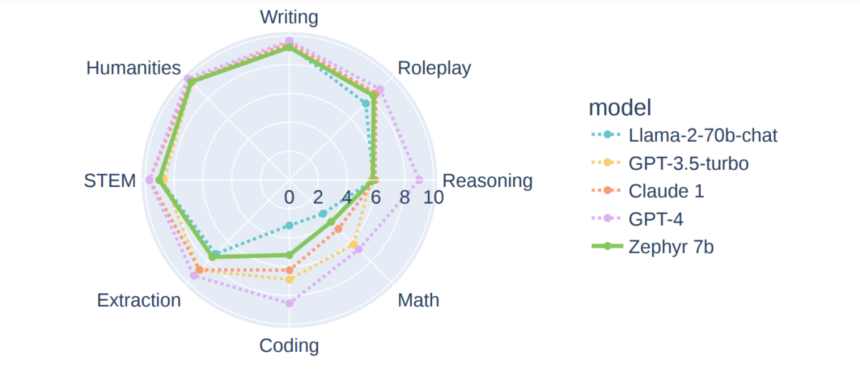
The above determine demonstrates the efficiency of varied language fashions on the MT-bench benchmark. The Zephyr-7B framework that’s skilled utilizing the dDPO method is put up towards proprietary in addition to open-access, bigger language fashions like GPT-3.5 turbo, Llama-2-70B, and extra that have been skilled utilizing extra reinforcement studying, and likewise included an enormous quantity of human suggestions. As it may be clearly seen that regardless of the sheer distinction within the variety of parameters that these frameworks use, the Zephyr-7B framework delivers comparable outcomes towards most of them, and outperforms a number of frameworks in several domains.
Zephyr-7B : Technique, Working and Structure
The first objective of the Zephyr-7B framework is to assist an open-source giant language mannequin align as shut as attainable to the consumer intent, and all through its entirety, the Zephyr-7B framework assumes entry to a big trainer mannequin that’s queried utilizing immediate technology. The Zephyr-7B follows an method just like the one used within the InstructGPT framework, and goals to generate an efficient, and correct pupil mannequin.
The next determine briefly demonstrates the three major steps concerned within the working of the Zephyr-7B framework.
- dSFT for large-scale dataset development utilizing a self-instruction model.
- AIF assortment utilizing an ensemble of finishing chat fashions adopted by desire binarization, and scoring by GPT-4.
- dPO of the dSFT mannequin by making use of the suggestions knowledge.

dSFT or Distilled Supervised Fantastic-Tuning
The framework begins with a uncooked Giant Language Mannequin that first must be skilled to reply to consumer prompts. Historically, coaching these LLM frameworks to reply to consumer prompts is completed utilizing SFT or Supervised Fantastic Tuning on a dataset consisting of high-quality directions, and their corresponding responses. Since, the Zephyr-7B framework has entry to a trainer language mannequin, the framework can generate directions and responses, and prepare the mannequin immediately on these directions and responses, and this method is called dSFT or distilled SFT. The next determine demonstrates the distillation carried out by SFT the place x represents a set of seed prompts constructed with the first objective of representing a various set of topical domains, y represents the pattern response, that’s refined utilizing a brand new pattern instruction represented by x1 and C represents the top level within the ultimate dataset.

AI Suggestions via Preferences
Human suggestions is used to assign Giant Language Fashions as they will present the required extra indicators, and these human feedbacks are historically supplied via preferences on the standard of the responses generated by the LLM frameworks. Nevertheless, the Zephyr framework makes use of AI Suggestions from the trainer mannequin on different fashions’ generated outputs as a substitute of human suggestions for distillation functions. The method adopted by the Zephyr framework is influenced by the one utilized by the UltraFeedback framework that makes use of the trainer mannequin to offer preferences on the outputs of the mannequin.
Much like the SFT or Supervised Fantastic Tuning method, it begins with a set of prompts, the place x represents each particular person immediate that’s then fed to a set of 4 fashions like Llama, Falcon, Claude, and extra, every of which generate a response of their very own. These responses are then fed as an enter to the trainer mannequin like GPT-3 or GPT-4, and the mannequin outputs a rating for the enter response. After gathering the output scores, the mannequin saves the response with the best rating.
dDPO or Distilled Direct Choice Optimization
dDPO is the ultimate step of the Zephyr framework, and its major objective is to refine the dSFT trainer mannequin by maximizing the likelihood of rating the popular response in a desire mannequin that’s decided by a reward operate by using the scholar language mannequin. The earlier step involving using AI suggestions focussed totally on utilizing Reinforcement Studying strategies like PPO or Proximal Coverage Optimization for max optimization with respect to the reward generated. On this step, the reward is first skilled, after which sampled from the present coverage to calculate the updates, and thus maximizing the optimization. DPO or Direct Choice Optimization follows an identical method to optimize the desire mannequin immediately utilizing the static knowledge. The target after plugging the reward operate into desire mannequin will be written as

Zephyr-7B : Experiments, Benchmarks and Outcomes
The Zephyr framework conducts its fine-tuning experiments on the present state-of-the-art Mistral-7B framework that delivers comparable efficiency to a lot bigger language fashions on a big selection of pure language processing or NLP duties.
Datasets
The Zephyr framework makes use of two dialogue datasets which have been distilled from a mix of proprietary and open fashions, which have beforehand proved themselves to be efficient in producing efficient chat fashions.
UltraChat
UltraChat is a self-refinement dataset that consists of practically 1.5 million multi-turn dialogues unfold over 30 subjects, and 20 textual content supplies generated by the GPT-3.5-Turbo framework. To sort out the inaccurate capitalization concern confronted by the UltraChat dataset, the framework applies a truecasing heuristics method to do away with the grammatical errors.
UltraFeedback
The UltraFeedback is a immediate dataset with over 64k prompts, with every of those prompts having 4 particular person LLM responses. The Zephyr framework makes use of the best imply rating obtained from the UltraFeedback dataset to assemble binary preferences, and one of many remaining three LLM responses is rejected as random.
Analysis
To guage the efficiency of the Zephyr framework, builders have opted for 2 chat benchmarks, one single-turn, and one multi-turn, in an try to judge the power of the mannequin to observe consumer directions, and reply accordingly.
MT-Bench
The MT-Bench analysis benchmark consists of 160 questions unfold over 8 distinctive information areas, and below the MT-Bench benchmark, the mannequin has to reply an preliminary query, and supply a response on the follow-up query.
AlpacaEval
AlpacaEval is a single-turn benchmark below which the mannequin or the framework generates consumer responses to over 800 questions unfold throughout totally different subjects with the first focus being on helpfulness.
Along with these two major benchmarks, the Zephyr-7B framework can be evaluated on Open LLM Leaderboard for multiclass classification duties, ARC, HellaSwag, MMLU, and extra. Moreover, no matter what benchmark the Zephyr-7B framework is evaluated on, it’s in contrast towards a spread of proprietary and open fashions, with their alignment procedures being the one differentiating issue.
Outcomes
Let’s now take a look at how the Zephyr-7B framework performs, and compares towards present state-of-the-art language fashions.
Implementation of dDPO Method Boosts Chat Capabilities
The next desk compares the efficiency of the Zephyr-7B framework towards state-of-the-art language fashions on the AlpacaEval, and MT-Bench benchmarks.

As it may be clearly seen, when put towards open 7B fashions, the Zephyr-7B framework not solely considerably outperforms dSFT fashions throughout the 2 benchmarks, but in addition units new state-of-the-art requirements. Moreover, the Zephyr-7B framework additionally manages to outscore the XWIN-LM-7B framework, which is likely one of the uncommon fashions skilled on the dPPO or distilled PPO method. Moreover, the efficiency delivered by the Zephyr-7B framework is akin to the outcomes delivered by a lot bigger language fashions like Llama2-Chat with over 70B parameters.
dDPO Boosts Educational Job Efficiency
The next determine compares the efficiency of the Zephyr-7B framework towards a big selection of open-source, and proprietary LLM frameworks.

As it may be seen, the Zephyr-7B framework considerably outperforms LLM frameworks with 7B parameters, and the hole between its efficiency, and the one delivered by the most effective performing dSFT fashions can be noticeable. Because the variety of parameters will increase, the Zephyr-7B framework does fall brief, though it matches the efficiency delivered by frameworks with 40 billion parameters.
Choice Optimization
Within the following determine, we consider how the totally different steps adopted within the alignment course of impacts the efficiency. As it may be noticed, the dDPO method when mixed with dSFT considerably boosts the efficiency on each the MT-Bench and AlpacaEval datasets.

Lastly, within the following determine we will see the testing and coaching accuracies through the DPO implementation. As it may be seen, the DPO method doesn’t have an effect on the efficiency of the mannequin on downstream duties.

Conclusion
On this article, we’ve talked concerning the Zephyr-7B framework based mostly on the present state-of-the-art Mistral-7B framework that goals to unravel the present problem of alignment distillation from a big language mannequin to a a lot smaller pretrained framework. The first purpose of the framework is to allow builders to supply smaller giant language fashions which can be aligned to the consumer intent nearer than ever earlier than. The Zephyr-7B framework not solely examines the applying of present approaches for bigger LLM frameworks like dSFT, but in addition explores the potential of utilizing different approaches to be taught a chat mannequin with higher alignment with the consumer intent.
Nevertheless, regardless of the promising outcomes, the Zephyr-7B framework will not be excellent, and a few work nonetheless must be accomplished. One of many apparent limitations is utilizing the GPT-4 framework to judge MT-Bench and AlpacaEval benchmarks, which has typically been biased in direction of the fashions it distills itself. Nevertheless, the Zephyr-7B framework hopes to carve a approach for exploring the capabilities of smaller open fashions which can be able to aligning with the consumer intent and interactions.