
Mannequin drift is an umbrella time period encompassing a spectrum of modifications that impression machine studying mannequin efficiency. Two of crucial ideas underlying this space of research are idea drift vs information drift.
These phenomena manifest when sure elements alter the statistical properties of mannequin inputs or outputs. Most often, this necessitates updating the mannequin to account for this “mannequin drift” to protect accuracy.
A deep studying mannequin utilizing TensorFlow or facial recognition would possibly expertise information drift because of poor lighting or demographic modifications. These modifications within the enter information could degrade its effectiveness in particular situations or as a perform over time.
Equally, a monetary forecasting mannequin constructed on XGBoost would possibly expertise idea drift as financial indicators change over time. Researchers or builders thus must repeatedly recalibrate the mannequin to make correct predictions below new financial circumstances.
About us: Viso Suite gives enterprise ML groups with 695% ROI on their laptop imaginative and prescient functions. Viso Suite makes it doable to combine laptop imaginative and prescient into current workflows quickly by delivering full-scale administration of your entire software lifecycle. Learn the way Viso Suite can automate your staff’s tasks by reserving a demo.
Understanding Drift in AI Techniques
Addressing the challenges drift poses is paramount in a variety of functions. As an illustration, in autonomous automobiles, correct real-time decision-making is essential below dynamic and difficult circumstances. In healthcare diagnostics, alternatively, affected person outcomes could rely on the reliability of illness prediction fashions. Each functions are additionally topic to steady change together with the evolution of our expertise, understanding, and working circumstances.
Leveraging drift detection frameworks like scikit-multiflow or TensorFlow Mannequin Evaluation allows proactive mannequin administration. This helps guarantee synthetic intelligence methods stay strong, correct, and dependable amidst the dynamic landscapes they function inside.
Idea Drift: Definition and Implications for AI Techniques
Idea drift is when the statistical properties of the goal variable, or the connection between enter and output, change over time. It really works towards the idea of stationary information distributions underlying most predictive fashions. In actual fact, mannequin accuracy could lower because the discovered patterns develop into much less consultant of present information.
The causes of idea drift are numerous and rely on the underlying context of the applying or use case. For instance, evolving buyer behaviors in retail, shifts in monetary markets, or the emergence of latest illness strains.
The impression of idea drift on mannequin efficiency is doubtlessly vital. As highlighted in “A Survey on Idea Drift Adaptation” by Gama et al., fashions like ADWIN (Adaptive Windowing) could dynamically modify to information modifications. This ensures that the predictive mannequin stays correct over time. With out such adaptive mechanisms, fashions can shortly develop into out of date, resulting in poor decision-making and inefficiencies.
The study “Studying below Idea Drift: A Assessment” gives concrete proof of the essential impression of idea drift on the efficiency of machine studying fashions. It finds {that a} mannequin could develop into considerably much less predictive and even out of date if the problem isn’t addressed adequately.
The paper emphasizes the significance of incorporating adaptive studying algorithms and drift detection methods. This consists of methodologies equivalent to on-line studying and ensemble strategies. These methods have been proven to successfully adapt fashions in response to modifications in information distributions.
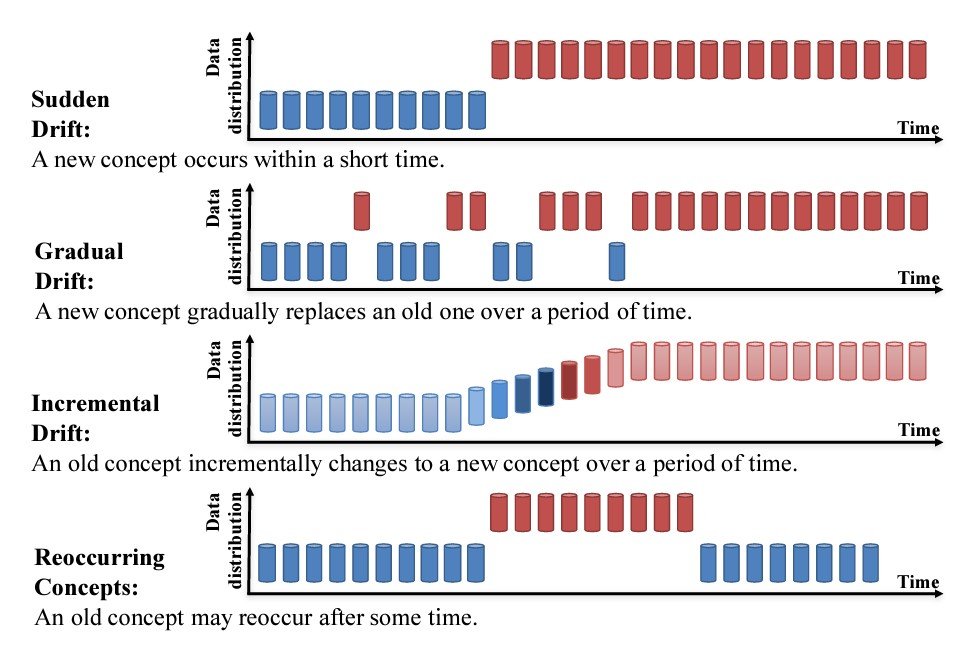
Knowledge Drift: Definition and Implications for AI Techniques
Knowledge drift refers to how modifications within the distribution of enter information over time impression machine studying mannequin efficiency. It could come up from new information sources, information assortment strategies, or modifications within the surroundings or inhabitants. These modifications ultimately impression the predictive capabilities of fashions, rendering them much less correct and even irrelevant.
In laptop imaginative and prescient, for instance, information drift can considerably have an effect on picture recognition fashions. Adjustments in lighting circumstances or variations within the look of objects can result in decreased mannequin accuracy. It’s because the mannequin was skilled on a particular set of knowledge that not represents the surroundings. On this case, information scientists might have to research and replace the information used to coach the mannequin.

The “Matchmaker: Knowledge Drift Mitigation in Machine Studying for Giant-Scale Techniques” study illustrates the impression of knowledge drift in large-scale methods. It reveals how fashions deployed in information facilities skilled accuracy drops of as much as 40% because of information drift.
Detecting and Measuring Drift
Detecting mannequin drift and measuring it’s critical for sustaining accuracy and robustness. Managing drift additionally requires an understanding of its nature and scale.
For idea drift, statistical assessments just like the Drift Detection Technique (DDM), Early Drift Detection Technique (EDDM), and ADaptive WINdowing (ADWIN) are used. These strategies monitor the error charge of a mannequin in a manufacturing surroundings. A major enhance in errors can sign a drift.
ADWIN, as an example, is an adaptive sliding window algorithm that robotically adjusts its dimension to the speed of change detected. This helps stop false positives and accelerates the detection in order that it occurs sooner.
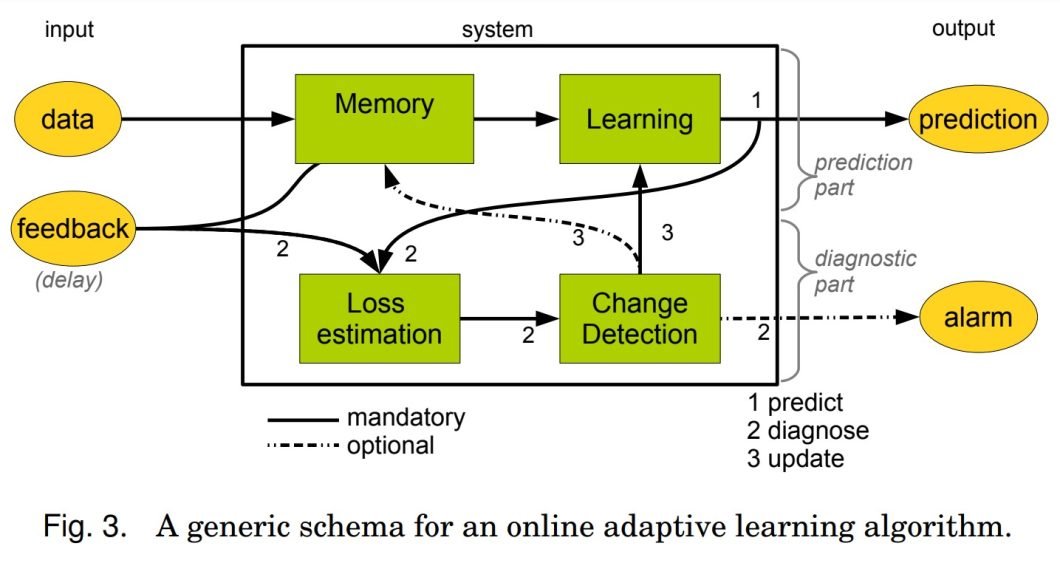
Knowledge drift detection usually entails distribution comparability assessments such because the Kolmogorov-Smirnov take a look at or the Chi-square take a look at. These assessments consider modifications within the distribution of enter options. Equally, a big shift within the significance of options over time could point out information shift.
One other potential resolution is the “Matchmaker” idea. This proposal mitigates information drift by dynamically matching fashions to essentially the most related coaching information batch. Comparable implementations could considerably enhance mannequin accuracy and cut back operational prices in real-world deployments.
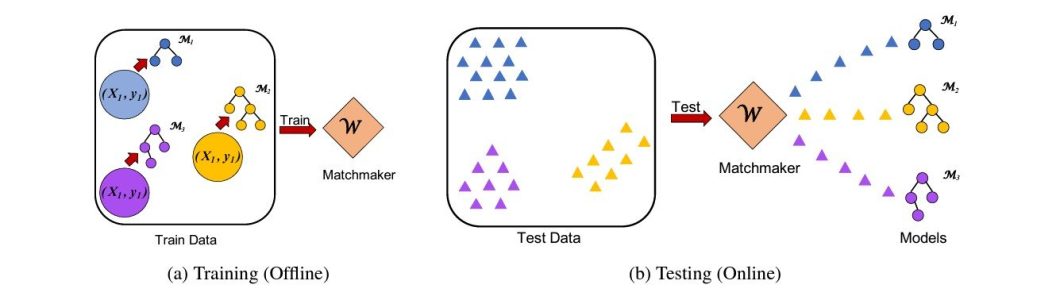
The framework additionally analyzes statistical similarity in efficiency between batches of coaching information and incoming information factors to dynamically choose the best-fitting mannequin.
The study “Routinely Detecting Knowledge Drift in Machine Studying Classifiers” additionally introduces classifier confidence scoring. By specializing in modifications in classifier confidence throughout information units, this method identifies vital deviations from anticipated efficiency. This manner, it might detect the early presence of knowledge drift in order that the mannequin could be recalibrated.
Right now, a number of libraries and platforms are geared up with drift detection capabilities. TensorFlow Mannequin Evaluation presents instruments for evaluating TensorFlow fashions. This consists of monitoring efficiency metrics and detecting potential situations of idea and information drift.
Then again, Scikit-multiflow is a multi-output/multi-label and stream information mining library for Python. It gives instruments and algorithms for information stream processing, which can assist in drift detection.
Efficient drift detection and administration requires a multi-faceted method, together with statistical testing, efficiency monitoring, and using specialised libraries for information stream evaluation.
Reactive vs Proactive Approaches to Managing AI Drift
In relation to drift in AI methods, there are each reactive and proactive methods to mitigate the impression.
Reactive methods wait till mannequin efficiency has degraded earlier than taking motion. This method usually has the good thing about being initially much less resource-intensive however could result in suboptimal efficiency. The mannequin operates with lowered accuracy for a while, so it is probably not appropriate for high-stakes functions.
Nonetheless, one other profit is that it leaves room for extremely focused changes primarily based on the recognized shift. General, this method is good for steady environments the place drift is rare or the place occasional inaccuracies have minimal impression.
Proactive approaches contain common monitoring and updates, aiming to forestall drift from affecting efficiency. As such, they require utilizing extra sources on a extra constant foundation. The benefit is that it detects drift earlier, earlier than a noticeable drop in efficiency.
It additionally helps mitigate the dangers related to poor mannequin predictions in areas like healthcare or autonomous automobiles. This makes it ideally suited for quickly altering environments or the place predictions are essential to security or monetary outcomes.
Nonetheless, there’s additionally the danger of overfitting or unnecessarily frequent updates. So, this method in itself could require cautious tuning and readjusting over time.
How one can Retrain and Replace Fashions to Handle Drift
To adequately tackle drift, builders could must replace or retrain fashions constantly. The choice on when this could occur should stability issues concerning the dimensions of the drift and the criticality of its predictions.
Fashions must be retrained when efficiency metrics point out vital drift, with retraining frequency primarily based on the applying’s criticality.
One other method is to make use of incremental studying. Hereby, the mannequin is just up to date with new information moderately than being retrained from scratch. Platforms like scikit-learn already use this sensible and environment friendly method.
Ensemble Strategies and Mannequin Versioning
The ensemble technique entails combining a number of fashions to enhance the general efficiency in predictive modeling. Aggregating predictions could be finished by way of quite a lot of methods, equivalent to voting or averaging, lowering prediction bias. This enables for a mix of predictions from fashions skilled on numerous information snapshots.
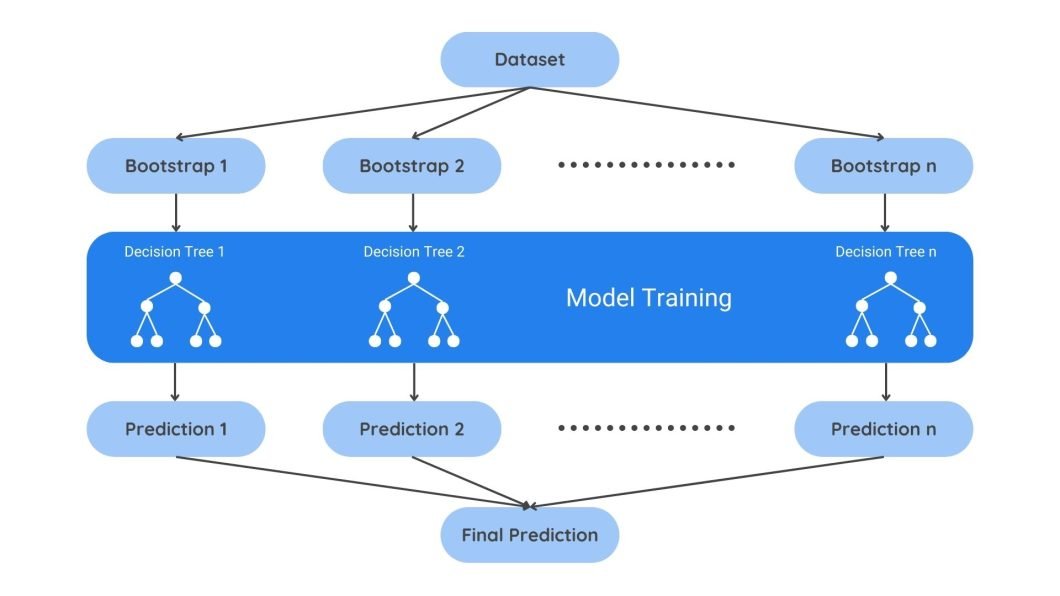
Mannequin versioning is one other essential aspect of drift administration. Versioning ensures that new updates could be tracked and managed. For instance, if recalibration didn’t pan out as anticipated, you possibly can roll again the mannequin to the final acceptable model.
Steady Studying and Adaptive Fashions:
On-line studying repeatedly updates the mannequin as new information turns into accessible. An instance is the incremental batch coaching utilized by TensorFlow or instruments used for inventory value prediction.
Then again, switch studying could assist by adapting the mannequin skilled to do one job to do a associated job. We’ve seen this applied in fashions like BERT for Pure Language Processing (NLP) functions.
We additionally see adaptive studying algorithms being deployed to be used circumstances like spam detection methods. The flexibility to regulate to new information patterns is essential in an space like cybersecurity, the place attackers are repeatedly using new methods.

Finest Practices for AI System Upkeep
Sustaining AI methods and managing the consequences of drift requires a proactive method to make sure the mannequin integrity:
- Often monitor the mannequin’s key efficiency indicators and the soundness of impartial variables to detect early indicators of mannequin drift.
- Use established metrics, such because the Inhabitants Stability Index (PSI) to make sure an correct understanding and response. This will even assist stop overcorrecting.
- Implement rigorous information administration and high quality management throughout the information pipeline to keep up integrity and stop information drift.
- Develop a framework for decision-making that balances the price of mannequin updates towards the potential efficiency decline because of mannequin decay.