
Massive Language Fashions (LLMs) have contributed to advancing the area of pure language processing (NLP), but an current hole persists in contextual understanding. LLMs can generally produce inaccurate or unreliable responses, a phenomenon often known as “hallucinations.”
As an example, with ChatGPT, the incidence of hallucinations is approximated to be round 15% to 20% round 80% of the time.
Retrieval Augmented Era (RAG) is a strong Synthetic Intelligence (AI) framework designed to deal with the context hole by optimizing LLM’s output. RAG leverages the huge exterior data by way of retrievals, enhancing LLMs’ capacity to generate exact, correct, and contextually wealthy responses.
Let’s discover the importance of RAG inside AI techniques, unraveling its potential to revolutionize language understanding and technology.
What’s Retrieval Augmented Era (RAG)?
As a hybrid framework, RAG combines the strengths of generative and retrieval fashions. This mix faucets into third-party data sources to assist inside representations and to generate extra exact and dependable solutions.
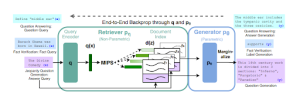
The structure of RAG is distinctive, mixing sequence-to-sequence (seq2seq) fashions with Dense Passage Retrieval (DPR) parts. This fusion empowers the mannequin to generate contextually related responses grounded in correct data.
RAG establishes transparency with a sturdy mechanism for fact-checking and validation to make sure reliability and accuracy.
How Retrieval Augmented Era Works?
In 2020, Meta launched the RAG framework to increase LLMs past their coaching knowledge. Like an open-book examination, RAG permits LLMs to leverage specialised data for extra exact responses by accessing real-world data in response to questions, relatively than relying solely on memorized details.

Unique RAG Mannequin by Meta (Image Source)
This progressive method departs from a data-driven strategy, incorporating knowledge-driven parts, enhancing language fashions’ accuracy, precision, and contextual understanding.
Moreover, RAG capabilities in three steps, enhancing the capabilities of language fashions.

Core Elements of RAG (Image Source)
- Retrieval: Retrieval fashions discover data linked to the person’s immediate to reinforce the language mannequin’s response. This includes matching the person’s enter with related paperwork, guaranteeing entry to correct and present data. Methods like Dense Passage Retrieval (DPR) and cosine similarity contribute to efficient retrieval in RAG and additional refine findings by narrowing it down.
- Augmentation: Following retrieval, the RAG mannequin integrates person question with related retrieved knowledge, using immediate engineering methods like key phrase extraction, and many others. This step successfully communicates the data and context with the LLM, guaranteeing a complete understanding for correct output technology.
- Era: On this section, the augmented data is decoded utilizing an acceptable mannequin, similar to a sequence-to-sequence, to provide the final word response. The technology step ensures the mannequin’s output is coherent, correct, and tailor-made in accordance with the person’s immediate.
What are the Advantages of RAG?
RAG addresses crucial challenges in NLP, similar to mitigating inaccuracies, decreasing reliance on static datasets, and enhancing contextual understanding for extra refined and correct language technology.
RAG’s progressive framework enhances the precision and reliability of generated content material, bettering the effectivity and flexibility of AI techniques.
1. Lowered LLM Hallucinations
By integrating exterior data sources throughout immediate technology, RAG ensures that responses are firmly grounded in correct and contextually related data. Responses may also characteristic citations or references, empowering customers to independently confirm data. This strategy considerably enhances the AI-generated content material’s reliability and diminishes hallucinations.
2. Up-to-date & Correct Responses
RAG mitigates the time cutoff of coaching knowledge or inaccurate content material by constantly retrieving real-time data. Builders can seamlessly combine the newest analysis, statistics, or information instantly into generative fashions. Furthermore, it connects LLMs to reside social media feeds, information websites, and dynamic data sources. This characteristic makes RAG a useful software for purposes demanding real-time and exact data.
3. Price-efficiency
Chatbot growth typically includes using basis fashions which might be API-accessible LLMs with broad coaching. But, retraining these FMs for domain-specific knowledge incurs excessive computational and monetary prices. RAG optimizes useful resource utilization and selectively fetches data as wanted, decreasing pointless computations and enhancing total effectivity. This improves the financial viability of implementing RAG and contributes to the sustainability of AI techniques.
4. Synthesized Data
RAG creates complete and related responses by seamlessly mixing retrieved data with generative capabilities. This synthesis of various data sources enhances the depth of the mannequin’s understanding, providing extra correct outputs.
5. Ease of Coaching
RAG’s user-friendly nature is manifested in its ease of coaching. Builders can fine-tune the mannequin effortlessly, adapting it to particular domains or purposes. This simplicity in coaching facilitates the seamless integration of RAG into numerous AI techniques, making it a flexible and accessible answer for advancing language understanding and technology.
RAG’s capacity to resolve LLM hallucinations and knowledge freshness issues makes it a vital software for companies seeking to improve the accuracy and reliability of their AI techniques.
Use Circumstances of RAG
RAG‘s adaptability provides transformative options with real-world impression, from data engines to enhancing search capabilities.
1. Data Engine
RAG can remodel conventional language fashions into complete data engines for up-to-date and genuine content material creation. It’s particularly invaluable in situations the place the newest data is required, similar to in instructional platforms, analysis environments, or information-intensive industries.
2. Search Augmentation
By integrating LLMs with engines like google, enriching search outcomes with LLM-generated replies improves the accuracy of responses to informational queries. This enhances the person expertise and streamlines workflows, making it simpler to entry the required data for his or her duties..
3. Textual content Summarization
RAG can generate concise and informative summaries of enormous volumes of textual content. Furthermore, RAG saves customers effort and time by enabling the event of exact and thorough text summaries by acquiring related knowledge from third-party sources.
4. Query & Reply Chatbots
Integrating LLMs into chatbots transforms follow-up processes by enabling the automated extraction of exact data from firm paperwork and data bases. This elevates the effectivity of chatbots in resolving buyer queries precisely and promptly.
Future Prospects and Improvements in RAG
With an growing concentrate on personalised responses, real-time data synthesis, and decreased dependency on fixed retraining, RAG guarantees revolutionary developments in language fashions to facilitate dynamic and contextually conscious AI interactions.
As RAG matures, its seamless integration into various purposes with heightened accuracy provides customers a refined and dependable interplay expertise.
Go to Unite.ai for higher insights into AI improvements and know-how.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Your article helped me a lot, is there any more related content? Thanks!
Your article helped me a lot, is there any more related content? Thanks!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.